管理集群
- 1: 从 dockershim 迁移
- 1.1: 检查弃用 Dockershim 对你的影响
- 1.2: 从 dockershim 迁移遥测和安全代理
- 2: 用 kubeadm 进行管理
- 2.1: 使用 kubeadm 进行证书管理
- 2.2: 配置 cgroup 驱动
- 2.3: 升级 kubeadm 集群
- 2.4: 添加 Windows 节点
- 2.5: 升级 Windows 节点
- 3: 管理内存,CPU 和 API 资源
- 3.1: 为命名空间配置默认的内存请求和限制
- 3.2: 为命名空间配置默认的 CPU 请求和限制
- 3.3: 配置命名空间的最小和最大内存约束
- 3.4: 为命名空间配置 CPU 最小和最大约束
- 3.5: 为命名空间配置内存和 CPU 配额
- 3.6: 配置命名空间下 Pod 配额
- 4: 证书
- 5: 安装网络规则驱动
- 5.1: Use Antrea for NetworkPolicy
- 5.2: 使用 Calico 提供 NetworkPolicy
- 5.3: 使用 Cilium 提供 NetworkPolicy
- 5.4: 使用 kube-router 提供 NetworkPolicy
- 5.5: 使用 Romana 提供 NetworkPolicy
- 5.6: 使用 Weave Net 提供 NetworkPolicy
- 6: IP Masquerade Agent 用户指南
- 7: Kubernetes 云管理控制器
- 8: 为 Kubernetes 运行 etcd 集群
- 9: 为系统守护进程预留计算资源
- 10: 为节点发布扩展资源
- 11: 以非root用户身份运行 Kubernetes 节点组件
- 12: 使用 CoreDNS 进行服务发现
- 13: 使用 KMS 驱动进行数据加密
- 14: 使用 Kubernetes API 访问集群
- 15: 保护集群安全
- 16: 关键插件 Pod 的调度保证
- 17: 升级集群
- 18: 名字空间演练
- 19: 启用/禁用 Kubernetes API
- 20: 启用拓扑感知提示
- 21: 在 Kubernetes 集群中使用 NodeLocal DNSCache
- 22: 在 Kubernetes 集群中使用 sysctl
- 23: 在运行中的集群上重新配置节点的 kubelet
- 24: 声明网络策略
- 25: 安全地清空一个节点
- 26: 将重复的控制平面迁至云控制器管理器
- 27: 开发云控制器管理器
- 28: 开启服务拓扑
- 29: 控制节点上的 CPU 管理策略
- 30: 控制节点上的拓扑管理策略
- 31: 搭建高可用的 Kubernetes Masters
- 32: 改变默认 StorageClass
- 33: 更改 PersistentVolume 的回收策略
- 34: 自动扩缩集群 DNS 服务
- 35: 自定义 DNS 服务
- 36: 访问集群上运行的服务
- 37: 调试 DNS 问题
- 38: 通过名字空间共享集群
- 39: 通过配置文件设置 Kubelet 参数
- 40: 配置 API 对象配额
- 41: 配置资源不足时的处理方式
- 42: 限制存储消耗
- 43: 静态加密 Secret 数据
1 - 从 dockershim 迁移
本节提供从 dockershim 迁移到其他容器运行时的必备知识。
自从 Kubernetes 1.20 宣布 弃用 dockershim, 各类疑问随之而来:这对各类工作负载和 Kubernetes 部署会产生什么影响。 你会发现这篇博文对于更好地理解此问题非常有用: 弃用 Dockershim 常见问题
建议从 dockershim 迁移到其他替代的容器运行时。 请参阅容器运行时 一节以了解可用的备选项。 当在迁移过程中遇到麻烦,请上报问题。 那么问题就可以及时修复,你的集群也可以进入移除 dockershim 前的就绪状态。
1.1 - 检查弃用 Dockershim 对你的影响
Kubernetes 的 dockershim 组件使得你可以把 Docker 用作 Kubernetes 的
容器运行时。
在 Kubernetes v1.20 版本中,内建组件 dockershim 被弃用。
本页讲解你的集群把 Docker 用作容器运行时的运作机制,
并提供使用 dockershim 时,它所扮演角色的详细信息,
继而展示了一组验证步骤,可用来检查弃用 dockershim 对你的工作负载的影响。
检查你的应用是否依赖于 Docker
虽然你通过 Docker 创建了应用容器,但这些容器却可以运行于所有容器运行时。 所以这种使用 Docker 容器运行时的方式并不构成对 Docker 的依赖。
当用了替代的容器运行时之后,Docker 命令可能不工作,甚至产生意外的输出。 这才是判定你是否依赖于 Docker 的方法。
- 确认没有特权 Pod 执行 docker 命令。
- 检查 Kubernetes 基础架构外部节点上的脚本和应用,确认它们没有执行 Docker 命令。可能的命令有:
- SSH 到节点排查故障;
- 节点启动脚本;
- 直接安装在节点上的监视和安全代理。
- 检查执行了上述特权操作的第三方工具。详细操作请参考: 从 dockershim 迁移遥测和安全代理
- 确认没有对 dockershim 行为的间接依赖。这是一种极端情况,不太可能影响你的应用。 一些工具很可能被配置为使用了 Docker 特性,比如,基于特定指标发警报,或者在故障排查指令的一个环节中搜索特定的日志信息。 如果你有此类配置的工具,需要在迁移之前,在测试集群上完成功能验证。
Docker 依赖详解
容器运行时是一个软件,用来运行组成 Kubernetes Pod 的容器。 Kubernetes 负责编排和调度 Pod;在每一个节点上, kubelet 使用抽象的容器运行时接口,所以你可以任意选用兼容的容器运行时。
在早期版本中,Kubernetes 提供的兼容性支持一个容器运行时:Docker。
在 Kubernetes 发展历史中,集群运营人员希望采用更多的容器运行时。
于是 CRI 被设计出来满足这类灵活性需要 - 而 kubelet 亦开始支持 CRI。
然而,因为 Docker 在 CRI 规范创建之前就已经存在,Kubernetes 就创建了一个适配器组件:dockershim。
dockershim 适配器允许 kubelet 与 Docker交互,就好像 Docker 是一个 CRI 兼容的运行时一样。
你可以阅读博文 Kubernetes 容器集成功能的正式发布
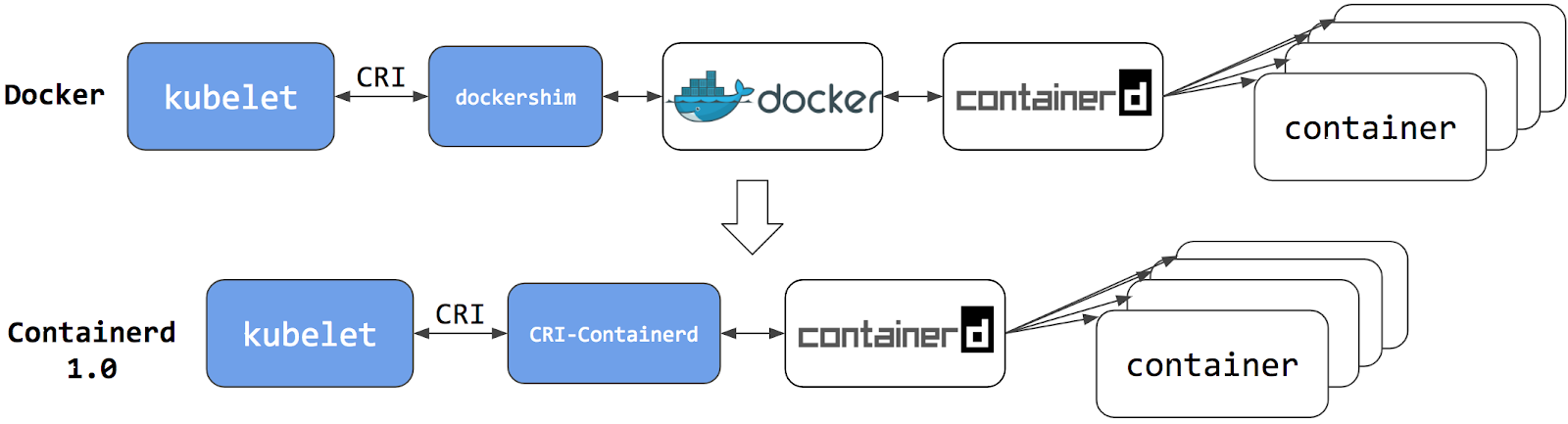
切换到容器运行时 Containerd 可以消除掉中间环节。 所有以前遗留的容器可由 Containerd 这类容器运行时来运行和管理,操作体验也和以前一样。 但是现在,由于直接用容器运行时调度容器,所以它们对 Docker 来说是不可见的。 因此,你以前用来检查这些容器的 Docker 工具或漂亮的 UI 都不再可用。
你不能再使用 docker ps 或 docker inspect 命令来获取容器信息。
由于你不能列出容器,因此你不能获取日志、停止容器,甚至不能通过 docker exec 在容器中执行命令。
你仍然可以下载镜像,或者用 docker build 命令创建它们。
但用 Docker 创建、下载的镜像,对于容器运行时和 Kubernetes,均不可见。
为了在 Kubernetes 中使用,需要把镜像推送(push)到某注册中心。
1.2 - 从 dockershim 迁移遥测和安全代理
在 Kubernetes 1.20 版本中,dockershim 被弃用。 在博文弃用 Dockershim 常见问题中, 你大概已经了解到,大多数应用并没有直接通过运行时来托管容器。 但是,仍然有大量的遥测和安全代理依赖 docker 来收集容器元数据、日志和指标。 本文汇总了一些信息和链接:信息用于阐述如何探查这些依赖,链接用于解释如何迁移这些代理去使用通用的工具或其他容器运行。
遥测和安全代理
为了让代理运行在 Kubernetes 集群中,我们有几种办法。 代理既可以直接在节点上运行,也可以作为守护进程运行。
为什么遥测代理依赖于 Docker?
因为历史原因,Kubernetes 建立在 Docker 之上。 Kubernetes 管理网络和调度,Docker 则在具体的节点上定位并操作容器。 所以,你可以从 Kubernetes 取得调度相关的元数据,比如 Pod 名称;从 Docker 取得容器状态信息。 后来,人们开发了更多的运行时来管理容器。 同时一些项目和 Kubernetes 特性也不断涌现,支持跨多个运行时收集容器状态信息。
一些代理和 Docker 工具紧密绑定。此类代理可以这样运行命令,比如用
docker ps
或 docker top
这类命令来列出容器和进程,用
docker logs
订阅 Docker 的日志。
但随着 Docker 作为容器运行时被弃用,这些命令将不再工作。
识别依赖于 Docker 的 DaemonSet
如果某 Pod 想调用运行在节点上的 dockerd,该 Pod 必须满足以下两个条件之一:
- 将包含 Docker 守护进程特权套接字的文件系统挂载为一个卷;或
- 直接以卷的形式挂载 Docker 守护进程特权套接字的特定路径。
举例来说:在 COS 镜像中,Docker 通过 /var/run/docker.sock 开放其 Unix 域套接字。
这意味着 Pod 的规约中需要包含 hostPath 卷以挂载 /var/run/docker.sock。
下面是一个 shell 示例脚本,用于查找包含直接映射 Docker 套接字的挂载点的 Pod。
你也可以删掉 grep /var/run/docker.sock 这一代码片段以查看其它挂载信息。
kubectl get pods --all-namespaces \
-o=jsonpath='{range .items[*]}{"\n"}{.metadata.namespace}{":\t"}{.metadata.name}{":\t"}{range .spec.volumes[*]}{.hostPath.path}{", "}{end}{end}' \
| sort \
| grep '/var/run/docker.sock'
/var/run 的父目录而非其完整路径
(就像这个例子)。
上述脚本只检测最常见的使用方式。
检测节点代理对 Docker 的依赖性
在你的集群节点被定制、且在各个节点上均安装了额外的安全和遥测代理的场景下, 一定要和代理的供应商确认:该代理是否依赖于 Docker。
遥测和安全代理的供应商
我们通过 谷歌文档 提供了为各类遥测和安全代理供应商准备的持续更新的迁移指导。 请与供应商联系,获取从 dockershim 迁移的最新说明。
2 - 用 kubeadm 进行管理
2.1 - 使用 kubeadm 进行证书管理
Kubernetes v1.15 [stable]
由 kubeadm 生成的客户端证书在 1 年后到期。 本页说明如何使用 kubeadm 管理证书续订。
准备开始
你应该熟悉 Kubernetes 中的 PKI 证书和要求。
使用自定义的证书
默认情况下, kubeadm 会生成运行一个集群所需的全部证书。 你可以通过提供你自己的证书来改变这个行为策略。
如果要这样做, 你必须将证书文件放置在通过 --cert-dir 命令行参数或者 kubeadm 配置中的
CertificatesDir 配置项指明的目录中。默认的值是 /etc/kubernetes/pki。
如果在运行 kubeadm init 之前存在给定的证书和私钥对,kubeadm 将不会重写它们。
例如,这意味着您可以将现有的 CA 复制到 /etc/kubernetes/pki/ca.crt 和
/etc/kubernetes/pki/ca.key 中,而 kubeadm 将使用此 CA 对其余证书进行签名。
外部 CA 模式
只提供了 ca.crt 文件但是不提供 ca.key 文件也是可以的
(这只对 CA 根证书可用,其它证书不可用)。
如果所有的其它证书和 kubeconfig 文件已就绪,kubeadm 检测到满足以上条件就会激活
"外部 CA" 模式。kubeadm 将会在没有 CA 密钥文件的情况下继续执行。
否则, kubeadm 将独立运行 controller-manager,附加一个
--controllers=csrsigner 的参数,并且指明 CA 证书和密钥。
PKI 证书和要求包括集群使用外部 CA 的设置指南。
检查证书是否过期
你可以使用 check-expiration 子命令来检查证书何时过期
kubeadm certs check-expiration
输出类似于以下内容:
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 30, 2020 23:36 UTC 364d no
apiserver Dec 30, 2020 23:36 UTC 364d ca no
apiserver-etcd-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 30, 2020 23:36 UTC 364d ca no
controller-manager.conf Dec 30, 2020 23:36 UTC 364d no
etcd-healthcheck-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-peer Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-server Dec 30, 2020 23:36 UTC 364d etcd-ca no
front-proxy-client Dec 30, 2020 23:36 UTC 364d front-proxy-ca no
scheduler.conf Dec 30, 2020 23:36 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 28, 2029 23:36 UTC 9y no
etcd-ca Dec 28, 2029 23:36 UTC 9y no
front-proxy-ca Dec 28, 2029 23:36 UTC 9y no
该命令显示 /etc/kubernetes/pki 文件夹中的客户端证书以及
kubeadm(admin.conf, controller-manager.conf 和 scheduler.conf)
使用的 KUBECONFIG 文件中嵌入的客户端证书的到期时间/剩余时间。
另外, kubeadm 会通知用户证书是否由外部管理; 在这种情况下,用户应该小心的手动/使用其他工具来管理证书更新。
kubeadm 不能管理由外部 CA 签名的证书
kubelet.conf,因为 kubeadm 将 kubelet 配置为
自动更新证书。
轮换的证书位于目录 /var/lib/kubelet/pki。
要修复过期的 kubelet 客户端证书,请参阅
kubelet 客户端证书轮换失败。
在通过 kubeadm init 创建的节点上,在 kubeadm 1.17 版本之前有一个
缺陷,该缺陷
使得你必须手动修改 kubelet.conf 文件的内容。
kubeadm init 操作结束之后,你必须更新 kubelet.conf 文件
将 client-certificate-data 和 client-key-data 改为如下所示的内容
以便使用轮换后的 kubelet 客户端证书:
client-certificate: /var/lib/kubelet/pki/kubelet-client-current.pem
client-key: /var/lib/kubelet/pki/kubelet-client-current.pem
自动更新证书
kubeadm 会在控制面
升级
的时候更新所有证书。
这个功能旨在解决最简单的用例;如果你对此类证书的更新没有特殊要求, 并且定期执行 Kubernetes 版本升级(每次升级之间的间隔时间少于 1 年), 则 kubeadm 将确保你的集群保持最新状态并保持合理的安全性。
如果你对证书更新有更复杂的需求,则可通过将 --certificate-renewal=false 传递给
kubeadm upgrade apply 或者 kubeadm upgrade node,从而选择不采用默认行为。
kubeadm update node 执行时 --certificate-renewal 的默认值被设置为 false。
在这种情况下,你需要显式地设置 --certificate-renewal=true。
手动更新证书
你能随时通过 kubeadm certs renew 命令手动更新你的证书。
此命令用 CA (或者 front-proxy-CA )证书和存储在 /etc/kubernetes/pki 中的密钥执行更新。
执行完此命令之后你需要重启控制面 Pods。因为动态证书重载目前还不被所有组件和证书支持,所有这项操作是必须的。
静态 Pods 是被本地 kubelet 而不是 API Server 管理,
所以 kubectl 不能用来删除或重启他们。
要重启静态 Pod 你可以临时将清单文件从 /etc/kubernetes/manifests/ 移除并等待 20 秒
(参考 KubeletConfiguration 结构 中的fileCheckFrequency 值)。
如果 Pod 不在清单目录里,kubelet将会终止它。
在另一个 fileCheckFrequency 周期之后你可以将文件移回去,为了组件可以完成 kubelet 将重新创建 Pod 和证书更新。
certs renew 使用现有的证书作为属性 (Common Name、Organization、SAN 等) 的权威来源,
而不是 kubeadm-config ConfigMap 。强烈建议使它们保持同步。
kubeadm certs renew提供以下选项:
Kubernetes 证书通常在一年后到期。
--csr-only可用于经过一个外部 CA 生成的证书签名请求来更新证书(无需实际替换更新证书); 更多信息请参见下节。- 可以更新单个证书而不是全部证书。
用 Kubernetes 证书 API 更新证书
本节提供有关如何使用 Kubernetes 证书 API 执行手动证书更新的更多详细信息。
设置一个签名者(Signer)
Kubernetes 证书颁发机构不是开箱即用。
你可以配置外部签名者,例如
cert-manager,
也可以使用内置签名者。
内置签名者是
kube-controller-manager
的一部分。
要激活内置签名者,请传递 --cluster-signing-cert-file 和 --cluster-signing-key-file 参数。
如果你正在创建一个新的集群,你可以使用 kubeadm 的 配置文件。
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
controllerManager:
extraArgs:
cluster-signing-cert-file: /etc/kubernetes/pki/ca.crt
cluster-signing-key-file: /etc/kubernetes/pki/ca.key
创建证书签名请求 (CSR)
有关使用 Kubernetes API 创建 CSR 的信息, 请参见创建 CertificateSigningRequest。
通过外部 CA 更新证书
本节提供有关如何使用外部 CA 执行手动更新证书的更多详细信息。
为了更好的与外部 CA 集成,kubeadm 还可以生成证书签名请求(CSR)。 CSR 表示向 CA 请求客户的签名证书。 在 kubeadm 术语中,通常由磁盘 CA 签名的任何证书都可以作为 CSR 生成。但是,CA 不能作为 CSR 生成。
创建证书签名请求 (CSR)
你可以通过 kubeadm certs renew --csr-only 命令创建证书签名请求。
CSR 和随附的私钥都在输出中给出。
你可以传入一个带有 --csr-dir 的目录,将 CRS 输出到指定位置。
如果未指定 --csr-dir ,则使用默认证书目录(/etc/kubernetes/pki)。
证书可以通过 kubeadm certs renew --csr-only 来续订。
和 kubeadm init 一样,可以使用 --csr-dir 标志指定一个输出目录。
CSR 签署证书后,必须将证书和私钥复制到 PKI 目录(默认情况下为 /etc/kubernetes/pki)。
CSR 中包含一个证书的名字,域和 IP,但是未指定用法。 颁发证书时,CA 有责任指定正确的证书用法
- 在
openssl中,这是通过openssl ca命令 来完成的。 - 在
cfssl中,这是通过 在配置文件中指定用法 来完成的。
使用首选方法对证书签名后,必须将证书和私钥复制到 PKI 目录(默认为 /etc/kubernetes/pki )。
证书机构(CA)轮换
kubeadm 并不直接支持对 CA 证书的轮换或者替换。
关于手动轮换或者置换 CA 的更多信息,可参阅 手动轮换 CA 证书。
启用已签名的 kubelet 服务证书
默认情况下,kubeadm 所部署的 kubelet 服务证书是自签名(Self-Signed))。 这意味着从 metrics-server 这类外部服务发起向 kubelet 的链接时无法使用 TLS 来完成保护。
要在新的 kubeadm 集群中配置 kubelet 以使用被正确签名的服务证书,
你必须向 kubeadm init 传递如下最小配置数据:
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
serverTLSBootstrap: true
如果你已经创建了集群,你必须通过执行下面的操作来完成适配:
- 找到
kube-system名字空间中名为kubelet-config-1.23的 ConfigMap 并编辑之。 在该 ConfigMap 中,kubelet键下面有一个 KubeletConfiguration 文档作为其取值。编辑该 KubeletConfiguration 文档以设置serverTLSBootstrap: true。 - 在每个节点上,在
/var/lib/kubelet/config.yaml文件中添加serverTLSBootstrap: true字段,并使用systemctl restart kubelet来重启 kubelet。
字段 serverTLSBootstrap 将允许启动引导 kubelet 的服务证书,方式
是从 certificates.k8s.io API 处读取。这种方式的一种局限在于这些
证书的 CSR(证书签名请求)不能被 kube-controller-manager 中默认的
签名组件
kubernetes.io/kubelet-serving
批准。需要用户或者第三方控制器来执行此操作。
可以使用下面的命令来查看 CSR:
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-9wvgt 112s kubernetes.io/kubelet-serving system:node:worker-1 Pending
csr-lz97v 1m58s kubernetes.io/kubelet-serving system:node:control-plane-1 Pending
你可以执行下面的操作来批准这些请求:
kubectl certificate approve <CSR-名称>
默认情况下,这些服务证书上会在一年后过期。
kubeadm 将 KubeletConfiguration 的 rotateCertificates 字段设置为
true;这意味着证书快要过期时,会生成一组针对服务证书的新的 CSR,而
这些 CSR 也要被批准才能完成证书轮换。
要进一步了解这里的细节,可参阅
证书轮换
文档。
如果你在寻找一种能够自动批准这些 CSR 的解决方案,建议你与你的云提供商 联系,询问他们是否有 CSR 签名组件,用来以带外(out-of-band)的方式检查 节点的标识符。
也可以使用第三方定制的控制器:
除非既能够验证 CSR 中的 CommonName,也能检查请求的 IP 和域名, 这类控制器还算不得安全的机制。 只有完成彻底的检查,才有可能避免有恶意的、能够访问 kubelet 客户端证书的第三方 为任何 IP 或域名请求服务证书。
2.2 - 配置 cgroup 驱动
本页阐述如何配置 kubelet 的 cgroup 驱动以匹配 kubeadm 集群中的容器运行时的 cgroup 驱动。
准备开始
你应该熟悉 Kubernetes 的容器运行时需求。
配置容器运行时 cgroup 驱动
容器运行时页面提到:
由于 kubeadm 把 kubelet 视为一个系统服务来管理,所以对基于 kubeadm 的安装,
我们推荐使用 systemd 驱动,不推荐 cgroupfs 驱动。
此页还详述了如何安装若干不同的容器运行时,并将 systemd 设为其默认驱动。
配置 kubelet 的 cgroup 驱动
kubeadm 支持在执行 kubeadm init 时,传递一个 KubeletConfiguration 结构体。
KubeletConfiguration 包含 cgroupDriver 字段,可用于控制 kubelet 的 cgroup 驱动。
KubeletConfiguration 中设置 cgroupDriver 字段,
kubeadm init 会将它设置为默认值 systemd。
这是一个最小化的示例,其中显式的配置了此字段:
# kubeadm-config.yaml
kind: ClusterConfiguration
apiVersion: kubeadm.k8s.io/v1beta3
kubernetesVersion: v1.21.0
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
这样一个配置文件就可以传递给 kubeadm 命令了:
kubeadm init --config kubeadm-config.yaml
Kubeadm 对集群所有的节点,使用相同的 KubeletConfiguration。
KubeletConfiguration 存放于 kube-system 命名空间下的某个
ConfigMap 对象中。
执行 init、join 和 upgrade 等子命令会促使 kubeadm
将 KubeletConfiguration 写入到文件 /var/lib/kubelet/config.yaml 中,
继而把它传递给本地节点的 kubelet。
使用 cgroupfs 驱动
正如本指南阐述的:不推荐与 kubeadm 一起使用 cgroupfs 驱动。
如仍需使用 cgroupfs,
且要防止 kubeadm upgrade 修改现有系统中 KubeletConfiguration 的 cgroup 驱动,
你必须显式声明它的值。
此方法应对的场景为:在将来某个版本的 kubeadm 中,你不想使用默认的 systemd 驱动。
参阅以下章节“修改 kubelet 的 ConfigMap”,了解显式设置该值的方法。
如果你希望配置容器运行时来使用 cgroupfs 驱动,
则必须参考所选容器运行时的文档。
迁移到 systemd 驱动
要将现有 kubeadm 集群的 cgroup 驱动就地升级为 systemd,
需要执行一个与 kubelet 升级类似的过程。
该过程必须包含下面两个步骤:
systemd 的新节点替换掉集群中的老节点。
按这种方法,在加入新节点、确保工作负载可以安全迁移到新节点、及至删除旧节点这一系列操作之前,
只需执行以下第一个步骤。
修改 kubelet 的 ConfigMap
-
用命令
kubectl get cm -n kube-system | grep kubelet-config找到 kubelet 的 ConfigMap 名称。 -
运行
kubectl edit cm kubelet-config-x.yy -n kube-system(把x.yy替换为 Kubernetes 版本)。 -
修改现有
cgroupDriver的值,或者新增如下式样的字段:cgroupDriver: systemd该字段必须出现在 ConfigMap 的
kubelet:小节下。
更新所有节点的 cgroup 驱动
对于集群中的每一个节点:
- 执行命令
kubectl drain <node-name> --ignore-daemonsets,以 腾空节点 - 执行命令
systemctl stop kubelet,以停止 kubelet - 停止容器运行时
- 修改容器运行时 cgroup 驱动为
systemd - 在文件
/var/lib/kubelet/config.yaml中添加设置cgroupDriver: systemd - 启动容器运行时
- 执行命令
systemctl start kubelet,以启动 kubelet - 执行命令
kubectl uncordon <node-name>,以 取消节点隔离
在节点上依次执行上述步骤,确保工作负载有充足的时间被调度到其他节点。
流程完成后,确认所有节点和工作负载均健康如常。
2.3 - 升级 kubeadm 集群
本页介绍如何将 kubeadm 创建的 Kubernetes 集群从 1.22.x 版本
升级到 1.23.x 版本以及从 1.23.x
升级到 1.23.y(其中 y > x)。略过次版本号的升级是
不被支持的。
要查看 kubeadm 创建的有关旧版本集群升级的信息,请参考以下页面:
- 将 kubeadm 集群从 1.21 升级到 1.22
- 将 kubeadm 集群从 1.20 升级到 1.21
- 将 kubeadm 集群从 1.19 升级到 1.20
- 将 kubeadm 集群从 1.18 升级到 1.19
升级工作的基本流程如下:
- 升级主控制平面节点
- 升级其他控制平面节点
- 升级工作节点
准备开始
- 务必仔细认真阅读发行说明。
- 集群应使用静态的控制平面和 etcd Pod 或者外部 etcd。
- 务必备份所有重要组件,例如存储在数据库中应用层面的状态。
kubeadm upgrade不会影响你的工作负载,只会涉及 Kubernetes 内部的组件,但备份终究是好的。 - 必须禁用交换分区。
附加信息
- 在对 kubelet 作次版本升版时需要腾空节点。 对于控制面节点,其上可能运行着 CoreDNS Pods 或者其它非常重要的负载。
- 升级后,因为容器规约的哈希值已更改,所有容器都会被重新启动。
确定要升级到哪个版本
使用操作系统的包管理器找到最新的补丁版本 Kubernetes 1.23:
apt update
apt-cache madison kubeadm
# 在列表中查找最新的 1.23 版本
# 它看起来应该是 1.23.x-00,其中 x 是最新的补丁版本
yum list --showduplicates kubeadm --disableexcludes=kubernetes
# 在列表中查找最新的 1.23 版本
# 它看起来应该是 1.23.x-0,其中 x 是最新的补丁版本
升级控制平面节点
控制面节点上的升级过程应该每次处理一个节点。
首先选择一个要先行升级的控制面节点。该节点上必须拥有
/etc/kubernetes/admin.conf 文件。
执行 "kubeadm upgrade"
升级第一个控制面节点
- 升级 kubeadm:
# 用最新的补丁版本号替换 1.23.x-00 中的 x
apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm=1.23.x-00 && \
apt-mark hold kubeadm
-
# 从 apt-get 1.1 版本起,你也可以使用下面的方法
apt-get update && \
apt-get install -y --allow-change-held-packages kubeadm=1.23.x-00
# 用最新的补丁版本号替换 1.23.x-0 中的 x
yum install -y kubeadm-1.23.x-0 --disableexcludes=kubernetes
-
验证下载操作正常,并且 kubeadm 版本正确:
kubeadm version
-
验证升级计划:
kubeadm upgrade plan此命令检查你的集群是否可被升级,并取回你要升级的目标版本。 命令也会显示一个包含组件配置版本状态的表格。
说明:kubeadm upgrade也会自动对 kubeadm 在节点上所管理的证书执行续约操作。 如果需要略过证书续约操作,可以使用标志--certificate-renewal=false。 更多的信息,可参阅证书管理指南。说明:如果
kubeadm upgrade plan给出任何需要手动升级的组件配置,用户必须 通过--config命令行标志向kubeadm upgrade apply命令提供替代的配置文件。 如果不这样做,kubeadm upgrade apply会出错并退出,不再执行升级操作。
选择要升级到的目标版本,运行合适的命令。例如:
# 将 x 替换为你为此次升级所选择的补丁版本号
sudo kubeadm upgrade apply v1.23.x
一旦该命令结束,你应该会看到:
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.23.x". Enjoy!
[upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.
-
手动升级你的 CNI 驱动插件。
你的容器网络接口(CNI)驱动应该提供了程序自身的升级说明。 参阅插件页面查找你的 CNI 驱动, 并查看是否需要其他升级步骤。
如果 CNI 驱动作为 DaemonSet 运行,则在其他控制平面节点上不需要此步骤。
对于其它控制面节点
与第一个控制面节点相同,但是使用:
sudo kubeadm upgrade node
而不是:
sudo kubeadm upgrade apply
此外,不需要执行 kubeadm upgrade plan 和更新 CNI 驱动插件的操作。
腾空节点
-
通过将节点标记为不可调度并腾空节点为节点作升级准备:
# 将 <node-to-drain> 替换为你要腾空的控制面节点名称 kubectl drain <node-to-drain> --ignore-daemonsets
升级 kubelet 和 kubectl
-
升级 kubelet 和 kubectl
# 用最新的补丁版本替换 1.23.x-00 中的 x apt-mark unhold kubelet kubectl && \ apt-get update && apt-get install -y kubelet=1.23.x-00 kubectl=1.23.x-00 && \ apt-mark hold kubelet kubectl - # 从 apt-get 的 1.1 版本开始,你也可以使用下面的方法: apt-get update && \ apt-get install -y --allow-change-held-packages kubelet=1.23.x-00 kubectl=1.23.x-00
# 用最新的补丁版本号替换 1.23.x-00 中的 x yum install -y kubelet-1.23.x-0 kubectl-1.23.x-0 --disableexcludes=kubernetes
-
重启 kubelet
sudo systemctl daemon-reload sudo systemctl restart kubelet
解除节点的保护
-
通过将节点标记为可调度,让其重新上线:
# 将 <node-to-drain> 替换为你的节点名称 kubectl uncordon <node-to-drain>
升级工作节点
工作节点上的升级过程应该一次执行一个节点,或者一次执行几个节点, 以不影响运行工作负载所需的最小容量。
升级 kubeadm
-
升级 kubeadm:
# 将 1.23.x-00 中的 x 替换为最新的补丁版本号 apt-mark unhold kubeadm && \ apt-get update && apt-get install -y kubeadm=1.23.x-00 && \ apt-mark hold kubeadm - # 从 apt-get 的 1.1 版本开始,你也可以使用下面的方法: apt-get update && \ apt-get install -y --allow-change-held-packages kubeadm=1.23.x-00# 用最新的补丁版本替换 1.23.x-00 中的 x yum install -y kubeadm-1.23.x-0 --disableexcludes=kubernetes
执行 "kubeadm upgrade"
-
对于工作节点,下面的命令会升级本地的 kubelet 配置:
sudo kubeadm upgrade node
腾空节点
-
将节点标记为不可调度并驱逐所有负载,准备节点的维护:
# 将 <node-to-drain> 替换为你正在腾空的节点的名称 kubectl drain <node-to-drain> --ignore-daemonsets
升级 kubelet 和 kubectl
-
升级 kubelet 和 kubectl:
# 将 1.23.x-00 中的 x 替换为最新的补丁版本 apt-mark unhold kubelet kubectl && \ apt-get update && apt-get install -y kubelet=1.23.x-00 kubectl=1.23.x-00 && \ apt-mark hold kubelet kubectl # 从 apt-get 的 1.1 版本开始,你也可以使用下面的方法: apt-get update && \ apt-get install -y --allow-change-held-packages kubelet=1.23.x-00 kubectl=1.23.x-00# 将 1.23.x-0 x 替换为最新的补丁版本 yum install -y kubelet-1.23.x-0 kubectl-1.23.x-0 --disableexcludes=kubernetes
-
重启 kubelet
sudo systemctl daemon-reload sudo systemctl restart kubelet
取消对节点的保护
-
通过将节点标记为可调度,让节点重新上线:
# 将 <node-to-drain> 替换为当前节点的名称 kubectl uncordon <node-to-drain>
验证集群的状态
在所有节点上升级 kubelet 后,通过从 kubectl 可以访问集群的任何位置运行以下命令, 验证所有节点是否再次可用:
kubectl get nodes
STATUS 应显示所有节点为 Ready 状态,并且版本号已经被更新。
从故障状态恢复
如果 kubeadm upgrade 失败并且没有回滚,例如由于执行期间节点意外关闭,
你可以再次运行 kubeadm upgrade。
此命令是幂等的,并最终确保实际状态是你声明的期望状态。
要从故障状态恢复,你还可以运行 kubeadm upgrade --force 而无需更改集群正在运行的版本。
在升级期间,kubeadm 向 /etc/kubernetes/tmp 目录下的如下备份文件夹写入数据:
kubeadm-backup-etcd-<date>-<time>kubeadm-backup-manifests-<date>-<time>
kubeadm-backup-etcd 包含当前控制面节点本地 etcd 成员数据的备份。
如果 etcd 升级失败并且自动回滚也无法修复,则可以将此文件夹中的内容复制到
/var/lib/etcd 进行手工修复。如果使用的是外部的 etcd,则此备份文件夹为空。
kubeadm-backup-manifests 包含当前控制面节点的静态 Pod 清单文件的备份版本。
如果升级失败并且无法自动回滚,则此文件夹中的内容可以复制到
/etc/kubernetes/manifests 目录实现手工恢复。
如果由于某些原因,在升级前后某个组件的清单未发生变化,则 kubeadm 也不会为之
生成备份版本。
工作原理
kubeadm upgrade apply 做了以下工作:
- 检查你的集群是否处于可升级状态:
- API 服务器是可访问的
- 所有节点处于
Ready状态 - 控制面是健康的
- 强制执行版本偏差策略。
- 确保控制面的镜像是可用的或可拉取到服务器上。
- 如果组件配置要求版本升级,则生成替代配置与/或使用用户提供的覆盖版本配置。
- 升级控制面组件或回滚(如果其中任何一个组件无法启动)。
- 应用新的
CoreDNS和kube-proxy清单,并强制创建所有必需的 RBAC 规则。 - 如果旧文件在 180 天后过期,将创建 API 服务器的新证书和密钥文件并备份旧文件。
kubeadm upgrade node 在其他控制平节点上执行以下操作:
- 从集群中获取 kubeadm
ClusterConfiguration。 - (可选操作)备份 kube-apiserver 证书。
- 升级控制平面组件的静态 Pod 清单。
- 为本节点升级 kubelet 配置
kubeadm upgrade node 在工作节点上完成以下工作:
- 从集群取回 kubeadm
ClusterConfiguration。 - 为本节点升级 kubelet 配置。
2.4 - 添加 Windows 节点
Kubernetes v1.18 [beta]
你可以使用 Kubernetes 来混合运行 Linux 和 Windows 节点,这样你就可以 混合使用运行于 Linux 上的 Pod 和运行于 Windows 上的 Pod。 本页面展示如何将 Windows 节点注册到你的集群。
准备开始
您的 Kubernetes 服务器版本必须不低于版本 1.17. 要获知版本信息,请输入kubectl version.
-
获取 Windows Server 2019 或更高版本的授权 以便配置托管 Windows 容器的 Windows 节点。 如果你在使用 VXLAN/覆盖(Overlay)联网设施,则你还必须安装 KB4489899。
-
一个利用 kubeadm 创建的基于 Linux 的 Kubernetes 集群;你能访问该集群的控制面 (参见使用 kubeadm 创建一个单控制面的集群)。
教程目标
- 将一个 Windows 节点注册到集群上
- 配置网络,以便 Linux 和 Windows 上的 Pod 和 Service 之间能够相互通信。
开始行动:向你的集群添加一个 Windows 节点
联网配置
一旦你有了一个基于 Linux 的 Kubernetes 控制面节点,你就可以为其选择联网方案。 出于简单考虑,本指南展示如何使用 VXLAN 模式的 Flannel。
配置 Flannel
-
为 Flannel 准备 Kubernetes 的控制面
在我们的集群中,建议对 Kubernetes 的控制面进行少许准备处理。 建议在使用 Flannel 时为 iptables 链启用桥接方式的 IPv4 流处理, 必须在所有 Linux 节点上执行如下命令:
sudo sysctl net.bridge.bridge-nf-call-iptables=1
-
下载并配置 Linux 版本的 Flannel
下载最新的 Flannel 清单文件:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml修改 Flannel 清单中的
net-conf.json部分,将 VNI 设置为 4096,并将 Port 设置为 4789。 结果看起来像下面这样:net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan", "VNI": 4096, "Port": 4789 } }说明: 在 Linux 节点上 VNI 必须设置为 4096,端口必须设置为 4789,这样才能令其与 Windows 上的 Flannel 互操作。关于这些字段的详细说明,请参见 VXLAN 文档。说明: 如要使用 L2Bridge/Host-gateway 模式,则可将Type值设置为"host-gw",并忽略VNI和Port的设置。
-
应用 Flannel 清单并验证
首先应用 Flannel 配置:
kubectl apply -f kube-flannel.yml几分钟之后,如果 Flannel Pod 网络被正确部署,你应该会看到所有 Pods 都处于运行中状态。
kubectl get pods -n kube-system输出中应该包含处于运行中状态的 Linux Flannel DaemonSet:
NAMESPACE NAME READY STATUS RESTARTS AGE ... kube-system kube-flannel-ds-54954 1/1 Running 0 1m
-
添加 Windows Flannel 和 kube-proxy DaemonSet
现在你可以添加 Windows 兼容版本的 Flannel 和 kube-proxy。为了确保你能获得兼容 版本的 kube-proxy,你需要替换镜像中的标签。 下面的例子中展示的是针对 Kubernetes v1.23.0 版本的用法, 不过你应该根据你自己的集群部署调整其中的版本号。
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.23.0/g' | kubectl apply -f - kubectl apply -f https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml说明: 如果你在使用 host-gateway 模式,则应该使用 https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-host-gw.yml 这一清单。说明:如果你在 Windows 节点上使用的不是以太网(即,"Ethernet0 2")接口,你需要 修改
flannel-host-gw.yml或flannel-overlay.yml文件中的下面这行:wins cli process run --path /k/flannel/setup.exe --args "--mode=overlay --interface=Ethernet"在其中根据情况设置要使用的网络接口。
# Example curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml | sed 's/Ethernet/Ethernet0 2/g' | kubectl apply -f -
加入 Windows 工作节点
Windows 节的所有代码片段都需要在 PowerShell 环境中执行,并且要求在 Windows 工作节点上具有提升的权限(Administrator)。
安装 Docker EE
Install-WindowsFeature -Name containers
安装 Docker 操作指南在 Install Docker Engine - Enterprise on Windows Servers。
安装 wins、kubelet 和 kubeadm
curl.exe -LO https://raw.githubusercontent.com/kubernetes-sigs/sig-windows-tools/master/kubeadm/scripts/PrepareNode.ps1
.\PrepareNode.ps1 -KubernetesVersion v1.23.0
运行 kubeadm 添加节点
当你在控制面主机上运行 kubeadm init 时,输出了一个命令。现在运行这个命令。
如果你找不到这个命令,或者命令中对应的令牌已经过期,你可以(在一个控制面主机上)运行
kubeadm token create --print-join-command 来生成新的令牌和 join 命令。
安装 containerD
curl.exe -LO https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/Install-Containerd.ps1
.\Install-Containerd.ps1
要安装特定版本的 containerD,使用参数 -ContainerDVersion指定版本。
# Example
.\Install-Containerd.ps1 -ContainerDVersion 1.4.1
如果你在 Windows 节点上使用了与 Ethernet 不同的接口(例如 "Ethernet0 2"),使用参数 -netAdapterName 指定名称。
# Example
.\Install-Containerd.ps1 -netAdapterName "Ethernet0 2"
安装 wins,kubelet 和 kubeadm
curl.exe -LO https://raw.githubusercontent.com/kubernetes-sigs/sig-windows-tools/master/kubeadm/scripts/PrepareNode.ps1
.\PrepareNode.ps1 -KubernetesVersion v1.23.0 -ContainerRuntime containerD
运行 kubeadm 添加节点
使用当你在控制面主机上运行 kubeadm init 时得到的命令。
如果你找不到这个命令,或者命令中对应的令牌已经过期,你可以(在一个控制面主机上)运行
kubeadm token create --print-join-command 来生成新的令牌和 join 命令。
--cri-socket "npipe:////./pipe/containerd-containerd" to the kubeadm call
检查你的安装
你现在应该能够通过运行下面的命令来查看集群中的 Windows 节点了:
kubectl get nodes -o wide
如果你的新节点处于 NotReady 状态,很可能的原因是系统仍在下载 Flannel 镜像。
你可以像之前一样,通过检查 kube-system 名字空间中的 Flannel Pods 来了解
安装进度。
kubectl -n kube-system get pods -l app=flannel
一旦 Flannel Pod 运行起来,你的节点就应该能进入 Ready 状态并可
用来处理负载。
接下来
2.5 - 升级 Windows 节点
Kubernetes v1.18 [beta]
本页解释如何升级用 kubeadm 创建的 Windows 节点。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
您的 Kubernetes 服务器版本必须不低于版本 1.17. 要获知版本信息,请输入kubectl version.
- 熟悉更新 kubeadm 集群中的其余组件。 在升级你的 Windows 节点之前你会想要升级控制面节点。
升级工作节点
升级 kubeadm
-
在 Windows 节点上升级 kubeadm:
# 将 v1.23.0 替换为你希望的版本 curl.exe -Lo C:\k\kubeadm.exe https://dl.k8s.io//bin/windows/amd64/kubeadm.exe
腾空节点
-
在一个能访问到 Kubernetes API 的机器上,将 Windows 节点标记为不可调度并 驱逐其上的所有负载,以便准备节点维护操作:
# 将 <要腾空的节点> 替换为你要腾空的节点的名称 kubectl drain <要腾空的节点> -ignore-daemonsets你应该会看到类似下面的输出:
node/ip-172-31-85-18 cordoned node/ip-172-31-85-18 drained
升级 kubelet 配置
-
在 Windows 节点上,执行下面的命令来同步新的 kubelet 配置:
kubeadm upgrade node
升级 kubelet
-
在 Windows 节点上升级并重启 kubelet:
stop-service kubelet curl.exe -Lo C:\k\kubelet.exe https://dl.k8s.io//bin/windows/amd64/kubelet.exe restart-service kubelet
对节点执行 uncordon 操作
-
从一台能够访问到 Kubernetes API 的机器上,通过将节点标记为可调度,使之 重新上线:
# 将 <要腾空的节点> 替换为你的节点名称 kubectl uncordon <要腾空的节点>
升级 kube-proxy
-
在一台可访问 Kubernetes API 的机器上和,将 v1.23.0 替换成你 期望的版本后再次执行下面的命令:
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.23.0/g' | kubectl apply -f -
3 - 管理内存,CPU 和 API 资源
3.1 - 为命名空间配置默认的内存请求和限制
本文介绍怎样给命名空间配置默认的内存请求和限制。 如果在一个有默认内存限制的命名空间创建容器,该容器没有声明自己的内存限制时, 将会被指定默认内存限制。 Kubernetes 还为某些情况指定了默认的内存请求,本章后面会进行介绍。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
你的集群中的每个节点必须至少有 2 GiB 的内存。
创建命名空间
创建一个命名空间,以便本练习中所建的资源与集群的其余资源相隔离。
kubectl create namespace default-mem-example
创建 LimitRange 和 Pod
这里给出了一个限制范围对象的配置文件。该配置声明了一个默认的内存请求和一个默认的内存限制。

apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
在 default-mem-example 命名空间创建限制范围:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults.yaml --namespace=default-mem-example
现在,如果在 default-mem-example 命名空间创建容器,并且该容器没有声明自己的内存请求和限制值, 它将被指定默认的内存请求 256 MiB 和默认的内存限制 512 MiB。
下面是具有一个容器的 Pod 的配置文件。 容器未指定内存请求和限制。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo
spec:
containers:
- name: default-mem-demo-ctr
image: nginx
创建 Pod
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod.yaml --namespace=default-mem-example
查看 Pod 的详情:
kubectl get pod default-mem-demo --output=yaml --namespace=default-mem-example
输出内容显示该 Pod 的容器有 256 MiB 的内存请求和 512 MiB 的内存限制。 这些都是 LimitRange 设置的默认值。
containers:
- image: nginx
imagePullPolicy: Always
name: default-mem-demo-ctr
resources:
limits:
memory: 512Mi
requests:
memory: 256Mi
删除你的 Pod:
kubectl delete pod default-mem-demo --namespace=default-mem-example
声明容器的限制而不声明它的请求会怎么样?
这里给出了包含一个容器的 Pod 的配置文件。该容器声明了内存限制,而没有声明内存请求:
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-2
spec:
containers:
- name: default-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1Gi"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-2.yaml --namespace=default-mem-example
查看 Pod 的详情:
kubectl get pod default-mem-demo-2 --output=yaml --namespace=default-mem-example
输出结果显示容器的内存请求被设置为它的内存限制相同的值。注意该容器没有被指定默认的内存请求值 256MiB。
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
声明容器的内存请求而不声明内存限制会怎么样?
这里给出了一个包含一个容器的 Pod 的配置文件。该容器声明了内存请求,但没有内存限制:
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-3
spec:
containers:
- name: default-mem-demo-3-ctr
image: nginx
resources:
requests:
memory: "128Mi"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-3.yaml --namespace=default-mem-example
查看 Pod 声明:
kubectl get pod default-mem-demo-3 --output=yaml --namespace=default-mem-example
输出结果显示该容器的内存请求被设置为了容器配置文件中声明的数值。 容器的内存限制被设置为 512MiB,即命名空间的默认内存限制。
resources:
limits:
memory: 512Mi
requests:
memory: 128Mi
设置默认内存限制和请求的动机
如果你的命名空间有资源配额,那么默认内存限制是很有帮助的。 下面是一个例子,通过资源配额为命名空间设置两项约束:
- 运行在命名空间中的每个容器必须有自己的内存限制。
- 命名空间中所有容器的内存使用量之和不能超过声明的限制值。
如果一个容器没有声明自己的内存限制,会被指定默认限制,然后它才会被允许在限定了配额的命名空间中运行。
清理
删除你的命名空间:
kubectl delete namespace default-mem-example
接下来
集群管理员参考
- 为命名空间配置默认的 CPU 请求和限制
- 为命名空间配置最小和最大内存限制
- 为命名空间配置最小和最大 CPU 限制
- 为命名空间配置内存和 CPU 配额
- 为命名空间配置 Pod 配额
- 为 API 对象配置配额
应用开发者参考
3.2 - 为命名空间配置默认的 CPU 请求和限制
本章介绍怎样为命名空间配置默认的 CPU 请求和限制。 一个 Kubernetes 集群可被划分为多个命名空间。如果在配置了 CPU 限制的命名空间创建容器, 并且该容器没有声明自己的 CPU 限制,那么这个容器会被指定默认的 CPU 限制。 Kubernetes 在一些特定情况还会指定 CPU 请求,本文后续章节将会对其进行解释。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
创建命名空间
创建一个命名空间,以便本练习中创建的资源和集群的其余部分相隔离。
kubectl create namespace default-cpu-example
创建 LimitRange 和 Pod
这里给出了 LimitRange 对象的配置文件。该配置声明了一个默认的 CPU 请求和一个默认的 CPU 限制。
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-limit-range
spec:
limits:
- default:
cpu: 1
defaultRequest:
cpu: 0.5
type: Container
在命名空间 default-cpu-example 中创建 LimitRange 对象:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults.yaml --namespace=default-cpu-example
现在如果在 default-cpu-example 命名空间创建一个容器,该容器没有声明自己的 CPU 请求和限制时, 将会给它指定默认的 CPU 请求0.5和默认的 CPU 限制值1.
这里给出了包含一个容器的 Pod 的配置文件。该容器没有声明 CPU 请求和限制。
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo
spec:
containers:
- name: default-cpu-demo-ctr
image: nginx
创建 Pod。
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod.yaml --namespace=default-cpu-example
查看该 Pod 的声明:
kubectl get pod default-cpu-demo --output=yaml --namespace=default-cpu-example
输出显示该 Pod 的容器有一个500 millicpus的 CPU 请求和一个1 cpu的 CPU 限制。这些是 LimitRange 声明的默认值。
containers:
- image: nginx
imagePullPolicy: Always
name: default-cpu-demo-ctr
resources:
limits:
cpu: "1"
requests:
cpu: 500m
你只声明容器的限制,而不声明请求会怎么样?
这是包含一个容器的 Pod 的配置文件。该容器声明了 CPU 限制,而没有声明 CPU 请求。
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo-2
spec:
containers:
- name: default-cpu-demo-2-ctr
image: nginx
resources:
limits:
cpu: "1"
创建 Pod
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod-2.yaml --namespace=default-cpu-example
查看 Pod 的声明:
kubectl get pod default-cpu-demo-2 --output=yaml --namespace=default-cpu-example
输出显示该容器的 CPU 请求和 CPU 限制设置相同。注意该容器没有被指定默认的 CPU 请求值0.5 cpu。
resources:
limits:
cpu: "1"
requests:
cpu: "1"
你只声明容器的请求,而不声明它的限制会怎么样?
这里给出了包含一个容器的 Pod 的配置文件。该容器声明了 CPU 请求,而没有声明 CPU 限制。
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo-3
spec:
containers:
- name: default-cpu-demo-3-ctr
image: nginx
resources:
requests:
cpu: "0.75"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod-3.yaml --namespace=default-cpu-example
查看 Pod 的规约:
kubectl get pod default-cpu-demo-3 --output=yaml --namespace=default-cpu-example
结果显示该容器的 CPU 请求被设置为容器配置文件中声明的数值。 容器的CPU限制被设置为 1 CPU,即该命名空间的默认 CPU 限制值。
resources:
limits:
cpu: "1"
requests:
cpu: 750m
默认 CPU 限制和请求的动机
如果你的命名空间有一个 资源配额, 那么有一个默认的 CPU 限制是有帮助的。这里有资源配额强加给命名空间的两条限制:
- 命名空间中运行的每个容器必须有自己的 CPU 限制。
- 命名空间中所有容器使用的 CPU 总和不能超过一个声明值。
如果容器没有声明自己的 CPU 限制,将会给它一个默认限制,这样它就能被允许运行在一个有配额限制的命名空间中。
清理
删除你的命名空间:
kubectl delete namespace constraints-cpu-example
接下来
集群管理员参考
- 为命名空间配置默认内存请求和限制
- 为命名空间配置内存限制的最小值和最大值
- 为命名空间配置 CPU 限制的最小值和最大值
- 为命名空间配置内存和 CPU 配额
- 为命名空间配置 Pod 配额
- 为 API 对象配置配额
应用开发者参考
3.3 - 配置命名空间的最小和最大内存约束
本页介绍如何设置在命名空间中运行的容器使用的内存的最小值和最大值。 你可以在 LimitRange 对象中指定最小和最大内存值。如果 Pod 不满足 LimitRange 施加的约束,则无法在命名空间中创建它。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
集群中每个节点必须至少要有 1 GiB 的内存。
创建命名空间
创建一个命名空间,以便在此练习中创建的资源与群集的其余资源隔离。
kubectl create namespace constraints-mem-example
创建 LimitRange 和 Pod
下面是 LimitRange 的配置文件:
apiVersion: v1
kind: LimitRange
metadata:
name: mem-min-max-demo-lr
spec:
limits:
- max:
memory: 1Gi
min:
memory: 500Mi
type: Container
创建 LimitRange:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints.yaml --namespace=constraints-mem-example
查看 LimitRange 的详情:
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
输出显示预期的最小和最大内存约束。 但请注意,即使你没有在 LimitRange 的配置文件中指定默认值,也会自动创建它们。
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container
现在,只要在 constraints-mem-example 命名空间中创建容器,Kubernetes 就会执行下面的步骤:
-
如果 Container 未指定自己的内存请求和限制,将为它指定默认的内存请求和限制。
-
验证 Container 的内存请求是否大于或等于500 MiB。
-
验证 Container 的内存限制是否小于或等于1 GiB。
这里给出了包含一个 Container 的 Pod 配置文件。Container 声明了 600 MiB 的内存请求和 800 MiB 的内存限制, 这些满足了 LimitRange 施加的最小和最大内存约束。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo
spec:
containers:
- name: constraints-mem-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "600Mi"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod.yaml --namespace=constraints-mem-example
确认下 Pod 中的容器在运行:
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
查看 Pod 详情:
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
输出结果显示容器的内存请求为600 MiB,内存限制为800 MiB。这些满足了 LimitRange 设定的限制范围。
resources:
limits:
memory: 800Mi
requests:
memory: 600Mi
删除你创建的 Pod:
kubectl delete pod constraints-mem-demo --namespace=constraints-mem-example
尝试创建一个超过最大内存限制的 Pod
这里给出了包含一个容器的 Pod 的配置文件。容器声明了800 MiB 的内存请求和1.5 GiB 的内存限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-2
spec:
containers:
- name: constraints-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1.5Gi"
requests:
memory: "800Mi"
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-2.yaml --namespace=constraints-mem-example
输出结果显示 Pod 没有创建成功,因为容器声明的内存限制太大了:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
尝试创建一个不满足最小内存请求的 Pod
这里给出了包含一个容器的 Pod 的配置文件。容器声明了100 MiB 的内存请求和800 MiB 的内存限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-3
spec:
containers:
- name: constraints-mem-demo-3-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "100Mi"
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-3.yaml --namespace=constraints-mem-example
输出结果显示 Pod 没有创建成功,因为容器声明的内存请求太小了:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
创建一个没有声明内存请求和限制的 Pod
这里给出了包含一个容器的 Pod 的配置文件。容器没有声明内存请求,也没有声明内存限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-4
spec:
containers:
- name: constraints-mem-demo-4-ctr
image: nginx
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-4.yaml --namespace=constraints-mem-example
查看 Pod 详情:
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
输出结果显示 Pod 的内存请求为1 GiB,内存限制为1 GiB。容器怎样获得哪些数值呢?
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
因为你的容器没有声明自己的内存请求和限制,它从 LimitRange 那里获得了 默认的内存请求和限制。
此时,你的容器可能运行起来也可能没有运行起来。 回想一下我们本次任务的先决条件是你的每个节点都至少有1 GiB 的内存。 如果你的每个节点都只有1 GiB 的内存,那将没有一个节点拥有足够的可分配内存来满足1 GiB 的内存请求。
删除你的 Pod:
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
强制执行内存最小和最大限制
LimitRange 为命名空间设定的最小和最大内存限制只有在 Pod 创建和更新时才会强制执行。 如果你更新 LimitRange,它不会影响此前创建的 Pod。
设置内存最小和最大限制的动因
作为集群管理员,你可能想规定 Pod 可以使用的内存总量限制。例如:
- 集群的每个节点有 2 GB 内存。你不想接受任何请求超过 2 GB 的 Pod,因为集群中没有节点可以满足。
- 集群由生产部门和开发部门共享。你希望允许产品部门的负载最多耗用 8 GB 内存, 但是开发部门的负载最多可使用 512 MiB。 这时,你可以为产品部门和开发部门分别创建名字空间,并为各个名字空间设置内存约束。
清理
删除你的命名空间:
kubectl delete namespace constraints-mem-example
接下来
集群管理员参考
- 为命名空间配置默认内存请求和限制
- 为命名空间配置内存限制的最小值和最大值
- 为命名空间配置 CPU 限制的最小值和最大值
- 为命名空间配置内存和 CPU 配额
- 为命名空间配置 Pod 配额
- 为 API 对象配置配额
应用开发者参考
3.4 - 为命名空间配置 CPU 最小和最大约束
本页介绍如何为命名空间中容器和 Pod 使用的 CPU 资源设置最小和最大值。 你可以通过 LimitRange 对象声明 CPU 的最小和最大值. 如果 Pod 不能满足 LimitRange 的限制,它就不能在命名空间中创建。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
你的集群中每个节点至少要有 1 个 CPU 可用才能运行本任务示例。
创建命名空间
创建一个命名空间,以便本练习中创建的资源和集群的其余资源相隔离。
kubectl create namespace constraints-cpu-example
创建 LimitRange 和 Pod
这里给出了 LimitRange 的配置文件:
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-min-max-demo-lr
spec:
limits:
- max:
cpu: "800m"
min:
cpu: "200m"
type: Container
创建 LimitRange:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints.yaml --namespace=constraints-cpu-example
查看 LimitRange 详情:
kubectl get limitrange cpu-min-max-demo-lr --output=yaml --namespace=constraints-cpu-example
输出结果显示 CPU 的最小和最大限制符合预期。但需要注意的是,尽管你在 LimitRange 的配置文件中你没有声明默认值,默认值也会被自动创建。
limits:
- default:
cpu: 800m
defaultRequest:
cpu: 800m
max:
cpu: 800m
min:
cpu: 200m
type: Container
现在不管什么时候在 constraints-cpu-example 命名空间中创建容器,Kubernetes 都会执行下面这些步骤:
-
如果容器没有声明自己的 CPU 请求和限制,将为容器指定默认 CPU 请求和限制。
-
核查容器声明的 CPU 请求确保其大于或者等于 200 millicpu。
-
核查容器声明的 CPU 限制确保其小于或者等于 800 millicpu。
这里给出了包含一个容器的 Pod 的配置文件。 该容器声明了 500 millicpu 的 CPU 请求和 800 millicpu 的 CPU 限制。 这些参数满足了 LimitRange 对象规定的 CPU 最小和最大限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo
spec:
containers:
- name: constraints-cpu-demo-ctr
image: nginx
resources:
limits:
cpu: "800m"
requests:
cpu: "500m"
创建Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod.yaml --namespace=constraints-cpu-example
确认一下 Pod 中的容器在运行:
kubectl get pod constraints-cpu-demo --namespace=constraints-cpu-example
查看 Pod 的详情:
kubectl get pod constraints-cpu-demo --output=yaml --namespace=constraints-cpu-example
输出结果表明容器的 CPU 请求为 500 millicpu,CPU 限制为 800 millicpu。 这些参数满足 LimitRange 规定的限制范围。
resources:
limits:
cpu: 800m
requests:
cpu: 500m
删除 Pod
kubectl delete pod constraints-cpu-demo --namespace=constraints-cpu-example
尝试创建一个超过最大 CPU 限制的 Pod
这里给出了包含一个容器的 Pod 的配置文件。容器声明了 500 millicpu 的 CPU 请求和 1.5 CPU 的 CPU 限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-2
spec:
containers:
- name: constraints-cpu-demo-2-ctr
image: nginx
resources:
limits:
cpu: "1.5"
requests:
cpu: "500m"
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-2.yaml --namespace=constraints-cpu-example
输出结果表明 Pod 没有创建成功,因为容器声明的 CPU 限制太大了:
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-2.yaml":
pods "constraints-cpu-demo-2" is forbidden: maximum cpu usage per Container is 800m, but limit is 1500m.
尝试创建一个不满足最小 CPU 请求的 Pod
这里给出了包含一个容器的 Pod 的配置文件。该容器声明了100 millicpu的 CPU 请求和800 millicpu的 CPU 限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-3
spec:
containers:
- name: constraints-cpu-demo-3-ctr
image: nginx
resources:
limits:
cpu: "800m"
requests:
cpu: "100m"
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-3.yaml --namespace=constraints-cpu-example
输出结果显示 Pod 没有创建成功,因为容器声明的 CPU 请求太小了:
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-3.yaml":
pods "constraints-cpu-demo-4" is forbidden: minimum cpu usage per Container is 200m, but request is 100m.
创建一个没有声明 CPU 请求和 CPU 限制的 Pod
这里给出了包含一个容器的 Pod 的配置文件。该容器没有设定 CPU 请求和 CPU 限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-4
spec:
containers:
- name: constraints-cpu-demo-4-ctr
image: vish/stress
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-4.yaml --namespace=constraints-cpu-example
查看 Pod 的详情:
kubectl get pod constraints-cpu-demo-4 --namespace=constraints-cpu-example --output=yaml
输出结果显示 Pod 的容器有个 800 millicpu 的 CPU 请求和 800 millicpu 的 CPU 限制。 容器是怎样得到那些值的呢?
resources:
limits:
cpu: 800m
requests:
cpu: 800m
因为你的 Container 没有声明自己的 CPU 请求和限制,LimitRange 给它指定了 默认的 CPU 请求和限制
此时,你的容器可能运行也可能没有运行。 回想一下,本任务的先决条件是你的节点要有 1 个 CPU。 如果你的每个节点仅有 1 个 CPU,那么可能没有任何一个节点可以满足 800 millicpu 的 CPU 请求。 如果你在用的节点恰好有两个 CPU,那么你才可能有足够的 CPU 来满足 800 millicpu 的请求。
kubectl delete pod constraints-cpu-demo-4 --namespace=constraints-cpu-example
CPU 最小和最大限制的强制执行
只有当 Pod 创建或者更新时,LimitRange 为命名空间规定的 CPU 最小和最大限制才会被强制执行。 如果你对 LimitRange 进行修改,那不会影响此前创建的 Pod。
最小和最大 CPU 限制范围的动机
作为集群管理员,你可能想设定 Pod 可以使用的 CPU 资源限制。例如:
- 集群中的每个节点有两个 CPU。你不想接受任何请求超过 2 个 CPU 的 Pod,因为集群中没有节点可以支持这种请求。
- 你的生产和开发部门共享一个集群。你想允许生产工作负载消耗 3 个 CPU, 而开发部门工作负载的消耗限制为 1 个 CPU。 你可以为生产和开发创建不同的命名空间,并且为每个命名空间都应用 CPU 限制。
清理
删除你的命名空间:
kubectl delete namespace constraints-cpu-example
接下来
集群管理员参考:
- 为命名空间配置默认内存请求和限制
- 为命名空间配置内存限制的最小值和最大值
- 为命名空间配置 CPU 限制的最小值和最大值
- 为命名空间配置内存和 CPU 配额
- 为命名空间配置 Pod 配额
- 为 API 对象配置配额
应用开发者参考:
3.5 - 为命名空间配置内存和 CPU 配额
本文介绍怎样为命名空间设置容器可用的内存和 CPU 总量。你可以通过 ResourceQuota 对象设置配额.
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
集群中每个节点至少有 1 GiB 的内存。
创建命名空间
创建一个命名空间,以便本练习中创建的资源和集群的其余部分相隔离。
kubectl create namespace quota-mem-cpu-example
创建 ResourceQuota
这里给出一个 ResourceQuota 对象的配置文件:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
创建 ResourceQuota
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu.yaml --namespace=quota-mem-cpu-example
查看 ResourceQuota 详情:
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
ResourceQuota 在 quota-mem-cpu-example 命名空间中设置了如下要求:
- 每个容器必须有内存请求和限制,以及 CPU 请求和限制。
- 所有容器的内存请求总和不能超过1 GiB。
- 所有容器的内存限制总和不能超过2 GiB。
- 所有容器的 CPU 请求总和不能超过1 cpu。
- 所有容器的 CPU 限制总和不能超过2 cpu。
创建 Pod
这里给出 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo
spec:
containers:
- name: quota-mem-cpu-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
cpu: "800m"
requests:
memory: "600Mi"
cpu: "400m"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu-pod.yaml --namespace=quota-mem-cpu-example
检查下 Pod 中的容器在运行:
kubectl get pod quota-mem-cpu-demo --namespace=quota-mem-cpu-example
再查看 ResourceQuota 的详情:
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
输出结果显示了配额以及有多少配额已经被使用。你可以看到 Pod 的内存和 CPU 请求值及限制值没有超过配额。
status:
hard:
limits.cpu: "2"
limits.memory: 2Gi
requests.cpu: "1"
requests.memory: 1Gi
used:
limits.cpu: 800m
limits.memory: 800Mi
requests.cpu: 400m
requests.memory: 600Mi
尝试创建第二个 Pod
这里给出了第二个 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo-2
spec:
containers:
- name: quota-mem-cpu-demo-2-ctr
image: redis
resources:
limits:
memory: "1Gi"
cpu: "800m"
requests:
memory: "700Mi"
cpu: "400m"
配置文件中,你可以看到 Pod 的内存请求为 700 MiB。 请注意新的内存请求与已经使用的内存请求只和超过了内存请求的配额。 600 MiB + 700 MiB > 1 GiB。
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu-pod-2.yaml --namespace=quota-mem-cpu-example
第二个 Pod 不能被创建成功。输出结果显示创建第二个 Pod 会导致内存请求总量超过内存请求配额。
Error from server (Forbidden): error when creating "examples/admin/resource/quota-mem-cpu-pod-2.yaml":
pods "quota-mem-cpu-demo-2" is forbidden: exceeded quota: mem-cpu-demo,
requested: requests.memory=700Mi,used: requests.memory=600Mi, limited: requests.memory=1Gi
讨论
如你在本练习中所见,你可以用 ResourceQuota 限制命名空间中所有容器的内存请求总量。 同样你也可以限制内存限制总量、CPU 请求总量、CPU 限制总量。
如果你想对单个容器而不是所有容器进行限制,就请使用 LimitRange。
清理
删除你的命名空间:
kubectl delete namespace quota-mem-cpu-example
接下来
集群管理员参考
- 为命名空间配置默认内存请求和限制
- 为命名空间配置内存限制的最小值和最大值
- 为命名空间配置 CPU 限制的最小值和最大值
- 为命名空间配置内存和 CPU 配额
- 为命名空间配置 Pod 配额
- 为 API 对象配置配额
应用开发者参考
3.6 - 配置命名空间下 Pod 配额
本文主要描述如何配置一个命名空间下可运行的 Pod 个数配额。 你可以使用 ResourceQuota 对象来配置配额。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
创建一个命名空间
首先创建一个命名空间,这样可以将本次操作中创建的资源与集群其他资源隔离开来。
kubectl create namespace quota-pod-example
创建 ResourceQuota
下面是一个 ResourceQuota 的配置文件:
apiVersion: v1
kind: ResourceQuota
metadata:
name: pod-demo
spec:
hard:
pods: "2"
创建这个 ResourceQuota:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-pod.yaml --namespace=quota-pod-example
查看资源配额的详细信息:
kubectl get resourcequota pod-demo --namespace=quota-pod-example --output=yaml
从输出的信息我们可以看到,该命名空间下 Pod 的配额是 2 个,目前创建的 Pod 数为 0, 配额使用率为 0。
spec:
hard:
pods: "2"
status:
hard:
pods: "2"
used:
pods: "0"
下面是一个 Deployment 的配置文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-quota-demo
spec:
selector:
matchLabels:
purpose: quota-demo
replicas: 3
template:
metadata:
labels:
purpose: quota-demo
spec:
containers:
- name: pod-quota-demo
image: nginx
在配置文件中,replicas: 3 告诉 Kubernetes 尝试创建三个 Pods,且运行相同的应用。
创建这个 Deployment:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-pod-deployment.yaml --namespace=quota-pod-example
查看 Deployment 的详细信息:
kubectl get deployment pod-quota-demo --namespace=quota-pod-example --output=yaml
从输出的信息我们可以看到,尽管尝试创建三个 Pod,但是由于配额的限制,只有两个 Pod 能被成功创建。
spec:
...
replicas: 3
...
status:
availableReplicas: 2
...
lastUpdateTime: 2017-07-07T20:57:05Z
message: 'unable to create pods: pods "pod-quota-demo-1650323038-" is forbidden:
exceeded quota: pod-demo, requested: pods=1, used: pods=2, limited: pods=2'
清理
删除命名空间:
kubectl delete namespace quota-pod-example
接下来
集群管理人员参考
- 为命名空间配置默认的内存请求和限制
- 为命名空间配置默认的的 CPU 请求和限制
- 为命名空间配置内存的最小值和最大值约束
- 为命名空间配置 CPU 的最小值和最大值约束
- 为命名空间配置内存和 CPU 配额
- 为 API 对象的设置配额
应用开发人员参考
4 - 证书
在使用客户端证书认证的场景下,你可以通过 easyrsa、openssl 或 cfssl 等工具以手工方式生成证书。
easyrsa
easyrsa 支持以手工方式为你的集群生成证书。
-
下载、解压、初始化打过补丁的 easyrsa3。
curl -LO https://storage.googleapis.com/kubernetes-release/easy-rsa/easy-rsa.tar.gz tar xzf easy-rsa.tar.gz cd easy-rsa-master/easyrsa3 ./easyrsa init-pki -
生成新的证书颁发机构(CA)。参数
--batch用于设置自动模式; 参数--req-cn用于设置新的根证书的通用名称(CN)。./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass -
生成服务器证书和秘钥。 参数
--subject-alt-name设置 API 服务器的 IP 和 DNS 名称。MASTER_CLUSTER_IP用于 API 服务器和控制管理器,通常取 CIDR 的第一个 IP,由--service-cluster-ip-range的参数提供。 参数--days用于设置证书的过期时间。 下面的示例假定你的默认 DNS 域名为cluster.local。./easyrsa --subject-alt-name="IP:${MASTER_IP},"\ "IP:${MASTER_CLUSTER_IP},"\ "DNS:kubernetes,"\ "DNS:kubernetes.default,"\ "DNS:kubernetes.default.svc,"\ "DNS:kubernetes.default.svc.cluster,"\ "DNS:kubernetes.default.svc.cluster.local" \ --days=10000 \ build-server-full server nopass -
拷贝文件
pki/ca.crt、pki/issued/server.crt和pki/private/server.key到你的目录中。 -
在 API 服务器的启动参数中添加以下参数:
--client-ca-file=/yourdirectory/ca.crt --tls-cert-file=/yourdirectory/server.crt --tls-private-key-file=/yourdirectory/server.key
openssl
openssl 支持以手工方式为你的集群生成证书。
-
生成一个 2048 位的 ca.key 文件
openssl genrsa -out ca.key 2048 -
在 ca.key 文件的基础上,生成 ca.crt 文件(用参数 -days 设置证书有效期)
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt -
生成一个 2048 位的 server.key 文件:
openssl genrsa -out server.key 2048 -
创建一个用于生成证书签名请求(CSR)的配置文件。 保存文件(例如:
csr.conf)前,记得用真实值替换掉尖括号中的值(例如:<MASTER_IP>)。 注意:MASTER_CLUSTER_IP就像前一小节所述,它的值是 API 服务器的服务集群 IP。 下面的例子假定你的默认 DNS 域名为cluster.local。[ req ] default_bits = 2048 prompt = no default_md = sha256 req_extensions = req_ext distinguished_name = dn [ dn ] C = <country> ST = <state> L = <city> O = <organization> OU = <organization unit> CN = <MASTER_IP> [ req_ext ] subjectAltName = @alt_names [ alt_names ] DNS.1 = kubernetes DNS.2 = kubernetes.default DNS.3 = kubernetes.default.svc DNS.4 = kubernetes.default.svc.cluster DNS.5 = kubernetes.default.svc.cluster.local IP.1 = <MASTER_IP> IP.2 = <MASTER_CLUSTER_IP> [ v3_ext ] authorityKeyIdentifier=keyid,issuer:always basicConstraints=CA:FALSE keyUsage=keyEncipherment,dataEncipherment extendedKeyUsage=serverAuth,clientAuth subjectAltName=@alt_names -
基于上面的配置文件生成证书签名请求:
openssl req -new -key server.key -out server.csr -config csr.conf -
基于 ca.key、ca.key 和 server.csr 等三个文件生成服务端证书:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \ -CAcreateserial -out server.crt -days 10000 \ -extensions v3_ext -extfile csr.conf -
查看证书签名请求:
openssl req -noout -text -in ./server.csr -
查看证书:
openssl x509 -noout -text -in ./server.crt
最后,为 API 服务器添加相同的启动参数。
cfssl
cfssl 是另一个用于生成证书的工具。
-
下载、解压并准备如下所示的命令行工具。 注意:你可能需要根据所用的硬件体系架构和 cfssl 版本调整示例命令。
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl chmod +x cfssl curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson chmod +x cfssljson curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo chmod +x cfssl-certinfo -
创建一个目录,用它保存所生成的构件和初始化 cfssl:
mkdir cert cd cert ../cfssl print-defaults config > config.json ../cfssl print-defaults csr > csr.json -
创建一个 JSON 配置文件来生成 CA 文件,例如:
ca-config.json:{ "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } -
创建一个 JSON 配置文件,用于 CA 证书签名请求(CSR),例如:
ca-csr.json。 确认用你需要的值替换掉尖括号中的值。{ "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names":[{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
生成 CA 秘钥文件(
ca-key.pem)和证书文件(ca.pem):../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca -
创建一个 JSON 配置文件,用来为 API 服务器生成秘钥和证书,例如:
server-csr.json。 确认用你需要的值替换掉尖括号中的值。MASTER_CLUSTER_IP是为 API 服务器 指定的服务集群 IP,就像前面小节描述的那样。 以下示例假定你的默认 DSN 域名为cluster.local。{ "CN": "kubernetes", "hosts": [ "127.0.0.1", "<MASTER_IP>", "<MASTER_CLUSTER_IP>", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
为 API 服务器生成秘钥和证书,默认会分别存储为
server-key.pem和server.pem两个文件。../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \ --config=ca-config.json -profile=kubernetes \ server-csr.json | ../cfssljson -bare server
分发自签名的 CA 证书
客户端节点可能不认可自签名 CA 证书的有效性。 对于非生产环境,或者运行在公司防火墙后的环境,你可以分发自签名的 CA 证书到所有客户节点,并刷新本地列表以使证书生效。
在每一个客户节点,执行以下操作:
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
证书 API
你可以通过 certificates.k8s.io API 提供 x509 证书,用来做身份验证,
如本文档所述。
5 - 安装网络规则驱动
5.1 - Use Antrea for NetworkPolicy
title: 使用 Antrea 提供 NetworkPolicy content_type: task weight: 10
本页展示了如何在 kubernetes 中安装和使用 Antrea CNI 插件。 要了解 Antrea 项目的背景,请阅读 Antrea 介绍。
准备开始
你需要拥有一个 kuernetes 集群。 遵循 kubeadm 入门指南自行创建一个。
使用 kubeadm 部署 Antrea
遵循入门指南 为 kubeadm 部署 Antrea 。
接下来
一旦你的集群已经运行,你可以遵循 声明网络策略 来尝试 Kubernetes NetworkPolicy。
5.2 - 使用 Calico 提供 NetworkPolicy
本页展示了几种在 Kubernetes 上快速创建 Calico 集群的方法。
准备开始
在 Google Kubernetes Engine (GKE) 上创建一个 Calico 集群
先决条件: gcloud
-
启动一个带有 Calico 的 GKE 集群,需要加上参数
--enable-network-policy。语法
gcloud container clusters create [CLUSTER_NAME] --enable-network-policy示例
gcloud container clusters create my-calico-cluster --enable-network-policy
-
使用如下命令验证部署是否正确。
kubectl get pods --namespace=kube-systemCalico 的 pods 名以
calico打头,检查确认每个 pods 状态为Running。
使用 kubeadm 创建一个本地 Calico 集群
使用 kubeadm 在 15 分钟内得到一个本地单主机 Calico 集群,请参考 Calico 快速入门。
接下来
集群运行后,您可以按照声明网络策略 去尝试使用 Kubernetes NetworkPolicy。
5.3 - 使用 Cilium 提供 NetworkPolicy
本页展示如何使用 Cilium 提供 NetworkPolicy。
关于 Cilium 的背景知识,请阅读 Cilium 介绍。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
在 Minikube 上部署 Cilium 用于基本测试
为了轻松熟悉 Cilium 你可以根据 Cilium Kubernetes 入门指南 在 minikube 中执行一个 cilium 的基本 DaemonSet 安装。
要启动 minikube,需要的最低版本为 1.5.2,使用下面的参数运行:
minikube version
minikube version: v1.5.2
minikube start --network-plugin=cni --memory=4096
对于 minikube 你可以使用 Cilium 的 CLI 工具安装它。 Cilium 将自动检测集群配置并为成功的集群部署选择合适的组件。
curl -LO https://github.com/cilium/cilium-cli/releases/latest/download/cilium-linux-amd64.tar.gz
sudo tar xzvfC cilium-linux-amd64.tar.gz /usr/local/bin
rm cilium-linux-amd64.tar.gz
cilium install
🔮 Auto-detected Kubernetes kind: minikube
✨ Running "minikube" validation checks
✅ Detected minikube version "1.20.0"
ℹ️ Cilium version not set, using default version "v1.10.0"
🔮 Auto-detected cluster name: minikube
🔮 Auto-detected IPAM mode: cluster-pool
🔮 Auto-detected datapath mode: tunnel
🔑 Generating CA...
2021/05/27 02:54:44 [INFO] generate received request
2021/05/27 02:54:44 [INFO] received CSR
2021/05/27 02:54:44 [INFO] generating key: ecdsa-256
2021/05/27 02:54:44 [INFO] encoded CSR
2021/05/27 02:54:44 [INFO] signed certificate with serial number 48713764918856674401136471229482703021230538642
🔑 Generating certificates for Hubble...
2021/05/27 02:54:44 [INFO] generate received request
2021/05/27 02:54:44 [INFO] received CSR
2021/05/27 02:54:44 [INFO] generating key: ecdsa-256
2021/05/27 02:54:44 [INFO] encoded CSR
2021/05/27 02:54:44 [INFO] signed certificate with serial number 3514109734025784310086389188421560613333279574
🚀 Creating Service accounts...
🚀 Creating Cluster roles...
🚀 Creating ConfigMap...
🚀 Creating Agent DaemonSet...
🚀 Creating Operator Deployment...
⌛ Waiting for Cilium to be installed...
入门指南其余的部分用一个示例应用说明了如何强制执行 L3/L4(即 IP 地址+端口)的安全策略 以及L7 (如 HTTP)的安全策略。
部署 Cilium 用于生产用途
关于部署 Cilium 用于生产的详细说明,请见 Cilium Kubernetes 安装指南 此文档包括详细的需求、说明和生产用途 DaemonSet 文件示例。
了解 Cilium 组件
部署使用 Cilium 的集群会添加 Pods 到 kube-system 命名空间。要查看 Pod 列表,运行:
kubectl get pods --namespace=kube-system -l k8s-app=cilium
你将看到像这样的 Pods 列表:
NAME READY STATUS RESTARTS AGE
cilium-kkdhz 1/1 Running 0 3m23s
...
你的集群中的每个节点上都会运行一个 cilium Pod,通过使用 Linux BPF
针对该节点上的 Pod 的入站、出站流量实施网络策略控制。
接下来
集群运行后,你可以按照 声明网络策略 试用基于 Cilium 的 Kubernetes NetworkPolicy。 玩得开心,如果你有任何疑问,请到 Cilium Slack 频道 联系我们。
5.4 - 使用 kube-router 提供 NetworkPolicy
本页展示如何使用 Kube-router 提供 NetworkPolicy。
准备开始
你需要拥有一个运行中的 Kubernetes 集群。如果你还没有集群,可以使用任意的集群 安装程序如 Kops、Bootkube、Kubeadm 等创建一个。
安装 kube-router 插件
kube-router 插件自带一个网络策略控制器,监视来自于 Kubernetes API 服务器的 NetworkPolicy 和 Pod 的变化,根据策略指示配置 iptables 规则和 ipsets 来允许或阻止流量。 请根据 通过集群安装程序尝试 kube-router 指南安装 kube-router 插件。
接下来
在你安装了 kube-router 插件后,可以参考 声明网络策略 去尝试使用 Kubernetes NetworkPolicy。
5.5 - 使用 Romana 提供 NetworkPolicy
本页展示如何使用 Romana 作为 NetworkPolicy。
准备开始
完成 kubeadm 入门指南中的 1、2、3 步。
使用 kubeadm 安装 Romana
按照容器化安装指南, 使用 kubeadm 安装。
应用网络策略
使用以下的一种方式应用网络策略:
- Romana 网络策略
- NetworkPolicy API
接下来
Romana 安装完成后,你可以按照 声明网络策略 去尝试使用 Kubernetes NetworkPolicy。
5.6 - 使用 Weave Net 提供 NetworkPolicy
本页展示如何使用使用 Weave Net 提供 NetworkPolicy。
准备开始
你需要拥有一个 Kubernetes 集群。按照 kubeadm 入门指南 来启动一个。
安装 Weave Net 插件
按照通过插件集成 Kubernetes 指南执行安装。
Kubernetes 的 Weave Net 插件带有
网络策略控制器,
可自动监控 Kubernetes 所有名字空间的 NetworkPolicy 注释,
配置 iptables 规则以允许或阻止策略指示的流量。
测试安装
验证 weave 是否有效。
输入以下命令:
kubectl get po -n kube-system -o wide
输出类似这样:
NAME READY STATUS RESTARTS AGE IP NODE
weave-net-1t1qg 2/2 Running 0 9d 192.168.2.10 worknode3
weave-net-231d7 2/2 Running 1 7d 10.2.0.17 worknodegpu
weave-net-7nmwt 2/2 Running 3 9d 192.168.2.131 masternode
weave-net-pmw8w 2/2 Running 0 9d 192.168.2.216 worknode2
每个 Node 都有一个 weave Pod,所有 Pod 都是Running 和 2/2 READY。
(2/2 表示每个 Pod 都有 weave 和 weave-npc)
接下来
安装 Weave Net 插件后,你可以参考 声明网络策略 来试用 Kubernetes NetworkPolicy。 如果你有任何疑问,请通过 Slack 上的 #weave-community 频道或者 Weave 用户组 联系我们。
6 - IP Masquerade Agent 用户指南
此页面展示如何配置和启用 ip-masq-agent。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
IP Masquerade Agent 用户指南
ip-masq-agent 配置 iptables 规则以隐藏位于集群节点 IP 地址后面的 Pod 的 IP 地址。 这通常在将流量发送到集群的 Pod CIDR 范围之外的目的地时使用。
关键术语
- NAT (网络地址转译) 是一种通过修改 IP 地址头中的源和/或目标地址信息将一个 IP 地址重新映射 到另一个 IP 地址的方法。通常由执行 IP 路由的设备执行。
- 伪装 NAT 的一种形式,通常用于执行多对一地址转换,其中多个源 IP 地址被隐藏在 单个地址后面,该地址通常是执行 IP 路由的设备。在 Kubernetes 中, 这是节点的 IP 地址。
- CIDR (无类别域间路由) 基于可变长度子网掩码,允许指定任意长度的前缀。 CIDR 引入了一种新的 IP 地址表示方法,现在通常称为CIDR表示法, 其中地址或路由前缀后添加一个后缀,用来表示前缀的位数,例如 192.168.2.0/24。
- 本地链路 本地链路是仅对网段或主机所连接的广播域内的通信有效的网络地址。 IPv4 的本地链路地址在 CIDR 表示法的地址块 169.254.0.0/16 中定义。
ip-masq-agent 配置 iptables 规则,以便在将流量发送到集群节点的 IP 和集群 IP 范围之外的目标时 处理伪装节点或 Pod 的 IP 地址。这本质上隐藏了集群节点 IP 地址后面的 Pod IP 地址。 在某些环境中,去往“外部”地址的流量必须从已知的机器地址发出。 例如,在 Google Cloud 中,任何到互联网的流量都必须来自 VM 的 IP。 使用容器时,如 Google Kubernetes Engine,从 Pod IP 发出的流量将被拒绝出站。 为了避免这种情况,我们必须将 Pod IP 隐藏在 VM 自己的 IP 地址后面 - 通常称为“伪装”。 默认情况下,代理配置为将 RFC 1918 指定的三个私有 IP 范围视为非伪装 CIDR。 这些范围是 10.0.0.0/8,172.16.0.0/12 和 192.168.0.0/16。 默认情况下,代理还将链路本地地址(169.254.0.0/16)视为非伪装 CIDR。 代理程序配置为每隔 60 秒从 /etc/config/ip-masq-agent 重新加载其配置, 这也是可修改的。
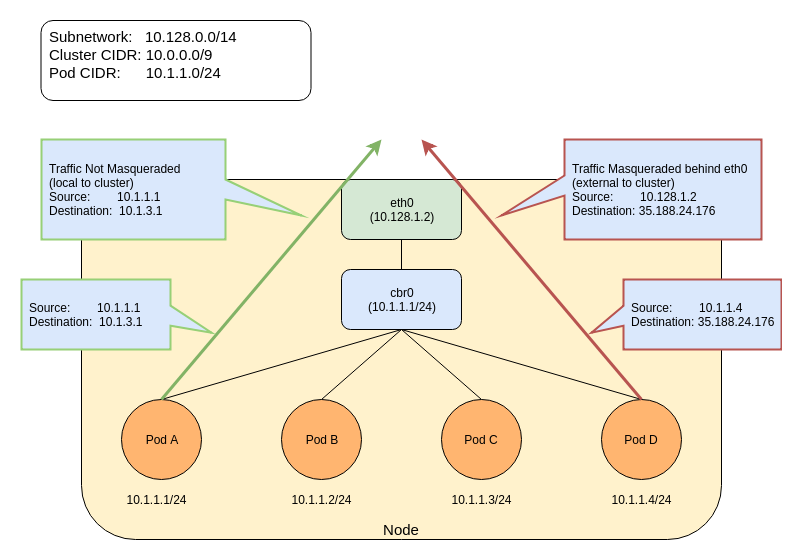
代理配置文件必须使用 YAML 或 JSON 语法编写,并且可能包含三个可选值:
- nonMasqueradeCIDRs: CIDR 表示法中的字符串列表,用于指定不需伪装的地址范围。
- masqLinkLocal: 布尔值 (true / false),表示是否将流量伪装到 本地链路前缀 169.254.0.0/16。默认为 false。
- resyncInterval: 代理尝试从磁盘重新加载配置的时间间隔。 例如 '30s',其中 's' 是秒,'ms' 是毫秒等...
10.0.0.0/8、172.16.0.0/12 和 192.168.0.0/16 范围内的流量不会被伪装。 任何其他流量(假设是互联网)将被伪装。 Pod 访问本地目的地的例子,可以是其节点的 IP 地址、另一节点的地址或集群的 IP 地址范围内的一个 IP 地址。 默认情况下,任何其他流量都将伪装。以下条目展示了 ip-masq-agent 的默认使用的规则:
iptables -t nat -L IP-MASQ-AGENT
RETURN all -- anywhere 169.254.0.0/16 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 10.0.0.0/8 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 172.16.0.0/12 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 192.168.0.0/16 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
MASQUERADE all -- anywhere anywhere /* ip-masq-agent: outbound traffic should be subject to MASQUERADE (this match must come after cluster-local CIDR matches) */ ADDRTYPE match dst-type !LOCAL
默认情况下,从 Kubernetes 1.7.0 版本开始的 GCE/Google Kubernetes Engine 中, 如果启用了网络策略,或者你使用的集群 CIDR 不在 10.0.0.0/8 范围内, 则 ip-masq-agent 将在你的集群中运行。 如果你在其他环境中运行,则可以将 ip-masq-agent DaemonSet 添加到你的集群:
创建 ip-masq-agent
通过运行以下 kubectl 指令创建 ip-masq-agent:
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/ip-masq-agent/master/ip-masq-agent.yaml
你必须同时将适当的节点标签应用于集群中希望代理运行的任何节点。
kubectl label nodes my-node beta.kubernetes.io/masq-agent-ds-ready=true
更多信息可以通过 ip-masq-agent 文档 这里 找到。
在大多数情况下,默认的规则集应该足够;但是,如果你的群集不是这种情况,则可以创建并应用 ConfigMap 来自定义受影响的 IP 范围。 例如,要允许 ip-masq-agent 仅作用于 10.0.0.0/8,你可以在一个名为 “config” 的文件中创建以下 ConfigMap 。
重要的是,该文件之所以被称为 config,因为默认情况下,该文件将被用作 ip-masq-agent 查找的主键:
nonMasqueradeCIDRs:
- 10.0.0.0/8
resyncInterval: 60s
运行以下命令将配置映射添加到你的集群:
kubectl create configmap ip-masq-agent --from-file=config --namespace=kube-system
这将更新位于 /etc/config/ip-masq-agent 的一个文件,该文件以 resyncInterval 为周期定期检查并应用于集群节点。 重新同步间隔到期后,你应该看到你的更改在 iptables 规则中体现:
iptables -t nat -L IP-MASQ-AGENT
Chain IP-MASQ-AGENT (1 references)
target prot opt source destination
RETURN all -- anywhere 169.254.0.0/16 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 10.0.0.0/8 /* ip-masq-agent: cluster-local
MASQUERADE all -- anywhere anywhere /* ip-masq-agent: outbound traffic should be subject to MASQUERADE (this match must come after cluster-local CIDR matches) */ ADDRTYPE match dst-type !LOCAL
默认情况下,本地链路范围 (169.254.0.0/16) 也由 ip-masq agent 处理, 该代理设置适当的 iptables 规则。 要使 ip-masq-agent 忽略本地链路, 可以在配置映射中将 masqLinkLocal 设置为 true。
nonMasqueradeCIDRs:
- 10.0.0.0/8
resyncInterval: 60s
masqLinkLocal: true
7 - Kubernetes 云管理控制器
Kubernetes v1.11 [beta]
由于云驱动的开发和发布的步调与 Kubernetes 项目不同,将服务提供商专用代码抽象到
cloud-controller-manager
二进制中有助于云服务厂商在 Kubernetes 核心代码之外独立进行开发。
cloud-controller-manager 可以被链接到任何满足
cloudprovider.Interface
约束的云服务提供商。为了兼容旧版本,Kubernetes 核心项目中提供的
cloud-controller-manager
使用和 kube-controller-manager 相同的云服务类库。
已经在 Kubernetes 核心项目中支持的云服务提供商预计将通过使用 in-tree 的 cloud-controller-manager
过渡为非 Kubernetes 核心代码。
管理
需求
每个云服务都有一套各自的需求用于系统平台的集成,这不应与运行
kube-controller-manager 的需求有太大差异。作为经验法则,你需要:
- 云服务认证/授权:你的云服务可能需要使用令牌或者 IAM 规则以允许对其 API 的访问
- kubernetes 认证/授权:cloud-controller-manager 可能需要 RBAC 规则以访问 kubernetes apiserver
- 高可用:类似于 kube-controller-manager,你可能希望通过主节点选举(默认开启)配置一个高可用的云管理控制器。
运行云管理控制器
你需要对集群配置做适当的修改以成功地运行云管理控制器:
- 一定不要为
kube-apiserver和kube-controller-manager指定--cloud-provider标志。 这将保证它们不会运行任何云服务专用循环逻辑,这将会由云管理控制器运行。未来这个标记将被废弃并去除。 kubelet必须使用--cloud-provider=external运行。 这是为了保证让 kubelet 知道在执行任何任务前,它必须被云管理控制器初始化。
请记住,设置群集使用云管理控制器将用多种方式更改群集行为:
- 指定了
--cloud-provider=external的 kubelet 将被添加一个node.cloudprovider.kubernetes.io/uninitialized的污点,导致其在初始化过程中不可调度(NoSchedule)。 这将标记该节点在能够正常调度前,需要外部的控制器进行二次初始化。 请注意,如果云管理控制器不可用,集群中的新节点会一直处于不可调度的状态。 这个污点很重要,因为调度器可能需要关于节点的云服务特定的信息,比如他们的区域或类型 (高端 CPU、GPU 支持、内存较大、临时实例等)。
- 集群中节点的云服务信息将不再能够从本地元数据中获取,取而代之的是所有获取节点信息的 API 调用都将通过云管理控制器。这意味着你可以通过限制到 kubelet 云服务 API 的访问来提升安全性。 在更大的集群中你可能需要考虑云管理控制器是否会遇到速率限制, 因为它现在负责集群中几乎所有到云服务的 API 调用。
云管理控制器可以实现:
- 节点控制器 - 负责使用云服务 API 更新 kubernetes 节点并删除在云服务上已经删除的 kubernetes 节点。
- 服务控制器 - 负责在云服务上为类型为 LoadBalancer 的 service 提供负载均衡器。
- 路由控制器 - 负责在云服务上配置网络路由。
- 如果你使用的是 out-of-tree 提供商,请按需实现其余任意特性。
示例
如果当前 Kubernetes 内核支持你使用的云服务,并且想要采用云管理控制器,请参见 kubernetes 内核中的云管理控制器。
对于不在 Kubernetes 核心代码库中的云管理控制器,你可以在云服务厂商或 SIG 领导者的源中找到对应的项目。
对于已经存在于 Kubernetes 内核中的提供商,你可以在集群中将 in-tree 云管理控制器作为守护进程运行。请使用如下指南:
# This is an example of how to setup cloud-controller-manager as a Daemonset in your cluster.
# It assumes that your masters can run pods and has the role node-role.kubernetes.io/master
# Note that this Daemonset will not work straight out of the box for your cloud, this is
# meant to be a guideline.
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:cloud-controller-manager
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
k8s-app: cloud-controller-manager
name: cloud-controller-manager
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: cloud-controller-manager
template:
metadata:
labels:
k8s-app: cloud-controller-manager
spec:
serviceAccountName: cloud-controller-manager
containers:
- name: cloud-controller-manager
# for in-tree providers we use k8s.gcr.io/cloud-controller-manager
# this can be replaced with any other image for out-of-tree providers
image: k8s.gcr.io/cloud-controller-manager:v1.8.0
command:
- /usr/local/bin/cloud-controller-manager
- --cloud-provider=[YOUR_CLOUD_PROVIDER] # Add your own cloud provider here!
- --leader-elect=true
- --use-service-account-credentials
# these flags will vary for every cloud provider
- --allocate-node-cidrs=true
- --configure-cloud-routes=true
- --cluster-cidr=172.17.0.0/16
tolerations:
# this is required so CCM can bootstrap itself
- key: node.cloudprovider.kubernetes.io/uninitialized
value: "true"
effect: NoSchedule
# this is to have the daemonset runnable on master nodes
# the taint may vary depending on your cluster setup
- key: node-role.kubernetes.io/master
effect: NoSchedule
# this is to restrict CCM to only run on master nodes
# the node selector may vary depending on your cluster setup
nodeSelector:
node-role.kubernetes.io/master: ""
限制
运行云管理控制器会有一些可能的限制。虽然以后的版本将处理这些限制,但是知道这些生产负载的限制很重要。
对 Volume 的支持
云管理控制器未实现 kube-controller-manager 中的任何 volume 控制器,因为和 volume 的集成还需要与 kubelet 协作。由于我们引入了 CSI (容器存储接口,container storage interface) 并对弹性 volume 插件添加了更强大的支持,云管理控制器将添加必要的支持,以使云服务同 volume 更好的集成。请在 这里 了解更多关于 out-of-tree CSI volume 插件的信息。
可扩展性
在以前为云服务提供商提供的架构中,我们依赖 kubelet 的本地元数据服务来获取关于它本身的节点信息。通过这个新的架构,现在我们完全依赖云管理控制器来获取所有节点的信息。对于非常大的集群,你需要考虑可能的瓶颈,例如资源需求和 API 速率限制。
鸡和蛋的问题
云管理控制器的目标是将云服务特性的开发从 Kubernetes 核心项目中解耦。 不幸的是,Kubernetes 项目的许多方面都假设云服务提供商的特性同项目紧密结合。 因此,这种新架构的采用可能导致某些场景下,当一个请求需要从云服务提供商获取信息时, 在该请求没有完成的情况下云管理控制器不能返回那些信息。
Kubelet 中的 TLS 引导特性是一个很好的例子。 目前,TLS 引导认为 kubelet 有能力从云提供商(或本地元数据服务)获取所有的地址类型(私有、公用等), 但在被初始化之前,云管理控制器不能设置节点地址类型,而这需要 kubelet 拥有 TLS 证书以和 API 服务器通信。
随着整个动议的演进,将来的发行版中将作出改变来解决这些问题。
接下来
要构建和开发你自己的云管理控制器,请阅读 开发云管理控制器 文档。
8 - 为 Kubernetes 运行 etcd 集群
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
您的 Kubernetes 集群的 etcd 数据库通常需要有个备份计划。
要了解 etcd 更深层次的信息,请参考 etcd 文档。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
先决条件
-
运行的 etcd 集群个数成员为奇数。
-
etcd 是一个 leader-based 分布式系统。确保主节点定期向所有从节点发送心跳,以保持集群稳定。
-
确保不发生资源不足。
集群的性能和稳定性对网络和磁盘 I/O 非常敏感。任何资源匮乏都会导致心跳超时, 从而导致集群的不稳定。不稳定的情况表明没有选出任何主节点。 在这种情况下,集群不能对其当前状态进行任何更改,这意味着不能调度新的 pod。
-
保持 etcd 集群的稳定对 Kubernetes 集群的稳定性至关重要。 因此,请在专用机器或隔离环境上运行 etcd 集群,以满足 所需资源需求。
-
在生产中运行的 etcd 的最低推荐版本是
3.2.10+。
资源要求
使用有限的资源运行 etcd 只适合测试目的。为了在生产中部署,需要先进的硬件配置。 在生产中部署 etcd 之前,请查看 所需资源参考文档。
启动 etcd 集群
本节介绍如何启动单节点和多节点 etcd 集群。
单节点 etcd 集群
只为测试目的使用单节点 etcd 集群。
-
运行以下命令:
etcd --listen-client-urls=http://$PRIVATE_IP:2379 \ --advertise-client-urls=http://$PRIVATE_IP:2379 -
使用参数
--etcd-servers=$PRIVATE_IP:2379启动 Kubernetes API 服务器。确保将
PRIVATE_IP设置为etcd客户端 IP。
多节点 etcd 集群
为了耐用性和高可用性,在生产中将以多节点集群的方式运行 etcd,并且定期备份。 建议在生产中使用五个成员的集群。 有关该内容的更多信息,请参阅 常见问题文档。
可以通过静态成员信息或动态发现的方式配置 etcd 集群。 有关集群的详细信息,请参阅 etcd 集群文档。
例如,考虑运行以下客户端 URL 的五个成员的 etcd 集群:http://$IP1:2379,
http://$IP2:2379,http://$IP3:2379,http://$IP4:2379 和 http://$IP5:2379。
要启动 Kubernetes API 服务器:
-
运行以下命令:
etcd --listen-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379 --advertise-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379 -
使用参数
--etcd-servers=$IP1:2379,$IP2:2379,$IP3:2379,$IP4:2379,$IP5:2379启动 Kubernetes API 服务器。确保将
IP<n>变量设置为客户端 IP 地址。
使用负载均衡的多节点 etcd 集群
要运行负载均衡的 etcd 集群:
- 建立一个 etcd 集群。
- 在 etcd 集群前面配置负载均衡器。例如,让负载均衡器的地址为
$LB。 - 使用参数
--etcd-servers=$LB:2379启动 Kubernetes API 服务器。
安全的 etcd 集群
对 etcd 的访问相当于集群中的 root 权限,因此理想情况下只有 API 服务器才能访问它。 考虑到数据的敏感性,建议只向需要访问 etcd 集群的节点授予权限。
想要确保 etcd 的安全,可以设置防火墙规则或使用 etcd 提供的安全特性,这些安全特性依赖于 x509 公钥基础设施(PKI)。
首先,通过生成密钥和证书对来建立安全的通信通道。
例如,使用密钥对 peer.key 和 peer.cert 来保护 etcd 成员之间的通信,
而 client.key 和 client.cert 用于保护 etcd 与其客户端之间的通信。
请参阅 etcd 项目提供的示例脚本,
以生成用于客户端身份验证的密钥对和 CA 文件。
安全通信
若要使用安全对等通信对 etcd 进行配置,请指定参数 --peer-key-file=peer.key
和 --peer-cert-file=peer.cert,并使用 HTTPS 作为 URL 模式。
类似地,要使用安全客户端通信对 etcd 进行配置,请指定参数 --key-file=k8sclient.key
和 --cert-file=k8sclient.cert,并使用 HTTPS 作为 URL 模式。
使用安全通信的客户端命令的示例:
ETCDCTL_API=3 etcdctl --endpoints 10.2.0.9:2379 \
--cert=/etc/kubernetes/pki/etcd/client.crt \
--key=/etc/kubernetes/pki/etcd/client.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
member list
限制 etcd 集群的访问
配置安全通信后,将 etcd 集群的访问限制在 Kubernetes API 服务器上。使用 TLS 身份验证来完成此任务。
例如,考虑由 CA etcd.ca 信任的密钥对 k8sclient.key 和 k8sclient.cert。
当 etcd 配置为 --client-cert-auth 和 TLS 时,它使用系统 CA 或由 --trusted-ca-file 参数传入的 CA 验证来自客户端的证书。
指定参数 --client-cert-auth=true 和 --trusted-ca-file=etcd.ca 将限制对具有证书 k8sclient.cert 的客户端的访问。
一旦正确配置了 etcd,只有具有有效证书的客户端才能访问它。要让 Kubernetes API 服务器访问,
可以使用参数 --etcd-certfile=k8sclient.cert,--etcd-keyfile=k8sclient.key 和 --etcd-cafile=ca.cert 配置。
替换失败的 etcd 成员
etcd 集群通过容忍少数成员故障实现高可用性。 但是,要改善集群的整体健康状况,请立即替换失败的成员。当多个成员失败时,逐个替换它们。 替换失败成员需要两个步骤:删除失败成员和添加新成员。
虽然 etcd 在内部保留唯一的成员 ID,但建议为每个成员使用唯一的名称,以避免人为错误。
例如,考虑一个三成员的 etcd 集群。让 URL 为:member1=http://10.0.0.1, member2=http://10.0.0.2
和 member3=http://10.0.0.3。当 member1 失败时,将其替换为 member4=http://10.0.0.4。
-
获取失败的
member1的成员 ID:etcdctl --endpoints=http://10.0.0.2,http://10.0.0.3 member list显示以下信息:
8211f1d0f64f3269, started, member1, http://10.0.0.1:2380, http://10.0.0.1:2379 91bc3c398fb3c146, started, member2, http://10.0.0.2:2380, http://10.0.0.2:2379 fd422379fda50e48, started, member3, http://10.0.0.3:2380, http://10.0.0.3:2379 -
移除失败的成员
etcdctl member remove 8211f1d0f64f3269显示以下信息:
Removed member 8211f1d0f64f3269 from cluster -
增加新成员:
etcdctl member add member4 --peer-urls=http://10.0.0.4:2380显示以下信息:
Member 2be1eb8f84b7f63e added to cluster ef37ad9dc622a7c4 -
在 IP 为
10.0.0.4的机器上启动新增加的成员:export ETCD_NAME="member4" export ETCD_INITIAL_CLUSTER="member2=http://10.0.0.2:2380,member3=http://10.0.0.3:2380,member4=http://10.0.0.4:2380" export ETCD_INITIAL_CLUSTER_STATE=existing etcd [flags] -
做以下事情之一:
- 更新 Kubernetes API 服务器的
--etcd-servers参数,使 Kubernetes 知道配置进行了更改,然后重新启动 Kubernetes API 服务器。 - 如果在 deployment 中使用了负载均衡,更新负载均衡配置。
- 更新 Kubernetes API 服务器的
有关集群重新配置的详细信息,请参阅 etcd 重构文档。
备份 etcd 集群
所有 Kubernetes 对象都存储在 etcd 上。定期备份 etcd 集群数据对于在灾难场景(例如丢失所有控制平面节点)下恢复 Kubernetes 集群非常重要。 快照文件包含所有 Kubernetes 状态和关键信息。为了保证敏感的 Kubernetes 数据的安全,可以对快照文件进行加密。
备份 etcd 集群可以通过两种方式完成:etcd 内置快照和卷快照。
内置快照
etcd 支持内置快照。快照可以从使用 etcdctl snapshot save 命令的活动成员中获取,
也可以通过从 etcd 数据目录
复制 member/snap/db 文件,该 etcd 数据目录目前没有被 etcd 进程使用。获取快照不会影响成员的性能。
下面是一个示例,用于获取 $ENDPOINT 所提供的键空间的快照到文件 snapshotdb:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshotdb
验证快照:
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshotdb
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
卷快照
如果 etcd 运行在支持备份的存储卷(如 Amazon Elastic Block 存储)上,则可以通过获取存储卷的快照来备份 etcd 数据。
使用 etcdctl 选项的快照
我们还可以使用 etcdctl 提供的各种选项来拍摄快照。例如:
ETCDCTL_API=3 etcdctl -h
列出 etcdctl 可用的各种选项。例如,你可以通过指定端点,证书等来拍摄快照,如下所示:
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \
snapshot save <backup-file-location>
可以从 etcd Pod 的描述中获得 trusted-ca-file, cert-file 和 key-file 。
扩展 etcd 集群
通过交换性能,扩展 etcd 集群可以提高可用性。缩放不会提高集群性能和能力。 一般情况下不要扩大或缩小 etcd 集群的集合。不要为 etcd 集群配置任何自动缩放组。 强烈建议始终在任何官方支持的规模上运行生产 Kubernetes 集群时使用静态的五成员 etcd 集群。
合理的扩展是在需要更高可靠性的情况下,将三成员集群升级为五成员集群。 请参阅 etcd 重新配置文档 以了解如何将成员添加到现有集群中的信息。
恢复 etcd 集群
etcd 支持从 major.minor 或其他不同 patch 版本的 etcd 进程中获取的快照进行恢复。 还原操作用于恢复失败的集群的数据。
在启动还原操作之前,必须有一个快照文件。它可以是来自以前备份操作的快照文件, 也可以是来自剩余数据目录的快照文件。 例如:
ETCDCTL_API=3 etcdctl --endpoints 10.2.0.9:2379 snapshot restore snapshotdb
恢复时也可以指定操作选项,例如:
ETCDCTL_API=3 etcdctl --data-dir <data-dir-location> snapshot restore snapshotdb
有关从快照文件还原集群的详细信息和示例,请参阅 etcd 灾难恢复文档。
如果还原的集群的访问 URL 与前一个集群不同,则必须相应地重新配置 Kubernetes API 服务器。
在本例中,使用参数 --etcd-servers=$NEW_ETCD_CLUSTER 而不是参数 --etcd-servers=$OLD_ETCD_CLUSTER 重新启动 Kubernetes API 服务器。
用相应的 IP 地址替换 $NEW_ETCD_CLUSTER 和 $OLD_ETCD_CLUSTER。如果在 etcd 集群前面使用负载平衡,则可能需要更新负载均衡器。
如果大多数 etcd 成员永久失败,则认为 etcd 集群失败。在这种情况下,Kubernetes 不能对其当前状态进行任何更改。 虽然已调度的 pod 可能继续运行,但新的 pod 无法调度。在这种情况下,恢复 etcd 集群并可能需要重新配置 Kubernetes API 服务器以修复问题。
如果集群中正在运行任何 API 服务器,则不应尝试还原 etcd 的实例。相反,请按照以下步骤还原 etcd:
- 停止 所有 API 服务实例
- 在所有 etcd 实例中恢复状态
- 重启所有 API 服务实例
我们还建议重启所有组件(例如 kube-scheduler、kube-controller-manager、kubelet),以确保它们不会
依赖一些过时的数据。请注意,实际中还原会花费一些时间。
在还原过程中,关键组件将丢失领导锁并自行重启。
9 - 为系统守护进程预留计算资源
Kubernetes 的节点可以按照 Capacity 调度。默认情况下 pod 能够使用节点全部可用容量。
这是个问题,因为节点自己通常运行了不少驱动 OS 和 Kubernetes 的系统守护进程。
除非为这些系统守护进程留出资源,否则它们将与 pod 争夺资源并导致节点资源短缺问题。
kubelet 公开了一个名为 'Node Allocatable' 的特性,有助于为系统守护进程预留计算资源。
Kubernetes 推荐集群管理员按照每个节点上的工作负载密度配置 Node Allocatable。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
您的 Kubernetes 服务器版本必须不低于版本 1.8. 要获知版本信息,请输入kubectl version.
您的 kubernetes 服务器版本必须至少是 1.17 版本,才能使用 kubelet
命令行选项 --reserved-cpus 设置
显式预留 CPU 列表。
节点可分配

Kubernetes 节点上的 'Allocatable' 被定义为 pod 可用计算资源量。 调度器不会超额申请 'Allocatable'。 目前支持 'CPU', 'memory' 和 'ephemeral-storage' 这几个参数。
可分配的节点暴露为 API 中 v1.Node 对象的一部分,也是 CLI 中
kubectl describe node 的一部分。
在 kubelet 中,可以为两类系统守护进程预留资源。
启用 QoS 和 Pod 级别的 cgroups
为了恰当的在节点范围实施节点可分配约束,你必须通过 --cgroups-per-qos
标志启用新的 cgroup 层次结构。这个标志是默认启用的。
启用后,kubelet 将在其管理的 cgroup 层次结构中创建所有终端用户的 Pod。
配置 cgroup 驱动
kubelet 支持在主机上使用 cgroup 驱动操作 cgroup 层次结构。
驱动通过 --cgroup-driver 标志配置。
支持的参数值如下:
cgroupfs是默认的驱动,在主机上直接操作 cgroup 文件系统以对 cgroup 沙箱进行管理。systemd是可选的驱动,使用 init 系统支持的资源的瞬时切片管理 cgroup 沙箱。
取决于相关容器运行时的配置,操作员可能需要选择一个特定的 cgroup 驱动
来保证系统正常运行。
例如,如果操作员使用 docker 运行时提供的 systemd cgroup 驱动时,
必须配置 kubelet 使用 systemd cgroup 驱动。
Kube 预留值
- Kubelet 标志:
--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000] - Kubelet 标志:
--kube-reserved-cgroup=
kube-reserved 用来给诸如 kubelet、容器运行时、节点问题监测器等
kubernetes 系统守护进程记述其资源预留值。
该配置并非用来给以 Pod 形式运行的系统守护进程保留资源。kube-reserved
通常是节点上 pod 密度 的函数。
除了 cpu,内存 和 ephemeral-storage 之外,pid 可用来指定为
kubernetes 系统守护进程预留指定数量的进程 ID。
要选择性地对 kubernetes 系统守护进程上执行 kube-reserved 保护,需要把 kubelet 的
--kube-reserved-cgroup 标志的值设置为 kube 守护进程的父控制组。
推荐将 kubernetes 系统守护进程放置于顶级控制组之下(例如 systemd 机器上的
runtime.slice)。
理想情况下每个系统守护进程都应该在其自己的子控制组中运行。
请参考
这个设计方案,
进一步了解关于推荐控制组层次结构的细节。
请注意,如果 --kube-reserved-cgroup 不存在,Kubelet 将 不会 创建它。
如果指定了一个无效的 cgroup,Kubelet 将会失败。
系统预留值
- Kubelet 标志:
--system-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000] - Kubelet 标志:
--system-reserved-cgroup=
system-reserved 用于为诸如 sshd、udev 等系统守护进程记述其资源预留值。
system-reserved 也应该为 kernel 预留 内存,因为目前 kernel
使用的内存并不记在 Kubernetes 的 Pod 上。
同时还推荐为用户登录会话预留资源(systemd 体系中的 user.slice)。
除了 cpu,内存 和 ephemeral-storage 之外,pid 可用来指定为
kubernetes 系统守护进程预留指定数量的进程 ID。
要想为系统守护进程上可选地实施 system-reserved 约束,请指定 kubelet 的
--system-reserved-cgroup 标志值为 OS 系统守护进程的父级控制组。
推荐将 OS 系统守护进程放在一个顶级控制组之下(例如 systemd 机器上的
system.slice)。
请注意,如果 --system-reserved-cgroup 不存在,kubelet 不会 创建它。
如果指定了无效的 cgroup,kubelet 将会失败。
显式保留的 CPU 列表
Kubernetes v1.17 [stable]
-Kubelet 标志: --reserved-cpus=0-3
reserved-cpus 旨在为操作系统守护程序和 kubernetes 系统守护程序保留一组明确指定编号的
CPU。reserved-cpus 适用于不打算针对 cpuset 资源为操作系统守护程序和 kubernetes
系统守护程序定义独立的顶级 cgroups 的系统。
如果 Kubelet 没有 指定参数 --system-reserved-cgroup 和 --kube-reserved-cgroup,
则 reserved-cpus 的设置将优先于 --kube-reserved 和 --system-reserved 选项。
此选项是专门为电信/NFV 用例设计的,在这些用例中不受控制的中断或计时器可能会 影响其工作负载性能。 你可以使用此选项为系统或 kubernetes 守护程序以及中断或计时器显式定义 cpuset, 这样系统上的其余 CPU 可以专门用于工作负载,因不受控制的中断或计时器的影响得以 降低。 要将系统守护程序、kubernetes 守护程序和中断或计时器移动到此选项定义的显式 cpuset 上,应使用 Kubernetes 之外的其他机制。 例如:在 Centos 系统中,可以使用 tuned 工具集来执行此操作。
驱逐阈值
- Kubelet 标志:
--eviction-hard=[memory.available<500Mi]
节点级别的内存压力将导致系统内存不足,这将影响到整个节点及其上运行的所有 Pod。
节点可以暂时离线直到内存已经回收为止。
为了防止(或减少可能性)系统内存不足,kubelet 提供了
资源不足管理。
驱逐操作只支持 memory 和 ephemeral-storage。
通过 --eviction-hard 标志预留一些内存后,当节点上的可用内存降至保留值以下时,
kubelet 将尝试驱逐 Pod。
如果节点上不存在系统守护进程,Pod 将不能使用超过 capacity-eviction-hard 所
指定的资源量。因此,为驱逐而预留的资源对 Pod 是不可用的。
实施节点可分配约束
-Kubelet 标志: --enforce-node-allocatable=pods[,][system-reserved][,][kube-reserved]
调度器将 'Allocatable' 视为 Pod 可用的 capacity(资源容量)。
kubelet 默认对 Pod 执行 'Allocatable' 约束。
无论何时,如果所有 Pod 的总用量超过了 'Allocatable',驱逐 Pod 的措施将被执行。
有关驱逐策略的更多细节可以在
节点压力驱逐页找到。
可通过设置 kubelet --enforce-node-allocatable 标志值为 pods 控制这个措施。
可选地,通过在同一标志中同时指定 kube-reserved 和 system-reserved 值,
可以使 kubelet 强制实施 kube-reserved 和 system-reserved约束。
请注意,要想执行 kube-reserved 或者 system-reserved 约束,
需要对应设置 --kube-reserved-cgroup 或者 --system-reserved-cgroup。
一般原则
系统守护进程一般会被按照类似 'Guaranteed' Pod 一样对待。
系统守护进程可以在与其对应的控制组中出现突发资源用量,这一行为要作为
kubernetes 部署的一部分进行管理。
例如,kubelet 应该有它自己的控制组并和容器运行时共享 Kube-reserved 资源。
不过,如果执行了 kube-reserved 约束,则 kubelet 不可出现突发负载并用光
节点的所有可用资源。
在执行 system-reserved 预留策略时请加倍小心,因为它可能导致节点上的
关键系统服务出现 CPU 资源短缺、因为内存不足而被终止或者无法在节点上创建进程。
建议只有当用户详尽地描述了他们的节点以得出精确的估计值,
并且对该组中进程因内存不足而被杀死时,有足够的信心将其恢复时,
才可以强制执行 system-reserved 策略。
- 作为起步,可以先针对
pods上执行 'Allocatable' 约束。 - 一旦用于追踪系统守护进程的监控和告警的机制到位,可尝试基于用量估计的
方式执行
kube-reserved策略。 - 随着时间推进,在绝对必要的时候可以执行
system-reserved策略。
随着时间推进和越来越多特性被加入,kube 系统守护进程对资源的需求可能也会增加。
以后 kubernetes 项目将尝试减少对节点系统守护进程的利用,但目前这件事的优先级
并不是最高。
所以,将来的发布版本中 Allocatable 容量是有可能降低的。
示例场景
这是一个用于说明节点可分配(Node Allocatable)计算方式的示例:
- 节点拥有
32Gimemeory,16 CPU和100GiStorage资源 --kube-reserved被设置为cpu=1,memory=2Gi,ephemeral-storage=1Gi--system-reserved被设置为cpu=500m,memory=1Gi,ephemeral-storage=1Gi--eviction-hard被设置为memory.available<500Mi,nodefs.available<10%
在这个场景下,'Allocatable' 将会是 14.5 CPUs、28.5Gi 内存以及 88Gi 本地存储。
调度器保证这个节点上的所有 Pod 的内存 requests 总量不超过 28.5Gi,
存储不超过 '88Gi'。
当 Pod 的内存使用总量超过 28.5Gi 或者磁盘使用总量超过 88Gi 时,
kubelet 将会驱逐它们。
如果节点上的所有进程都尽可能多地使用 CPU,则 Pod 加起来不能使用超过
14.5 CPUs 的资源。
当没有执行 kube-reserved 和/或 system-reserved 策略且系统守护进程
使用量超过其预留时,如果节点内存用量高于 31.5Gi 或存储大于 90Gi,
kubelet 将会驱逐 Pod。
10 - 为节点发布扩展资源
本文展示了如何为节点指定扩展资源(Extended Resource)。 扩展资源允许集群管理员发布节点级别的资源,这些资源在不进行发布的情况下无法被 Kubernetes 感知。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
获取你的节点名称
kubectl get nodes
选择一个节点用于此练习。
在你的一个节点上发布一种新的扩展资源
为在一个节点上发布一种新的扩展资源,需要发送一个 HTTP PATCH 请求到 Kubernetes API server。 例如:假设你的一个节点上带有四个 dongle 资源。 下面是一个 PATCH 请求的示例,该请求为你的节点发布四个 dongle 资源。
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "add",
"path": "/status/capacity/example.com~1dongle",
"value": "4"
}
]
注意:Kubernetes 不需要了解 dongle 资源的含义和用途。 前面的 PATCH 请求告诉 Kubernetes 你的节点拥有四个你称之为 dongle 的东西。
启动一个代理(proxy),以便你可以很容易地向 Kubernetes API server 发送请求:
kubectl proxy
在另一个命令窗口中,发送 HTTP PATCH 请求。 用你的节点名称替换 <your-node-name>:
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
~1 为 patch 路径中 “/” 符号的编码。
JSON-Patch 中的操作路径值被解析为 JSON 指针。
更多细节,请查看 IETF RFC 6901 的第 3 节。
输出显示该节点的 dongle 资源容量(capacity)为 4:
"capacity": {
"cpu": "2",
"memory": "2049008Ki",
"example.com/dongle": "4",
描述你的节点:
kubectl describe node <your-node-name>
输出再次展示了 dongle 资源:
Capacity:
cpu: 2
memory: 2049008Ki
example.com/dongle: 4
现在,应用开发者可以创建请求一定数量 dongle 资源的 Pod 了。 参见将扩展资源分配给容器。
讨论
扩展资源类似于内存和 CPU 资源。例如,正如一个节点拥有一定数量的内存和 CPU 资源, 它们被节点上运行的所有组件共享,该节点也可以拥有一定数量的 dongle 资源, 这些资源同样被节点上运行的所有组件共享。 此外,正如应用开发者可以创建请求一定数量的内存和 CPU 资源的 Pod, 他们也可以创建请求一定数量 dongle 资源的 Pod。
扩展资源对 Kubernetes 是不透明的。Kubernetes 不知道扩展资源含义相关的任何信息。 Kubernetes 只了解一个节点拥有一定数量的扩展资源。 扩展资源必须以整形数量进行发布。 例如,一个节点可以发布 4 个 dongle 资源,但是不能发布 4.5 个。
存储示例
假设一个节点拥有一种特殊类型的磁盘存储,其容量为 800 GiB。
你可以为该特殊存储创建一个名称,如 example.com/special-storage。
然后你就可以按照一定规格的块(如 100 GiB)对其进行发布。
在这种情况下,你的节点将会通知它拥有八个 example.com/special-storage 类型的资源。
Capacity:
...
example.com/special-storage: 8
如果你想要允许针对特殊存储任意(数量)的请求,你可以按照 1 字节大小的块来发布特殊存储。 在这种情况下,你将会发布 800Gi 数量的 example.com/special-storage 类型的资源。
Capacity:
...
example.com/special-storage: 800Gi
然后,容器就能够请求任意数量(多达 800Gi)字节的特殊存储。
Capacity:
...
example.com/special-storage: 800Gi
清理
这里是一个从节点移除 dongle 资源发布的 PATCH 请求。
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "remove",
"path": "/status/capacity/example.com~1dongle",
}
]
启动一个代理,以便你可以很容易地向 Kubernetes API 服务器发送请求:
kubectl proxy
在另一个命令窗口中,发送 HTTP PATCH 请求。用你的节点名称替换 <your-node-name>:
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "remove", "path": "/status/capacity/example.com~1dongle"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
验证 dongle 资源的发布已经被移除:
kubectl describe node <your-node-name> | grep dongle
(你应该看不到任何输出)
接下来
针对应用开发人员
针对集群管理员
11 - 以非root用户身份运行 Kubernetes 节点组件
Kubernetes v1.22 [alpha]
这个文档描述了怎样不使用 root 特权,而是通过使用 用户命名空间 去运行 Kubernetes 节点组件(例如 kubelet、CRI、OCI、CNI)。
这种技术也叫做 rootless 模式(Rootless mode)。
如果你只是想了解如何以非 root 身份运行 Pod,请参阅 SecurityContext。
准备开始
您的 Kubernetes 服务器版本必须不低于版本 1.22.
要获知版本信息,请输入 kubectl version.
- 启用 Cgroup v2
- 在 systemd 中启用 user session
- 根据不同的 Linux 发行版,配置 sysctl 的值
- 确保你的非特权用户被列在
/etc/subuid和/etc/subgid文件中 - 启用
KubeletInUserNamespace特性门控
使用 Rootless 模式的 Docker/Podman 运行 Kubernetes
kind
kind 支持使用 Rootless 模式的 Docker 或者 Podman 运行 Kubernetes。
请参阅使用 Rootless 模式的 Docker 运行 kind。
minikube
minikube 也支持使用 Rootless 模式的 Docker 运行 Kubernetes。
请参阅 Minikube 文档中的 docker 驱动页面。
它不支持 Rootless 模式的 Podman。
直接在主机上运行 Rootless 模式的 Kubernetes
K3s
K3s 实验性支持了 Rootless 模式。
请参阅使用 Rootless 模式运行 K3s 页面中的用法.
Usernetes
Usernetes 是 Kubernetes 的一个参考发行版,
它可以在不使用 root 特权的情况下安装在 $HOME 目录下。
Usernetes 支持使用 containerd 和 CRI-O 作为 CRI 运行时。 Usernetes 支持配置了 Flannel (VXLAN)的多节点集群。
关于用法,请参阅 Usernetes 仓库。
手动部署一个在用户命名空间运行 kubelet 的节点
本节提供在用户命名空间手动运行 Kubernetes 的注意事项。
创建用户命名空间
第一步是创建一个 用户命名空间。
如果你正在尝试使用用户命名空间的容器(例如 Rootless 模式的 Docker/Podman 或 LXC/LXD) 运行 Kubernetes,那么你已经准备就绪,可以直接跳到下一小节。
否则你需要通过传递参数 CLONE_NEWUSER 调用 unshare(2),自己创建一个命名空间。
用户命名空间也可以通过如下所示的命令行工具取消共享:
在取消命名空间的共享之后,你也必须对其它的命名空间例如 mount 命名空间取消共享。
在取消 mount 命名空间的共享之后,你不需要调用 chroot() 或者 pivot_root(),
但是你必须在这个命名空间内挂载可写的文件系统到几个目录上。
请确保这个命名空间内(不是这个命名空间外部)至少以下几个目录是可写的:
/etc/run/var/logs/var/lib/kubelet/var/lib/cni/var/lib/containerd(参照 containerd )/var/lib/containers(参照 CRI-O )
创建委派 cgroup 树
除了用户命名空间,你也需要有一个版本为 cgroup v2 的可写 cgroup 树。
如果你在一个采用 systemd 机制的主机上使用用户命名空间的容器(例如 Rootless 模式的 Docker/Podman 或 LXC/LXD)来运行 Kubernetes,那么你已经准备就绪。
否则你必须创建一个具有 Delegate=yes 属性的 systemd 单元,来委派一个具有可写权限的 cgroup 树。
在你的节点上,systemd 必须已经配置为允许委派。更多细节请参阅 Rootless 容器文档的 cgroup v2 部分。
配置网络
节点组件的网络命名空间必须有一个非本地回路的网卡。它可以使用 slirp4netns、 VPNKit、 lxc-user-nic(1) 等工具进行配置。
Pod 的网络命名空间可以使用常规的 CNI 插件配置。对于多节点的网络,已知 Flannel (VXLAN、8472/UDP) 可以正常工作。
诸如 kubelet 端口(10250/TCP)和 NodePort 服务端口之类的端口必须通过外部端口转发器
(例如 RootlessKit、 slirp4netns 或
socat(1)) 从节点网络命名空间暴露给主机。
你可以使用 K3s 的端口转发器。更多细节请参阅 在 Rootless 模式下运行 K3s。
配置 CRI
kubelet 依赖于容器运行时。你需要部署一个容器运行时(例如 containerd 或 CRI-O), 并确保它在 kubelet 启动之前已经在用户命名空间内运行。
containerd 1.4 开始支持在用户命名空间运行 containerd 的 CRI 插件。
在用户命名空间运行 containerd 需要在 /etc/containerd/containerd-config.toml 文件包含以下配置:
version = 2
[plugins."io.containerd.grpc.v1.cri"]
# 禁用 AppArmor
disable_apparmor = true
# 忽略配置 oom_score_adj 时的错误
restrict_oom_score_adj = true
# 禁用 hugetlb cgroup v2 控制器(因为 systemd 不支持委派 hugetlb controller)
disable_hugetlb_controller = true
[plugins."io.containerd.grpc.v1.cri".containerd]
# 如果内核 >= 5.11 , 也可以使用 non-fuse overlayfs, 但需要禁用 SELinux
snapshotter = "fuse-overlayfs"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
# 我们使用的 cgroupfs 已经被 systemd 委派,所以我们不使用 SystemdCgroup 驱动
# (除非你在命名空间内运行了另一个 systemd)
SystemdCgroup = false
CRI-O 1.22 开始支持在用户命名空间运行 CRI-O。
CRI-O 必须配置一个环境变量 _CRIO_ROOTLESS=1。
也推荐使用 /etc/crio/crio.conf 文件内的以下配置:
[crio]
storage_driver = "overlay"
# 如果内核 >= 5.11 , 也可以使用 non-fuse overlayfs, 但需要禁用 SELinux
storage_option = ["overlay.mount_program=/usr/local/bin/fuse-overlayfs"]
[crio.runtime]
# 我们使用的 cgroupfs 已经被 systemd 委派,所以我们不使用 "systemd" 驱动
# (除非你在命名空间内运行了另一个 systemd)
cgroup_manager = "cgroupfs"
配置 kubelet
在用户命名空间运行 kubelet 必须进行如下配置:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
KubeletInUserNamespace: true
# 我们使用的 cgroupfs 已经被 systemd 委派,所以我们不使用 "systemd" 驱动
# (除非你在命名空间内运行了另一个 systemd)
cgroupDriver: "cgroupfs"
当 KubeletInUserNamespace 特性门控被启用时, kubelet 会忽略节点内由于配置如下几个 sysctl
参数值而可能产生的错误。
vm.overcommit_memoryvm.panic_on_oomkernel.panickernel.panic_on_oopskernel.keys.root_maxkeyskernel.keys.root_maxbytes.
在用户命名空间内, kubelet 也会忽略任何由于打开 /dev/kmsg 而产生的错误。
这个特性门控也允许 kube-proxy 忽略由于配置 RLIMIT_NOFILE 而产生的一个错误。
KubeletInUserNamespace 特性门控从 Kubernetes v1.22 被引入, 标记为 "alpha" 状态。
通过挂载特制的 proc 文件系统,也可以在不使用这个特性门控的情况下在用户命名空间运行 kubelet,但这不受官方支持。
配置 kube-proxy
在用户命名空间运行 kube-proxy 需要进行以下配置:
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "iptables" # or "userspace"
conntrack:
# 跳过配置 sysctl 的值 "net.netfilter.nf_conntrack_max"
maxPerCore: 0
# 跳过配置 "net.netfilter.nf_conntrack_tcp_timeout_established"
tcpEstablishedTimeout: 0s
# 跳过配置 "net.netfilter.nf_conntrack_tcp_timeout_close"
tcpCloseWaitTimeout: 0s
注意事项
-
大部分“非本地”的卷驱动(例如
nfs和iscsi)不能正常工作。 已知诸如local、hostPath、emptyDir、configMap、secret和downwardAPI这些本地卷是能正常工作的。 -
一些 CNI 插件可能不正常工作。已知 Flannel (VXLAN) 是能正常工作的。
更多细节请参阅 rootlesscontaine.rs 站点的 Caveats and Future work 页面。
另请参见
12 - 使用 CoreDNS 进行服务发现
此页面介绍了 CoreDNS 升级过程以及如何安装 CoreDNS 而不是 kube-dns。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
您的 Kubernetes 服务器版本必须不低于版本 v1.9. 要获知版本信息,请输入kubectl version.
关于 CoreDNS
CoreDNS 是一个灵活可扩展的 DNS 服务器,可以作为 Kubernetes 集群 DNS。 与 Kubernetes 一样,CoreDNS 项目由 CNCF 托管。
通过在现有的集群中替换 kube-dns,可以在集群中使用 CoreDNS 代替 kube-dns 部署, 或者使用 kubeadm 等工具来为你部署和升级集群。
安装 CoreDNS
有关手动部署或替换 kube-dns,请参阅 CoreDNS GitHub 工程。
迁移到 CoreDNS
使用 kubeadm 升级现有集群
在 Kubernetes 1.10 及更高版本中,当你使用 kubeadm 升级使用 kube-dns 的集群时,你还可以迁移到 CoreDNS。
在本例中 kubeadm 将生成 CoreDNS 配置("Corefile")基于 kube-dns ConfigMap,
保存存根域和上游名称服务器的配置。
如果你正在从 kube-dns 迁移到 CoreDNS,请确保在升级期间将 CoreDNS 特性门设置为 true。
例如,v1.11.0 升级应该是这样的:
kubeadm upgrade apply v1.11.0 --feature-gates=CoreDNS=true
在 Kubernetes 版本 1.13 和更高版本中,CoreDNS特性门已经删除,CoreDNS 在默认情况下使用。
在 1.11 之前的版本中,核心文件将被升级过程中创建的文件覆盖。 如果已对其进行自定义,则应保存现有的 ConfigMap。 在新的 ConfigMap 启动并运行后,你可以重新应用自定义。
如果你在 Kubernetes 1.11 及更高版本中运行 CoreDNS,则在升级期间,将保留现有的 Corefile。
在 kubernetes 1.21 中,kubeadm 移除了对 kube-dns 的支持。
升级 CoreDNS
从 v1.9 起,Kubernetes 提供了 CoreDNS。 你可以在此处 查看 Kubernetes 随附的 CoreDNS 版本以及对 CoreDNS 所做的更改。
如果你只想升级 CoreDNS 或使用自己的自定义镜像,则可以手动升级 CoreDNS。 参看指南和演练 文档了解如何平滑升级。
CoreDNS 调优
当资源利用方面有问题时,优化 CoreDNS 的配置可能是有用的。 有关详细信息,请参阅有关扩缩 CoreDNS 的文档。
接下来
你可以通过修改 Corefile 来配置 CoreDNS,以支持比 kube-dns 更多的用例。
请参考 CoreDNS 网站
以了解更多信息。
13 - 使用 KMS 驱动进行数据加密
本页展示了如何配置秘钥管理服务—— Key Management Service (KMS) 驱动和插件以启用 Secret 数据加密。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
- 需要 Kubernetes 1.10.0 或更新版本
- 需要 etcd v3 或更新版本
Kubernetes v1.12 [beta]
KMS 加密驱动使用封套加密模型来加密 etcd 中的数据。 数据使用数据加密秘钥(DEK)加密;每次加密都生成一个新的 DEK。 这些 DEK 经一个秘钥加密秘钥(KEK)加密后在一个远端的 KMS 中存储和管理。 KMS 驱动使用 gRPC 与一个特定的 KMS 插件通信。这个 KMS 插件作为一个 gRPC 服务器被部署在 Kubernetes 主服务器的同一个主机上,负责与远端 KMS 的通信。
配置 KMS 驱动
为了在 API 服务器上配置 KMS 驱动,在加密配置文件中的驱动数组中加入一个类型为 kms
的驱动,并设置下列属性:
name: KMS 插件的显示名称。endpoint: gRPC 服务器(KMS 插件)的监听地址。该端点是一个 UNIX 域套接字。cachesize: 以明文缓存的数据加密秘钥(DEKs)的数量。一旦被缓存, 就可以直接使用 DEKs 而无需另外调用 KMS;而未被缓存的 DEKs 需要调用一次 KMS 才能解包。timeout: 在返回一个错误之前,kube-apiserver 等待 kms-plugin 响应的时间(默认是 3 秒)。
实现 KMS 插件
为实现一个 KMS 插件,你可以开发一个新的插件 gRPC 服务器或启用一个由你的云服务驱动提供的 KMS 插件。 你可以将这个插件与远程 KMS 集成,并把它部署到 Kubernetes 的主服务器上。
启用由云服务驱动支持的 KMS
有关启用云服务驱动特定的 KMS 插件的说明,请咨询你的云服务驱动商。
开发 KMS 插件 gRPC 服务器
你可以使用 Go 语言的存根文件开发 KMS 插件 gRPC 服务器。 对于其他语言,你可以用 proto 文件创建可以用于开发 gRPC 服务器代码的存根文件。
- 使用 Go:使用存根文件 service.pb.go 中的函数和数据结构开发 gRPC 服务器代码。
- 使用 Go 以外的其他语言:用 protoc 编译器编译 proto 文件: service.proto 为指定语言生成存根文件。
然后使用存根文件中的函数和数据结构开发服务器代码。
注意:
-
kms 插件版本:
v1beta1作为对过程调用 Version 的响应,兼容的 KMS 插件应把 v1beta1 作为 VersionResponse.version 返回
-
消息版本:
v1beta1所有来自 KMS 驱动的消息都把 version 字段设置为当前版本 v1beta1
-
协议:UNIX 域套接字 (
unix)gRPC 服务器应监听 UNIX 域套接字
将 KMS 插件与远程 KMS 整合
KMS 插件可以用任何受 KMS 支持的协议与远程 KMS 通信。 所有的配置数据,包括 KMS 插件用于与远程 KMS 通信的认证凭据,都由 KMS 插件独立地存储和管理。 KMS 插件可以用额外的元数据对密文进行编码,这些元数据是在把它发往 KMS 进行解密之前可能要用到的。
部署 KMS 插件
确保 KMS 插件与 Kubernetes 主服务器运行在同一主机上。
使用 KMS 驱动加密数据
为了加密数据:
-
使用
kms驱动的相应的属性创建一个新的加密配置文件:kind: EncryptionConfiguration apiVersion: apiserver.config.k8s.io/v1 resources: - resources: - secrets providers: - kms: name: myKmsPlugin endpoint: unix:///tmp/socketfile.sock cachesize: 100 timeout: 3s - identity: {}
- 设置 kube-apiserver 的
--encryption-provider-config参数指向配置文件的位置。 - 重启 API 服务器。
验证数据已经加密
写入 etcd 时数据被加密。重启 kube-apiserver 后,任何新建或更新的 Secret 在存储时应该已被加密。 要验证这点,你可以用 etcdctl 命令行程序获取 Secret 内容。
-
在默认的命名空间里创建一个名为 secret1 的 Secret:
kubectl create secret generic secret1 -n default --from-literal=mykey=mydata
-
用 etcdctl 命令行,从 etcd 读取出 Secret:
ETCDCTL_API=3 etcdctl get /kubernetes.io/secrets/default/secret1 [...] | hexdump -C其中
[...]是用于连接 etcd 服务器的额外参数。
- 验证保存的 Secret 是否是以
k8s:enc:kms:v1:开头的,这表明kms驱动已经对结果数据加密。
-
验证 Secret 在被 API 获取时已被正确解密:
kubectl describe secret secret1 -n default结果应该是
mykey: mydata。
确保所有 Secret 都已被加密
因为 Secret 是在写入时被加密的,所以在更新 Secret 时也会加密该内容。
下列命令读取所有 Secret 并更新它们以便应用服务器端加密。如果因为写入冲突导致错误发生, 请重试此命令。对较大的集群,你可能希望根据命名空间或脚本更新去细分 Secret 内容。
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
从本地加密驱动切换到 KMS 驱动
为了从本地加密驱动切换到 kms 驱动并重新加密所有 Secret 内容:
-
在配置文件中加入
kms驱动作为第一个条目,如下列样例所示kind: EncryptionConfiguration apiVersion: apiserver.config.k8s.io/v1 resources: - resources: - secrets providers: - kms: name : myKmsPlugin endpoint: unix:///tmp/socketfile.sock cachesize: 100 - aescbc: keys: - name: key1 secret: <BASE 64 ENCODED SECRET>
-
重启所有 kube-apiserver 进程。
-
运行下列命令使用
kms驱动强制重新加密所有 Secret。kubectl get secrets --all-namespaces -o json| kubectl replace -f -
禁用静态数据加密
要禁用静态数据加密:
-
将
identity驱动作为配置文件中的第一个条目:kind: EncryptionConfiguration apiVersion: apiserver.config.k8s.io/v1 resources: - resources: - secrets providers: - identity: {} - kms: name : myKmsPlugin endpoint: unix:///tmp/socketfile.sock cachesize: 100
-
重启所有 kube-apiserver 进程。
-
运行下列命令强制重新加密所有 Secret。
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
14 - 使用 Kubernetes API 访问集群
本页展示了如何使用 Kubernetes API 访问集群
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
访问集群 API
使用 kubectl 进行首次访问
首次访问 Kubernetes API 时,请使用 Kubernetes 命令行工具 kubectl 。
要访问集群,你需要知道集群位置并拥有访问它的凭证。 通常,当你完成入门指南时,这会自动设置完成,或者由其他人设置好集群并将凭证和位置提供给你。
使用此命令检查 kubectl 已知的位置和凭证:
kubectl config view
许多样例 提供了使用 kubectl 的介绍。完整文档请见 kubectl 手册。
直接访问 REST API
kubectl 处理对 API 服务器的定位和身份验证。如果你想通过 http 客户端(如 curl 或 wget,或浏览器)直接访问 REST API,你可以通过多种方式对 API 服务器进行定位和身份验证:
- 以代理模式运行 kubectl(推荐)。 推荐使用此方法,因为它用存储的 apiserver 位置并使用自签名证书验证 API 服务器的标识。 使用这种方法无法进行中间人(MITM)攻击。
- 另外,你可以直接为 HTTP 客户端提供位置和身份认证。 这适用于被代理混淆的客户端代码。 为防止中间人攻击,你需要将根证书导入浏览器。
使用 Go 或 Python 客户端库可以在代理模式下访问 kubectl。
使用 kubectl 代理
下列命令使 kubectl 运行在反向代理模式下。它处理 API 服务器的定位和身份认证。
像这样运行它:
kubectl proxy --port=8080 &
参见 kubectl 代理 获取更多细节。
然后你可以通过 curl,wget,或浏览器浏览 API,像这样:
curl http://localhost:8080/api/
输出类似如下:
{
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
不使用 kubectl 代理
通过将身份认证令牌直接传给 API 服务器,可以避免使用 kubectl 代理,像这样:
使用 grep/cut 方式:
# 查看所有的集群,因为你的 .kubeconfig 文件中可能包含多个上下文
kubectl config view -o jsonpath='{"Cluster name\tServer\n"}{range .clusters[*]}{.name}{"\t"}{.cluster.server}{"\n"}{end}'
# 从上述命令输出中选择你要与之交互的集群的名称
export CLUSTER_NAME="some_server_name"
# 指向引用该集群名称的 API 服务器
APISERVER=$(kubectl config view -o jsonpath="{.clusters[?(@.name==\"$CLUSTER_NAME\")].cluster.server}")
# 获得令牌
TOKEN=$(kubectl get secrets -o jsonpath="{.items[?(@.metadata.annotations['kubernetes\.io/service-account\.name']=='default')].data.token}"|base64 -d)
# 使用令牌玩转 API
curl -X GET $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
输出类似如下:
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
使用 jsonpath 方式:
APISERVER=$(kubectl config view --minify -o jsonpath='{.clusters[0].cluster.server}')
TOKEN=$(kubectl get secret $(kubectl get serviceaccount default -o jsonpath='{.secrets[0].name}') -o jsonpath='{.data.token}' | base64 --decode )
curl $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
上面例子使用了 --insecure 标志位。这使它易受到 MITM 攻击。
当 kubectl 访问集群时,它使用存储的根证书和客户端证书访问服务器。
(已安装在 ~/.kube 目录下)。
由于集群认证通常是自签名的,因此可能需要特殊设置才能让你的 http 客户端使用根证书。
在一些集群中,API 服务器不需要身份认证;它运行在本地,或由防火墙保护着。 对此并没有一个标准。 配置对 API 的访问 讲解了作为集群管理员可如何对此进行配置。
编程方式访问 API
Kubernetes 官方支持 Go、Python、Java、 dotnet、Javascript 和 Haskell 语言的客户端库。还有一些其他客户端库由对应作者而非 Kubernetes 团队提供并维护。 参考客户端库了解如何使用其他语言 来访问 API 以及如何执行身份认证。
Go 客户端
- 要获取库,运行下列命令:
go get k8s.io/client-go/kubernetes-<kubernetes 版本号>, 参见 https://github.com/kubernetes/client-go/releases 查看受支持的版本。 - 基于 client-go 客户端编写应用程序。
import "k8s.io/client-go/kubernetes" 是正确做法。
Go 客户端可以使用与 kubectl 命令行工具相同的 kubeconfig 文件 定位和验证 API 服务器。参见这个 例子:
package main
import (
"context"
"fmt"
"k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
// uses the current context in kubeconfig
// path-to-kubeconfig -- for example, /root/.kube/config
config, _ := clientcmd.BuildConfigFromFlags("", "<path-to-kubeconfig>")
// creates the clientset
clientset, _ := kubernetes.NewForConfig(config)
// access the API to list pods
pods, _ := clientset.CoreV1().Pods("").List(context.TODO(), v1.ListOptions{})
fmt.Printf("There are %d pods in the cluster\n", len(pods.Items))
}
如果该应用程序部署为集群中的一个 Pod,请参阅从 Pod 内访问 API。
Python 客户端
要使用 Python 客户端,运行下列命令:
pip install kubernetes。
参见 Python 客户端库主页 了解更多安装选项。
Python 客户端可以使用与 kubectl 命令行工具相同的 kubeconfig 文件 定位和验证 API 服务器。参见这个 例子:
from kubernetes import client, config
config.load_kube_config()
v1=client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print("%s\t%s\t%s" % (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
Java 客户端
要安装 Java 客户端,运行:
# 克隆 Java 库
git clone --recursive https://github.com/kubernetes-client/java
# 安装项目文件、POM 等
cd java
mvn install
参阅https://github.com/kubernetes-client/java/releases 了解当前支持的版本。
Java 客户端可以使用 kubectl 命令行所使用的 kubeconfig 文件 以定位 API 服务器并向其认证身份。 参看此示例:
package io.kubernetes.client.examples;
import io.kubernetes.client.ApiClient;
import io.kubernetes.client.ApiException;
import io.kubernetes.client.Configuration;
import io.kubernetes.client.apis.CoreV1Api;
import io.kubernetes.client.models.V1Pod;
import io.kubernetes.client.models.V1PodList;
import io.kubernetes.client.util.ClientBuilder;
import io.kubernetes.client.util.KubeConfig;
import java.io.FileReader;
import java.io.IOException;
/**
* A simple example of how to use the Java API from an application outside a kubernetes cluster
*
* <p>Easiest way to run this: mvn exec:java
* -Dexec.mainClass="io.kubernetes.client.examples.KubeConfigFileClientExample"
*
*/
public class KubeConfigFileClientExample {
public static void main(String[] args) throws IOException, ApiException {
// file path to your KubeConfig
String kubeConfigPath = "~/.kube/config";
// loading the out-of-cluster config, a kubeconfig from file-system
ApiClient client =
ClientBuilder.kubeconfig(KubeConfig.loadKubeConfig(new FileReader(kubeConfigPath))).build();
// set the global default api-client to the in-cluster one from above
Configuration.setDefaultApiClient(client);
// the CoreV1Api loads default api-client from global configuration.
CoreV1Api api = new CoreV1Api();
// invokes the CoreV1Api client
V1PodList list = api.listPodForAllNamespaces(null, null, null, null, null, null, null, null, null);
System.out.println("Listing all pods: ");
for (V1Pod item : list.getItems()) {
System.out.println(item.getMetadata().getName());
}
}
}
.Net 客户端
要使用.Net 客户端,运行下面的命令:
dotnet add package KubernetesClient --version 1.6.1。
参见.Net 客户端库页面了解更多安装选项。
关于可支持的版本,参见https://github.com/kubernetes-client/csharp/releases。
.Net 客户端可以使用与 kubectl CLI 相同的 kubeconfig 文件 来定位并验证 API 服务器。 参见样例:
using System;
using k8s;
namespace simple
{
internal class PodList
{
private static void Main(string[] args)
{
var config = KubernetesClientConfiguration.BuildDefaultConfig();
IKubernetes client = new Kubernetes(config);
Console.WriteLine("Starting Request!");
var list = client.ListNamespacedPod("default");
foreach (var item in list.Items)
{
Console.WriteLine(item.Metadata.Name);
}
if (list.Items.Count == 0)
{
Console.WriteLine("Empty!");
}
}
}
}
JavaScript 客户端
要安装 JavaScript 客户端,运行下面的命令:
npm install @kubernetes/client-node。
参考https://github.com/kubernetes-client/javascript/releases了解可支持的版本。
JavaScript 客户端可以使用 kubectl 命令行所使用的 kubeconfig 文件 以定位 API 服务器并向其认证身份。 参见此例:
const k8s = require('@kubernetes/client-node');
const kc = new k8s.KubeConfig();
kc.loadFromDefault();
const k8sApi = kc.makeApiClient(k8s.CoreV1Api);
k8sApi.listNamespacedPod('default').then((res) => {
console.log(res.body);
});
Haskell 客户端
参考 https://github.com/kubernetes-client/haskell/releases 了解支持的版本。
Haskell 客户端 可以使用 kubectl 命令行所使用的 kubeconfig 文件 以定位 API 服务器并向其认证身份。 参见此例:
exampleWithKubeConfig :: IO ()
exampleWithKubeConfig = do
oidcCache <- atomically $ newTVar $ Map.fromList []
(mgr, kcfg) <- mkKubeClientConfig oidcCache $ KubeConfigFile "/path/to/kubeconfig"
dispatchMime
mgr
kcfg
(CoreV1.listPodForAllNamespaces (Accept MimeJSON))
>>= print
接下来
15 - 保护集群安全
本文档涉及与保护集群免受意外或恶意访问有关的主题,并对总体安全性提出建议。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
控制对 Kubernetes API 的访问
因为 Kubernetes 是完全通过 API 驱动的,所以,控制和限制谁可以通过 API 访问集群,以及允许这些访问者执行什么样的 API 动作,就成为了安全控制的第一道防线。
为所有 API 交互使用传输层安全 (TLS)
Kubernetes 期望集群中所有的 API 通信在默认情况下都使用 TLS 加密,大多数安装方法也允许创建所需的证书并且分发到集群组件中。请注意,某些组件和安装方法可能使用 HTTP 来访问本地端口, 管理员应该熟悉每个组件的设置,以识别潜在的不安全的流量。
API 认证
安装集群时,选择一个 API 服务器的身份验证机制,去使用与之匹配的公共访问模式。 例如,小型的单用户集群可能希望使用简单的证书或静态承载令牌方法。 更大的集群则可能希望整合现有的、OIDC、LDAP 等允许用户分组的服务器。
所有 API 客户端都必须经过身份验证,即使它是基础设施的一部分,比如节点、代理、调度程序和卷插件。 这些客户端通常使用 服务帐户 或 X509 客户端证书,并在集群启动时自动创建或是作为集群安装的一部分进行设置。
如果你希望获取更多信息,请参考认证参考文档。
API 授权
一旦通过身份认证,每个 API 的调用都将通过鉴权检查。 Kubernetes 集成基于角色的访问控制(RBAC)组件, 将传入的用户或组与一组绑定到角色的权限匹配。 这些权限将动作(get,create,delete)和资源(pod,service, node)在命名空间或者集群范围内结合起来, 根据客户可能希望执行的操作,提供了一组提供合理的违约责任分离的外包角色。 建议你将节点 和 RBAC 一起作为授权者,再与 NodeRestriction 准入插件结合使用。
与身份验证一样,简单而广泛的角色可能适合于较小的集群,但是随着更多的用户与集群交互, 可能需要将团队划分成有更多角色限制的单独的命名空间。
就鉴权而言,理解怎么样更新一个对象可能导致在其它地方的发生什么样的行为是非常重要的。 例如,用户可能不能直接创建 Pod,但允许他们通过创建一个 Deployment 来创建这些 Pod, 这将让他们间接创建这些 Pod。 同样地,从 API 删除一个节点将导致调度到这些节点上的 Pod 被中止,并在其他节点上重新创建。 原生的角色设计代表了灵活性和常见用例之间的平衡,但有限制的角色应该仔细审查, 以防止意外升级。如果外包角色不满足你的需求,则可以为用例指定特定的角色。
如果你希望获取更多信息,请参阅鉴权参考。
控制对 Kubelet 的访问
Kubelet 公开 HTTPS 端点,这些端点授予节点和容器强大的控制权。 默认情况下,Kubelet 允许对此 API 进行未经身份验证的访问。
生产级别的集群应启用 Kubelet 身份验证和授权。
如果你希望获取更多信息,请参考 Kubelet 身份验证/授权参考。
控制运行时负载或用户的能力
Kubernetes 中的授权故意设置为了高层级,它侧重于对资源的粗粒度行为。 更强大的控制是以通过用例限制这些对象如何作用于集群、自身和其他资源上的策略存在的。
限制集群上的资源使用
资源配额 限制了授予命名空间的资源的数量或容量。 这通常用于限制命名空间可以分配的 CPU、内存或持久磁盘的数量,但也可以控制 每个命名空间中有多少个 Pod、服务或卷的存在。
限制范围限制 上述某些资源的最大值或者最小值,以防止用户使用类似内存这样的通用保留资源时请求 不合理的过高或过低的值,或者在没有指定的情况下提供默认限制。
控制容器运行的特权
Pod 定义包含了一个安全上下文,
用于描述允许它请求访问某个节点上的特定 Linux 用户(如 root)、获得特权或访问主机网络、
以及允许它在主机节点上不受约束地运行的其它控件。
Pod 安全策略
可以限制哪些用户或服务帐户可以提供危险的安全上下文设置。
例如,Pod 的安全策略可以限制卷挂载,尤其是 hostpath,这些都是 Pod 应该控制的一些方面。
一般来说,大多数应用程序需要限制对主机资源的访问, 他们可以在不能访问主机信息的情况下成功以根进程(UID 0)运行。 但是,考虑到与 root 用户相关的特权,在编写应用程序容器时,你应该使用非 root 用户运行。 类似地,希望阻止客户端应用程序逃避其容器的管理员,应该使用限制性的 pod 安全策略。
限制网络访问
基于命名空间的网络策略 允许应用程序作者限制其它命名空间中的哪些 Pod 可以访问它们命名空间内的 Pod 和端口。 现在已经有许多支持网络策略的 Kubernetes 网络供应商。
对于可以控制用户的应用程序是否在集群之外可见的许多集群,配额和限制范围也可用于 控制用户是否可以请求节点端口或负载均衡服务。
在插件或者环境基础上控制网络规则可以增加额外的保护措施,比如节点防火墙、物理分离 群集节点以防止串扰、或者高级的网络策略。
限制云 metadata API 访问
云平台(AWS, Azure, GCE 等)经常讲 metadate 本地服务暴露给实例。 默认情况下,这些 API 可由运行在实例上的 Pod 访问,并且可以包含 该云节点的凭据或配置数据(如 kubelet 凭据)。 这些凭据可以用于在集群内升级或在同一账户下升级到其他云服务。
在云平台上运行 Kubernetes 时,限制对实例凭据的权限,使用 网络策略 限制对 metadata API 的 pod 访问,并避免使用配置数据来传递机密。
控制 Pod 可以访问哪些节点
默认情况下,对哪些节点可以运行 pod 没有任何限制。 Kubernetes 给最终用户提供了 一组丰富的策略用于控制 pod 放在节点上的位置, 以及基于污点的 Pod 放置和驱逐。 对于许多集群,可以约定由作者采用或者强制通过工具使用这些策略来分离工作负载。
对于管理员,Beta 阶段的准入插件 PodNodeSelector 可用于强制命名空间中的 Pod
使用默认或需要使用特定的节点选择器。
如果最终用户无法改变命名空间,这可以强烈地限制所有的 pod 在特定工作负载的位置。
保护集群组件免受破坏
本节描述保护集群免受破坏的一些常见模式。
限制访问 etcd
对于 API 来说,拥有 etcd 后端的写访问权限,相当于获得了整个集群的 root 权限, 并且可以使用写访问权限来相当快速地升级。 从 API 服务器访问它们的 etcd 服务器,管理员应该使用广受信任的凭证, 如通过 TLS 客户端证书的相互认证。 通常,我们建议将 etcd 服务器隔离到只有API服务器可以访问的防火墙后面。
开启审计日志
审计日志是 Beta 特性, 负责记录 API 操作以便在发生破坏时进行事后分析。 建议启用审计日志,并将审计文件归档到安全服务器上。
限制使用 alpha 和 beta 特性
Kubernetes 的 alpha 和 beta 特性还在努力开发中,可能存在导致安全漏洞的缺陷或错误。 要始终评估 alpha 和 beta 特性可能为你的安全态势带来的风险。 当你怀疑存在风险时,可以禁用那些不需要使用的特性。
频繁回收基础设施证书
一个 Secret 或凭据的寿命越短,攻击者就越难使用该凭据。 在证书上设置短生命周期并实现自动回收,是控制安全的一个好方法。 因此,使用身份验证提供程序时,应该要求可以控制发布令牌的可用时间,并尽可能使用短寿命。 如果在外部集成中使用服务帐户令牌,则应该频繁地回收这些令牌。 例如,一旦引导阶段完成,就应该撤销用于设置节点的引导令牌,或者取消它的授权。
在启用第三方集成之前,请先审查它们
许多集成到 Kubernetes 的第三方都可以改变你集群的安全配置。 启用集成时,在授予访问权限之前,你应该始终检查扩展所请求的权限。 例如,许多安全集成可以请求访问来查看集群上的所有 Secret, 从而有效地使该组件成为集群管理。 当有疑问时,如果可能的话,将集成限制在单个命名空间中运行。
如果组件创建的 Pod 能够在命名空间中做一些类似 kube-system 命名空间中的事情,
那么它也可能是出乎意料的强大。
因为这些 Pod 可以访问服务账户的 Secret,或者,如果这些服务帐户被授予访问许可的
Pod 安全策略的权限,它们能以高权限运行。
对 Secret 进行静态加密
一般情况下,etcd 数据库包含了通过 Kubernetes API 可以访问到的所有信息, 并且可以授予攻击者对集群状态的可见性。 始终使用经过良好审查的备份和加密解决方案来加密备份,并考虑在可能的情况下使用全磁盘加密。
Kubernetes 支持 静态数据加密,
该功能在 1.7 版本引入,并在 1.13 版本成为 Beta。它会加密 etcd 里面的 Secret 资源,以防止某一方通过查看
etcd 的备份文件查看到这些 Secret 的内容。虽然目前这还只是 Beta 阶段的功能,
但是在备份没有加密或者攻击者获取到 etcd 的读访问权限的时候,它能提供额外的防御层级。
接收安全更新和报告漏洞的警报
加入 kubernetes-announce 组,能够获取有关安全公告的邮件。有关如何报告漏洞的更多信息,请参见 安全报告页面。
16 - 关键插件 Pod 的调度保证
Kubernetes 核心组件(如 API 服务器、调度器、控制器管理器)在控制平面节点上运行。 但是插件必须在常规集群节点上运行。 其中一些插件对于功能完备的群集至关重要,例如 Heapster、DNS 和 UI。 如果关键插件被逐出(手动或作为升级等其他操作的副作用)或者变成挂起状态,群集可能会停止正常工作。 关键插件进入挂起状态的例子有:集群利用率过高;被逐出的关键插件 Pod 释放了空间,但该空间被之前悬决的 Pod 占用;由于其它原因导致节点上可用资源的总量发生变化。
注意,把某个 Pod 标记为关键 Pod 并不意味着完全避免该 Pod 被逐出;它只能防止该 Pod 变成永久不可用。 被标记为关键性的静态 Pod 不会被逐出。但是,被标记为关键性的非静态 Pod 总是会被重新调度。
标记关键 Pod
要将 Pod 标记为关键性(critical),设置 Pod 的 priorityClassName 为 system-cluster-critical 或者 system-node-critical。
system-node-critical 是最高级别的可用性优先级,甚至比 system-cluster-critical 更高。
17 - 升级集群
本页概述升级 Kubernetes 集群的步骤。
升级集群的方式取决于你最初部署它的方式、以及后续更改它的方式。
从高层规划的角度看,要执行的步骤是:
准备开始
你必须有一个集群。 本页内容涉及从 Kubernetes 1.22 升级到 Kubernetes 1.23。 如果你的集群未运行 Kubernetes 1.22, 那请参考目标 Kubernetes 版本的文档。
升级方法
kubeadm
如果你的集群是使用 kubeadm 安装工具部署而来,
那么升级群集的详细信息,请参阅
升级 kubeadm 集群。
升级集群之后,要记得
安装最新版本的 kubectl.
手动部署
你应该跟随下面操作顺序,手动更新控制平面:
- etcd (所有实例)
- kube-apiserver (所有控制平面的宿主机)
- kube-controller-manager
- kube-scheduler
- cloud controller manager, 在你用到时
现在,你应该
安装最新版本的 kubectl.
对于群集中的每个节点, 排空 节点,然后,或者用一个运行了 1.23 kubelet 的新节点替换它; 或者升级此节点的 kubelet,并使节点恢复服务。
其他部署方式
参阅你的集群部署工具对应的文档,了解用于维护的推荐设置步骤。
升级后的任务
切换群集的存储 API 版本
对象序列化到 etcd,是为了提供集群中活动 Kubernetes 资源的内部表示法, 这些对象都使用特定版本的 API 编写。
当底层的 API 更改时,这些对象可能需要用新 API 重写。 如果不能做到这一点,会导致再也不能用 Kubernetes API 服务器解码、使用该对象。
对于每个受影响的对象,用最新支持的 API 获取它,然后再用最新支持的 API 写回来。
更新清单
升级到新版本 Kubernetes 就可以提供新的 API。
你可以使用 kubectl convert 命令在不同 API 版本之间转换清单。
例如:
kubectl convert -f pod.yaml --output-version v1
kubectl 替换了 pod.yaml 的内容,
在新的清单文件中,kind 被设置为 Pod(未变),
但 apiVersion 则被修订了。
18 - 名字空间演练
Kubernetes 名字空间 有助于不同的项目、团队或客户去共享 Kubernetes 集群。
名字空间通过以下方式实现这点:
- 为名字设置作用域.
- 为集群中的部分资源关联鉴权和策略的机制。
使用多个名字空间是可选的。
此示例演示了如何使用 Kubernetes 名字空间细分群集。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
环境准备
此示例作如下假设:
- 你已拥有一个配置好的 Kubernetes 集群。
- 你已对 Kubernetes 的 Pods、 Services 和 Deployments 有基本理解。
- 理解默认名字空间
默认情况下,Kubernetes 集群会在配置集群时实例化一个默认名字空间,用以存放集群所使用的默认 Pod、Service 和 Deployment 集合。
假设你有一个新的集群,你可以通过执行以下操作来检查可用的名字空间:
kubectl get namespaces
NAME STATUS AGE
default Active 13m
创建新的名字空间
在本练习中,我们将创建两个额外的 Kubernetes 名字空间来保存我们的内容。
我们假设一个场景,某组织正在使用共享的 Kubernetes 集群来支持开发和生产:
开发团队希望在集群中维护一个空间,以便他们可以查看用于构建和运行其应用程序的 Pod、Service 和 Deployment 列表。在这个空间里,Kubernetes 资源被自由地加入或移除, 对谁能够或不能修改资源的限制被放宽,以实现敏捷开发。
运维团队希望在集群中维护一个空间,以便他们可以强制实施一些严格的规程, 对谁可以或谁不可以操作运行生产站点的 Pod、Service 和 Deployment 集合进行控制。
该组织可以遵循的一种模式是将 Kubernetes 集群划分为两个名字空间:development 和 production。
让我们创建两个新的名字空间来保存我们的工作。
文件 namespace-dev.json 描述了 development 名字空间:
{
"apiVersion": "v1",
"kind": "Namespace",
"metadata": {
"name": "development",
"labels": {
"name": "development"
}
}
}
使用 kubectl 创建 development 名字空间。
kubectl create -f https://k8s.io/examples/admin/namespace-dev.json
将下列的内容保存到文件 namespace-prod.json 中,
这些内容是对 production 名字空间的描述:
{
"apiVersion": "v1",
"kind": "Namespace",
"metadata": {
"name": "production",
"labels": {
"name": "production"
}
}
}
让我们使用 kubectl 创建 production 名字空间。
kubectl create -f https://k8s.io/examples/admin/namespace-prod.json
为了确保一切正常,我们列出集群中的所有名字空间。
kubectl get namespaces --show-labels
NAME STATUS AGE LABELS
default Active 32m <none>
development Active 29s name=development
production Active 23s name=production
在每个名字空间中创建 pod
Kubernetes 名字空间为集群中的 Pod、Service 和 Deployment 提供了作用域。
与一个名字空间交互的用户不会看到另一个名字空间中的内容。
为了演示这一点,让我们在 development 名字空间中启动一个简单的 Deployment 和 Pod。
我们首先检查一下当前的上下文:
kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: REDACTED
server: https://130.211.122.180
name: lithe-cocoa-92103_kubernetes
contexts:
- context:
cluster: lithe-cocoa-92103_kubernetes
user: lithe-cocoa-92103_kubernetes
name: lithe-cocoa-92103_kubernetes
current-context: lithe-cocoa-92103_kubernetes
kind: Config
preferences: {}
users:
- name: lithe-cocoa-92103_kubernetes
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
token: 65rZW78y8HbwXXtSXuUw9DbP4FLjHi4b
- name: lithe-cocoa-92103_kubernetes-basic-auth
user:
password: h5M0FtUUIflBSdI7
username: admin
kubectl config current-context
lithe-cocoa-92103_kubernetes
下一步是为 kubectl 客户端定义一个上下文,以便在每个名字空间中工作。 "cluster" 和 "user" 字段的值将从当前上下文中复制。
kubectl config set-context dev --namespace=development \
--cluster=lithe-cocoa-92103_kubernetes \
--user=lithe-cocoa-92103_kubernetes
kubectl config set-context prod --namespace=production \
--cluster=lithe-cocoa-92103_kubernetes \
--user=lithe-cocoa-92103_kubernetes
默认情况下,上述命令会添加两个上下文到 .kube/config 文件中。
你现在可以查看上下文并根据你希望使用的名字空间并在这两个新的请求上下文之间切换。
查看新的上下文:
kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: REDACTED
server: https://130.211.122.180
name: lithe-cocoa-92103_kubernetes
contexts:
- context:
cluster: lithe-cocoa-92103_kubernetes
user: lithe-cocoa-92103_kubernetes
name: lithe-cocoa-92103_kubernetes
- context:
cluster: lithe-cocoa-92103_kubernetes
namespace: development
user: lithe-cocoa-92103_kubernetes
name: dev
- context:
cluster: lithe-cocoa-92103_kubernetes
namespace: production
user: lithe-cocoa-92103_kubernetes
name: prod
current-context: lithe-cocoa-92103_kubernetes
kind: Config
preferences: {}
users:
- name: lithe-cocoa-92103_kubernetes
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
token: 65rZW78y8HbwXXtSXuUw9DbP4FLjHi4b
- name: lithe-cocoa-92103_kubernetes-basic-auth
user:
password: h5M0FtUUIflBSdI7
username: admin
让我们切换到 development 名字空间进行操作。
kubectl config use-context dev
你可以使用下列命令验证当前上下文:
kubectl config current-context
dev
此时,我们从命令行向 Kubernetes 集群发出的所有请求都限定在 development 名字空间中。
让我们创建一些内容。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: snowflake
name: snowflake
spec:
replicas: 2
selector:
matchLabels:
app: snowflake
template:
metadata:
labels:
app: snowflake
spec:
containers:
- image: k8s.gcr.io/serve_hostname
imagePullPolicy: Always
name: snowflake
应用清单文件来创建 Deployment。
我们创建了一个副本大小为 2 的 Deployment,该 Deployment 运行名为 snowflake 的 Pod,
其中包含一个仅提供主机名服务的基本容器。
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
snowflake 2/2 2 2 2m
kubectl get pods -l app=snowflake
NAME READY STATUS RESTARTS AGE
snowflake-3968820950-9dgr8 1/1 Running 0 2m
snowflake-3968820950-vgc4n 1/1 Running 0 2m
这很棒,开发人员可以做他们想要的事情,而不必担心影响 production 名字空间中的内容。
让我们切换到 production 名字空间,展示一个名字空间中的资源如何对另一个名字空间不可见。
kubectl config use-context prod
production 名字空间应该是空的,下列命令应该返回的内容为空。
kubectl get deployment
kubectl get pods
生产环境需要以放牛的方式运维,让我们创建一些名为 cattle 的 Pod。
kubectl create deployment cattle --image=k8s.gcr.io/serve_hostname --replicas=5
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
cattle 5/5 5 5 10s
kubectl get pods -l run=cattle
NAME READY STATUS RESTARTS AGE
cattle-2263376956-41xy6 1/1 Running 0 34s
cattle-2263376956-kw466 1/1 Running 0 34s
cattle-2263376956-n4v97 1/1 Running 0 34s
cattle-2263376956-p5p3i 1/1 Running 0 34s
cattle-2263376956-sxpth 1/1 Running 0 34s
此时,应该很清楚的展示了用户在一个名字空间中创建的资源对另一个名字空间是不可见的。
随着 Kubernetes 中的策略支持的发展,我们将扩展此场景,以展示如何为每个名字空间提供不同的授权规则。
19 - 启用/禁用 Kubernetes API
本页展示怎么用集群的 控制平面. 启用/禁用 API 版本。
通过 API 服务器的命令行参数 --runtime-config=api/<version> ,
可以开启/关闭某个指定的 API 版本。
此参数的值是一个逗号分隔的 API 版本列表。
此列表中,后面的值可以覆盖前面的值。
命令行参数 runtime-config 支持两个特殊的值(keys):
api/all:指所有已知的 APIapi/legacy:指过时的 API。过时的 API 就是明确地 弃用 的 API。
例如:为了停用除去 v1 版本之外的全部其他 API 版本,
就用参数 --runtime-config=api/all=false,api/v1=true 启动 kube-apiserver。
接下来
阅读完整的文档,
以了解 kube-apiserver 组件。
20 - 启用拓扑感知提示
Kubernetes v1.21 [alpha]
拓扑感知提示 启用具有拓扑感知能力的路由,其中拓扑感知信息包含在 EndpointSlices 中。 此功能尽量将流量限制在它的发起区域附近; 可以降低成本,或者提高网络性能。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
您的 Kubernetes 服务器版本必须不低于版本 1.21. 要获知版本信息,请输入kubectl version.
为了启用拓扑感知提示,先要满足以下先决条件:
- 配置 kube-proxy 以 iptables 或 IPVS 模式运行
- 确保未禁用 EndpointSlices
启动拓扑感知提示
要启用服务拓扑感知,请启用 kube-apiserver、kube-controller-manager、和 kube-proxy 的
特性门控
TopologyAwareHints。
--feature-gates="TopologyAwareHints=true"
接下来
21 - 在 Kubernetes 集群中使用 NodeLocal DNSCache
Kubernetes v1.18 [stable]
本页概述了 Kubernetes 中的 NodeLocal DNSCache 功能。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
引言
NodeLocal DNSCache 通过在集群节点上作为 DaemonSet 运行 dns 缓存代理来提高集群 DNS 性能。 在当今的体系结构中,处于 ClusterFirst DNS 模式的 Pod 可以连接到 kube-dns serviceIP 进行 DNS 查询。 通过 kube-proxy 添加的 iptables 规则将其转换为 kube-dns/CoreDNS 端点。 借助这种新架构,Pods 将可以访问在同一节点上运行的 dns 缓存代理,从而避免了 iptables DNAT 规则和连接跟踪。 本地缓存代理将查询 kube-dns 服务以获取集群主机名的缓存缺失(默认为 cluster.local 后缀)。
动机
- 使用当前的 DNS 体系结构,如果没有本地 kube-dns/CoreDNS 实例,则具有最高 DNS QPS 的 Pod 可能必须延伸到另一个节点。 在这种脚本下,拥有本地缓存将有助于改善延迟。
- 跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表。
- 从本地缓存代理到 kube-dns 服务的连接可以升级到 TCP 。
TCP conntrack 条目将在连接关闭时被删除,相反 UDP 条目必须超时(默认
nf_conntrack_udp_timeout是 30 秒)
- 将 DNS 查询从 UDP 升级到 TCP 将减少归因于丢弃的 UDP 数据包和 DNS 超时的尾部等待时间,通常长达 30 秒(3 次重试+ 10 秒超时)。
- 在节点级别对 dns 请求的度量和可见性。
- 可以重新启用负缓存,从而减少对 kube-dns 服务的查询数量。
架构图
启用 NodeLocal DNSCache 之后,这是 DNS 查询所遵循的路径:

Nodelocal DNSCache 流
此图显示了 NodeLocal DNSCache 如何处理 DNS 查询。
配置
可以使用以下步骤启动此功能:
- 根据示例
nodelocaldns.yaml准备一个清单,把它保存为nodelocaldns.yaml。
- 如果使用 IPv6,在使用 IP:Port 格式的时候需要把 CoreDNS 配置文件里的所有 IPv6 地址用方括号包起来。
如果你使用上述的示例清单,需要把 配置行 L70
修改为
health [__PILLAR__LOCAL__DNS__]:8080。
-
把清单里的变量更改为正确的值:
-
kubedns=
kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP} -
domain=
<cluster-domain> -
localdns=
<node-local-address>
<cluster-domain>的默认值是 "cluster.local"。<node-local-address>是 NodeLocal DNSCache 选择的本地侦听 IP 地址。 -
-
如果 kube-proxy 运行在 IPTABLES 模式:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__/$kubedns/g" nodelocaldns.yamlnode-local-dns Pods 会设置
__PILLAR__CLUSTER__DNS__和__PILLAR__UPSTREAM__SERVERS__。 在此模式下, node-local-dns Pods 会同时侦听 kube-dns 服务的 IP 地址和<node-local-address>的地址, 以便 Pods 可以使用其中任何一个 IP 地址来查询 DNS 记录。
-
如果 kube-proxy 运行在 IPVS 模式:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__//g; s/__PILLAR__CLUSTER__DNS__/$kubedns/g" nodelocaldns.yaml在此模式下,node-local-dns Pods 只会侦听
<node-local-address>的地址。 node-local-dns 接口不能绑定 kube-dns 的集群 IP 地址,因为 IPVS 负载均衡 使用的接口已经占用了该地址。 node-local-dns Pods 会设置__PILLAR__UPSTREAM__SERVERS__。
- 运行
kubectl create -f nodelocaldns.yaml - 如果 kube-proxy 运行在 IPVS 模式,需要修改 kubelet 的
--cluster-dns参数为 NodeLocal DNSCache 正在侦听的<node-local-address>地址。 否则,不需要修改--cluster-dns参数,因为 NodeLocal DNSCache 会同时侦听 kube-dns 服务的 IP 地址和<node-local-address>的地址。
启用后,node-local-dns Pods 将在每个集群节点上的 kube-system 名字空间中运行。 此 Pod 在缓存模式下运行 CoreDNS ,因此每个节点都可以使用不同插件公开的所有 CoreDNS 指标。
如果要禁用该功能,你可以使用 kubectl delete -f <manifest> 来删除 DaemonSet。你还应该恢复你对 kubelet 配置所做的所有改动。
22 - 在 Kubernetes 集群中使用 sysctl
Kubernetes v1.21 [stable]
本文档介绍如何通过 sysctl 接口在 Kubernetes 集群中配置和使用内核参数。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
对一些步骤,你需要能够重新配置在你的集群里运行的 kubelet 命令行的选项。
获取 Sysctl 的参数列表
在 Linux 中,管理员可以通过 sysctl 接口修改内核运行时的参数。在 /proc/sys/
虚拟文件系统下存放许多内核参数。这些参数涉及了多个内核子系统,如:
- 内核子系统(通常前缀为:
kernel.) - 网络子系统(通常前缀为:
net.) - 虚拟内存子系统(通常前缀为:
vm.) - MDADM 子系统(通常前缀为:
dev.) - 更多子系统请参见内核文档。
若要获取完整的参数列表,请执行以下命令
sudo sysctl -a
启用非安全的 Sysctl 参数
sysctl 参数分为 安全 和 非安全的。 安全 sysctl 参数除了需要设置恰当的命名空间外,在同一 node 上的不同 Pod 之间也必须是 相互隔离的。这意味着在 Pod 上设置 安全 sysctl 参数
- 必须不能影响到节点上的其他 Pod
- 必须不能损害节点的健康
- 必须不允许使用超出 Pod 的资源限制的 CPU 或内存资源。
至今为止,大多数 有命名空间的 sysctl 参数不一定被认为是 安全 的。 以下几种 sysctl 参数是 安全的:
kernel.shm_rmid_forcednet.ipv4.ip_local_port_rangenet.ipv4.tcp_syncookiesnet.ipv4.ping_group_range(从 Kubernetes 1.18 开始)
net.ipv4.tcp_syncookies 在Linux 内核 4.4 或更低的版本中是无命名空间的。
在未来的 Kubernetes 版本中,若 kubelet 支持更好的隔离机制,则上述列表中将会 列出更多 安全的 sysctl 参数。
所有 安全的 sysctl 参数都默认启用。
所有 非安全的 sysctl 参数都默认禁用,且必须由集群管理员在每个节点上手动开启。 那些设置了不安全 sysctl 参数的 Pod 仍会被调度,但无法正常启动。
参考上述警告,集群管理员只有在一些非常特殊的情况下(如:高可用或实时应用调整), 才可以启用特定的 非安全的 sysctl 参数。 如需启用 非安全的 sysctl 参数,请你在每个节点上分别设置 kubelet 命令行参数,例如:
kubelet --allowed-unsafe-sysctls \
'kernel.msg*,net.core.somaxconn' ...
如果你使用 Minikube,可以通过 extra-config 参数来配置:
minikube start --extra-config="kubelet.allowed-unsafe-sysctls=kernel.msg*,net.core.somaxconn"...
只有 有命名空间的 sysctl 参数可以通过该方式启用。
设置 Pod 的 Sysctl 参数
目前,在 Linux 内核中,有许多的 sysctl 参数都是 有命名空间的 。 这就意味着可以为节点上的每个 Pod 分别去设置它们的 sysctl 参数。 在 Kubernetes 中,只有那些有命名空间的 sysctl 参数可以通过 Pod 的 securityContext 对其进行配置。
以下列出有命名空间的 sysctl 参数,在未来的 Linux 内核版本中,此列表可能会发生变化。
kernel.shm*,kernel.msg*,kernel.sem,fs.mqueue.*,net.*(内核中可以在容器命名空间里被更改的网络配置项相关参数)。然而也有一些特例 (例如,net.netfilter.nf_conntrack_max和net.netfilter.nf_conntrack_expect_max可以在容器命名空间里被更改,但它们是非命名空间的)。
没有命名空间的 sysctl 参数称为 节点级别的 sysctl 参数。 如果需要对其进行设置,则必须在每个节点的操作系统上手动地去配置它们, 或者通过在 DaemonSet 中运行特权模式容器来配置。
可使用 Pod 的 securityContext 来配置有命名空间的 sysctl 参数, securityContext 应用于同一个 Pod 中的所有容器。
此示例中,使用 Pod SecurityContext 来对一个安全的 sysctl 参数
kernel.shm_rmid_forced 以及两个非安全的 sysctl 参数
net.core.somaxconn 和 kernel.msgmax 进行设置。
在 Pod 规约中对 安全的 和 非安全的 sysctl 参数不做区分。
apiVersion: v1
kind: Pod
metadata:
name: sysctl-example
spec:
securityContext:
sysctls:
- name: kernel.shm_rmid_forced
value: "0"
- name: net.core.somaxconn
value: "1024"
- name: kernel.msgmax
value: "65536"
...
最佳实践方案是将集群中具有特殊 sysctl 设置的节点视为 有污点的,并且只调度 需要使用到特殊 sysctl 设置的 Pod 到这些节点上。 建议使用 Kubernetes 的 污点和容忍度特性 来实现它。
设置了 非安全的 sysctl 参数的 Pod 在禁用了这两种 非安全的 sysctl 参数配置 的节点上启动都会失败。与 节点级别的 sysctl 一样,建议开启 污点和容忍度特性 或 为节点配置污点 以便将 Pod 调度到正确的节点之上。
PodSecurityPolicy
Kubernetes v1.21 [deprecated]
你可以通过在 PodSecurityPolicy 的 forbiddenSysctls 和/或 allowedUnsafeSysctls
字段中,指定 sysctl 或填写 sysctl 匹配模式来进一步为 Pod 设置 sysctl 参数。
sysctl 参数匹配模式以 * 字符结尾,如 kernel.*。
单独的 * 字符匹配所有 sysctl 参数。
所有 安全的 sysctl 参数都默认启用。
forbiddenSysctls 和 allowedUnsafeSysctls 的值都是字符串列表类型,
可以添加 sysctl 参数名称,也可以添加 sysctl 参数匹配模式(以*结尾)。
只填写 * 则匹配所有的 sysctl 参数。
forbiddenSysctls 字段用于禁用特定的 sysctl 参数。
你可以在列表中禁用安全和非安全的 sysctl 参数的组合。
要禁用所有的 sysctl 参数,请设置为 *。
如果要在 allowedUnsafeSysctls 字段中指定一个非安全的 sysctl 参数,
并且它在 forbiddenSysctls 字段中未被禁用,则可以在 Pod 中通过
PodSecurityPolicy 启用该 sysctl 参数。
若要在 PodSecurityPolicy 中开启所有非安全的 sysctl 参数,
请设 allowedUnsafeSysctls 字段值为 *。
allowedUnsafeSysctls 与 forbiddenSysctls 两字段的配置不能重叠,
否则这就意味着存在某个 sysctl 参数既被启用又被禁用。
allowedUnsafeSysctls 字段将非安全的 sysctl
参数列入白名单,但该 sysctl 参数未通过 kubelet 命令行参数
--allowed-unsafe-sysctls 在节点上将其列入白名单,则设置了这个 sysctl
参数的 Pod 将会启动失败。
以下示例设置启用了以 kernel.msg 为前缀的非安全的 sysctl 参数,同时禁用了
sysctl 参数 kernel.shm_rmid_forced。
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: sysctl-psp
spec:
allowedUnsafeSysctls:
- kernel.msg*
forbiddenSysctls:
- kernel.shm_rmid_forced
...
23 - 在运行中的集群上重新配置节点的 kubelet
Kubernetes v1.22 [deprecated]
动态 kubelet 配置 允许你通过部署一个所有节点都会使用的 ConfigMap 达到在运行中的 Kubernetes 集群中更改 kubelet 配置的目的。
KubeletConfiguration中找到。
准备开始
你需要一个 Kubernetes 集群。
你需要 v1.11 或更高版本的 kubectl,并配置好与集群的通信。
要获知版本信息,请输入 kubectl version.
你的集群 API 服务器版本(如 v1.12)不能和你的 kubectl
版本相差超过一个小版本号。
例如,如果你的集群在运行 v1.16,那么你可以使用 v1.15、v1.16、v1.17 的 kubectl,
所有其他的组合都是
不支持的。
在某些例子中使用了命令行工具 jq。
你并不一定需要 jq 才能完成这些任务,因为总是有一些手工替代的方式。
针对你重新配置的每个节点,你必须设置 kubelet 的标志
-dynamic-config-dir,使之指向一个可写的目录。
重配置 集群中运行节点上的 kubelet
基本工作流程概览
在运行中的集群中配置 kubelet 的基本工作流程如下:
- 编写一个包含 kubelet 配置的 YAML 或 JSON 文件。
- 将此文件包装在 ConfigMap 中并将其保存到 Kubernetes 控制平面。
- 更新 kubelet 所在节点对象以使用此 ConfigMap。
每个 kubelet 都会在其各自的节点对象上监测(Watch)配置引用。当引用更改时,kubelet 将下载新的配置文件, 更新本地引用指向该文件,然后退出。 为了使该功能正常地工作,你必须运行操作系统级别的服务管理器(如 systemd), 它将会在 kubelet 退出后将其重启。 kubelet 重新启动时,将开始使用新配置。
新配置将会完全地覆盖 --config 所提供的配置,并被命令行标志覆盖。
新配置中未指定的值将收到适合配置版本的默认值
(e.g. kubelet.config.k8s.io/v1beta1),除非被命令行标志覆盖。
节点 kubelet 配置状态可通过 node.spec.status.config 获取。
一旦你更新了一个节点去使用新的 ConfigMap,
就可以通过观察此状态来确认该节点是否正在使用预期配置。
本文中使用命令 kubectl edit 来编辑节点,还有其他的方式可以修改节点的规约,
比如更利于脚本化工作流程的 kubectl patch。
本文仅仅讲述在单节点上使用每个 ConfigMap。请注意对于多个节点使用相同的 ConfigMap 也是合法的。
kubectl 的 --append-hash 选项逐步把更新推广到 node.spec.configSource。
节点鉴权器的自动 RBAC 规则
以前,你需要手动创建 RBAC 规则以允许节点访问其分配的 ConfigMap。节点鉴权器现在 能够自动配置这些规则。
生成包含当前配置的文件
动态 kubelet 配置特性允许你为整个配置对象提供一个重载配置,而不是靠单个字段的叠加。 这是一个更简单的模型,可以更轻松地跟踪配置值的来源,更便于调试问题。 然而,相应的代价是你必须首先了解现有配置,以确保你只更改你打算修改的字段。
组件 kubelet 从其配置文件中加载配置数据,不过你可以通过设置命令行标志 来重载文件中的一些配置。这意味着,如果你仅知道配置文件的内容,而你不知道 命令行重载了哪些配置,你就无法知道 kubelet 的运行时配置是什么。
因为你需要知道运行时所使用的配置才能重载之,你可以从 kubelet 取回其运行时配置。
你可以通过访问 kubelet 的 configz 末端来生成包含节点当前配置的配置文件;
这一操作可以通过 kubectl proxy 来完成。
下一节解释如何完成这一操作。
kubelet 上的 configz 末端是用来协助调试的,并非 kubelet 稳定行为的一部分。
请不要在产品环境下依赖此末端的行为,也不要在自动化工具中使用此末端。
关于如何使用配置文件来配置 kubelet 行为的更多信息可参见 通过配置文件设置 kubelet 参数 文档。
生成配置文件
jq 命令以方便处理 JSON 数据。为了完成这里讲述的任务,
你需要安装 jq。如果你更希望手动提取 kubeletconfig 子对象,也可以对这里
的对应步骤做一些调整。
-
选择要重新配置的节点。在本例中,此节点的名称为
NODE_NAME。 -
使用以下命令在后台启动 kubectl 代理:
kubectl proxy --port=8001 &
-
运行以下命令从
configz端点中下载并解压配置。这个命令很长,因此在复制粘贴时要小心。 如果你使用 zsh,请注意常见的 zsh 配置要添加反斜杠转义 URL 中变量名称周围的大括号。 例如:在粘贴时,${NODE_NAME}将被重写为$\{NODE_NAME\}。 你必须在运行命令之前删除反斜杠,否则命令将失败。NODE_NAME="the-name-of-the-node-you-are-reconfiguring"; curl -sSL "http://localhost:8001/api/v1/nodes/${NODE_NAME}/proxy/configz" | jq '.kubeletconfig|.kind="KubeletConfiguration"|.apiVersion="kubelet.config.k8s.io/v1beta1"' > kubelet_configz_${NODE_NAME}
kind 和 apiVersion 添加到下载对象中,因为它们不是由 configz 末端
返回的。
修改配置文件
使用文本编辑器,改变上述操作生成的文件中一个参数。
例如,你或许会修改 QPS 参数 eventRecordQPS。
把配置文件推送到控制平面
用以下命令把编辑后的配置文件推送到控制平面:
kubectl -n kube-system create configmap my-node-config \
--from-file=kubelet=kubelet_configz_${NODE_NAME} \
--append-hash -o yaml
下面是合法响应的一个例子:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2017-09-14T20:23:33Z
name: my-node-config-gkt4c2m4b2
namespace: kube-system
resourceVersion: "119980"
selfLink: /api/v1/namespaces/kube-system/configmaps/my-node-config-gkt4c2m4b2
uid: 946d785e-998a-11e7-a8dd-42010a800006
data:
kubelet: |
{...}
你会在 kube-system 命名空间中创建 ConfigMap,因为 kubelet 是 Kubernetes 的系统组件。
--append-hash 选项给 ConfigMap 内容附加了一个简短校验和。
这对于先编辑后推送的工作流程很方便,
因为它自动并确定地为新 ConfigMap 生成新的名称。
在以下示例中,包含生成的哈希字符串的对象名被称为 CONFIG_MAP_NAME。
配置节点使用新的配置
kubectl edit node ${NODE_NAME}
在你的文本编辑器中,在 spec 下增添以下 YAML:
configSource:
configMap:
name: CONFIG_MAP_NAME
namespace: kube-system
kubeletConfigKey: kubelet
你必须同时指定 name、namespace 和 kubeletConfigKey 这三个属性。
kubeletConfigKey 这个参数通知 kubelet ConfigMap 中的哪个键下面包含所要的配置。
观察节点开始使用新配置
用 kubectl get node ${NODE_NAME} -o yaml 命令读取节点并检查 node.status.config 内容。
状态部分报告了对应 active(使用中的)配置、assigned(被赋予的)配置和
lastKnownGood(最近已知可用的)配置的配置源。
active是 kubelet 当前运行时所使用的版本。assigned参数是 kubelet 基于node.spec.configSource所解析出来的最新版本。lastKnownGood参数是 kubelet 的回退版本;如果在node.spec.configSource中 包含了无效的配置值,kubelet 可以回退到这个版本。
如果用本地配置部署节点,使其设置成默认值,这个 lastKnownGood 配置可能不存在。
在 kubelet 配置好后,将更新 lastKnownGood 为一个有效的 assigned 配置。
决定如何确定某配置成为 lastKnownGood 配置的细节并不在 API 保障范畴,
不过目前实现中采用了 10 分钟的宽限期。
你可以使用以下命令(使用 jq)过滤出配置状态:
kubectl get no ${NODE_NAME} -o json | jq '.status.config'
以下是一个响应示例:
{
"active": {
"configMap": {
"kubeletConfigKey": "kubelet",
"name": "my-node-config-9mbkccg2cc",
"namespace": "kube-system",
"resourceVersion": "1326",
"uid": "705ab4f5-6393-11e8-b7cc-42010a800002"
}
},
"assigned": {
"configMap": {
"kubeletConfigKey": "kubelet",
"name": "my-node-config-9mbkccg2cc",
"namespace": "kube-system",
"resourceVersion": "1326",
"uid": "705ab4f5-6393-11e8-b7cc-42010a800002"
}
},
"lastKnownGood": {
"configMap": {
"kubeletConfigKey": "kubelet",
"name": "my-node-config-9mbkccg2cc",
"namespace": "kube-system",
"resourceVersion": "1326",
"uid": "705ab4f5-6393-11e8-b7cc-42010a800002"
}
}
}
如果你没有安装 jq,你可以查看整个响应对象,查找其中的 node.status.config
部分。
如果发生错误,kubelet 会在 Node.Status.Config.Error 中显示出错误信息的结构体。
错误可能出现在列表理解节点状态配置错误信息中。
你可以在 kubelet 日志中搜索相同的文本以获取更多详细信息和有关错误的上下文。
做出更多的改变
按照下面的工作流程做出更多的改变并再次推送它们。
你每次推送一个 ConfigMap 的新内容时,kubeclt 的 --append-hash 选项都会给
ConfigMap 创建一个新的名称。
最安全的上线策略是首先创建一个新的 ConfigMap,然后更新节点以使用新的 ConfigMap。
重置节点以使用其本地默认配置
要重置节点,使其使用节点创建时使用的配置,可以用
kubectl edit node $ {NODE_NAME} 命令编辑节点,并删除 node.spec.configSource
字段。
观察节点正在使用本地默认配置
在删除此字段后,node.status.config 最终变成空,所有配置源都已重置为 nil。
这表示本地默认配置成为了 assigned、active 和 lastKnownGood 配置,
并且没有报告错误。
kubectl patch 示例
你可以使用几种不同的机制来更改节点的 configSource。
本例使用kubectl patch:
kubectl patch node ${NODE_NAME} -p "{\"spec\":{\"configSource\":{\"configMap\":{\"name\":\"${CONFIG_MAP_NAME}\",\"namespace\":\"kube-system\",\"kubeletConfigKey\":\"kubelet\"}}}}"
了解 Kubelet 如何为配置生成检查点
当为节点赋予新配置时,kubelet 会下载并解压配置负载为本地磁盘上的一组文件。
kubelet 还记录一些元数据,用以在本地跟踪已赋予的和最近已知良好的配置源,以便
kubelet 在重新启动时知道使用哪个配置,即使 API 服务器变为不可用。
在为配置信息和相关元数据生成检查点之后,如果检测到已赋予的配置发生改变,则 kubelet 退出。
当 kubelet 被 OS 级服务管理器(例如 systemd)重新启动时,它会读取新的元数据并使用新配置。
当记录的元数据已被完全解析时,意味着它包含选择一个指定的配置版本所需的所有信息
-- 通常是 UID 和 ResourceVersion。
这与 node.spec.configSource 形成对比,后者通过幂等的 namespace/name 声明来标识
目标 ConfigMap;kubelet 尝试使用此 ConfigMap 的最新版本。
当你在调试节点上问题时,可以检查 kubelet 的配置元数据和检查点。kubelet 的检查点目录结构是:
- --dynamic-config-dir (用于管理动态配置的根目录)
|-- meta
| - assigned (编码后的 kubeletconfig/v1beta1.SerializedNodeConfigSource 对象,对应赋予的配置)
| - last-known-good (编码后的 kubeletconfig/v1beta1.SerializedNodeConfigSource 对象,对应最近已知可用配置)
| - checkpoints
| - uid1 (用 uid1 来标识的对象版本目录)
| - resourceVersion1 (uid1 对象 resourceVersion1 版本下所有解压文件的目录)
| - ...
| - ...
理解 Node.Status.Config.Error 消息
下表描述了使用动态 kubelet 配置时可能发生的错误消息。 你可以在 kubelet 日志中搜索相同的文本来获取有关错误的其他详细信息和上下文。
| 错误信息 | 可能的原因 |
|---|---|
| failed to load config, see Kubelet log for details | kubelet 可能无法解析下载配置的有效负载,或者当尝试从磁盘中加载有效负载时,遇到文件系统错误。 |
| failed to validate config, see Kubelet log for details | 有效负载中的配置,与命令行标志所产生的覆盖配置以及特行门控的组合、配置文件本身、远程负载被 kubelet 判定为无效。 |
| invalid NodeConfigSource, exactly one subfield must be non-nil, but all were nil | 由于 API 服务器负责对 node.spec.configSource 执行验证,检查其中是否包含至少一个非空子字段,这个消息可能意味着 kubelet 比 API 服务器版本低,因而无法识别更新的源类型。 |
| failed to sync: failed to download config, see Kubelet log for details | kubelet 无法下载配置数据。可能是 node.spec.configSource 无法解析为具体的 API 对象,或者网络错误破坏了下载。处于此错误状态时,kubelet 将重新尝试下载。 |
| failed to sync: internal failure, see Kubelet log for details | kubelet 遇到了一些内部问题,因此无法更新其配置。 例如:发生文件系统错误或无法从内部缓存中读取对象。 |
| internal failure, see Kubelet log for details | 在对配置进行同步的循环之外操作配置时,kubelet 遇到了一些内部问题。 |
接下来
- 关于如何通过配置文件来配置 kubelet 的更多细节信息,可参阅 使用配置文件设置 kubelet 参数.
- 阅读 API 文档中
NodeConfigSource说明 - 查阅
KubeletConfiguration文献进一步了解 kubelet 配置信息。
24 - 声明网络策略
本文可以帮助你开始使用 Kubernetes 的 NetworkPolicy API 声明网络策略去管理 Pod 之间的通信
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
您的 Kubernetes 服务器版本必须不低于版本 v1.8. 要获知版本信息,请输入kubectl version.
你首先需要有一个支持网络策略的 Kubernetes 集群。已经有许多支持 NetworkPolicy 的网络提供商,包括:
创建一个nginx Deployment 并且通过服务将其暴露
为了查看 Kubernetes 网络策略是怎样工作的,可以从创建一个nginx Deployment 并且通过服务将其暴露开始
kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
将此 Deployment 以名为 nginx 的 Service 暴露出来:
kubectl expose deployment nginx --port=80
service/nginx exposed
上述命令创建了一个带有一个 nginx 的 Deployment,并将之通过名为 nginx 的
Service 暴露出来。名为 nginx 的 Pod 和 Deployment 都位于 default
名字空间内。
kubectl get svc,pod
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/kubernetes 10.100.0.1 <none> 443/TCP 46m
svc/nginx 10.100.0.16 <none> 80/TCP 33s
NAME READY STATUS RESTARTS AGE
po/nginx-701339712-e0qfq 1/1 Running 0 35s
通过从 Pod 访问服务对其进行测试
你应该可以从其它的 Pod 访问这个新的 nginx 服务。
要从 default 命名空间中的其它s Pod 来访问该服务。可以启动一个 busybox 容器:
kubectl run busybox --rm -ti --image=busybox /bin/sh
在你的 Shell 中,运行下面的命令:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
限制 nginx 服务的访问
如果想限制对 nginx 服务的访问,只让那些拥有标签 access: true 的 Pod 访问它,
那么可以创建一个如下所示的 NetworkPolicy 对象:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
NetworkPolicy 对象的名称必须是一个合法的 DNS 子域名.
podSelector。
你可以看到上面的策略选择的是带有标签 app=nginx 的 Pods。
此标签是被自动添加到 nginx Deployment 中的 Pod 上的。
如果 podSelector 为空,则意味着选择的是名字空间中的所有 Pods。
为服务指定策略
使用 kubectl 根据上面的 nginx-policy.yaml 文件创建一个 NetworkPolicy:
kubectl apply -f https://k8s.io/examples/service/networking/nginx-policy.yaml
networkpolicy.networking.k8s.io/access-nginx created
测试没有定义访问标签时访问服务
如果你尝试从没有设定正确标签的 Pod 中去访问 nginx 服务,请求将会超时:
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
在 Shell 中运行命令:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
wget: download timed out
定义访问标签后再次测试
创建一个拥有正确标签的 Pod,你将看到请求是被允许的:
kubectl run busybox --rm -ti --labels="access=true" --image=busybox -- /bin/sh
在 Shell 中运行命令:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
25 - 安全地清空一个节点
本页展示了如何在确保 PodDisruptionBudget 的前提下,安全地清空一个节点。
准备开始
您的 Kubernetes 服务器版本必须不低于版本 1.5.
要获知版本信息,请输入 kubectl version.
此任务假定你已经满足了以下先决条件:
- 使用的 Kubernetes 版本 >= 1.5。
- 以下两项,具备其一:
- 在节点清空期间,不要求应用程序具有高可用性
- 你已经了解了 PodDisruptionBudget 的概念, 并为需要它的应用程序配置了 PodDisruptionBudget。
(可选) 配置干扰预算
为了确保你的负载在维护期间仍然可用,你可以配置一个 PodDisruptionBudget。 如果可用性对于正在清空的该节点上运行或可能在该节点上运行的任何应用程序很重要, 首先 配置一个 PodDisruptionBudgets 并继续遵循本指南。
使用 kubectl drain 从服务中删除一个节点
在对节点执行维护(例如内核升级、硬件维护等)之前,
可以使用 kubectl drain 从节点安全地逐出所有 Pods。
安全的驱逐过程允许 Pod 的容器
体面地终止,
并确保满足指定的 PodDisruptionBudgets。
kubectl drain 将忽略节点上不能杀死的特定系统 Pod;
有关更多细节,请参阅
kubectl drain 文档。
kubectl drain 的成功返回,表明所有的 Pods(除了上一段中描述的被排除的那些),
已经被安全地逐出(考虑到期望的终止宽限期和你定义的 PodDisruptionBudget)。
然后就可以安全地关闭节点,
比如关闭物理机器的电源,如果它运行在云平台上,则删除它的虚拟机。
首先,确定想要清空的节点的名称。可以用以下命令列出集群中的所有节点:
kubectl get nodes
接下来,告诉 Kubernetes 清空节点:
kubectl drain <node name>
一旦它返回(没有报错), 你就可以下线此节点(或者等价地,如果在云平台上,删除支持该节点的虚拟机)。 如果要在维护操作期间将节点留在集群中,则需要运行:
kubectl uncordon <node name>
然后告诉 Kubernetes,它可以继续在此节点上调度新的 Pods。
并行清空多个节点
kubectl drain 命令一次只能发送给一个节点。
但是,你可以在不同的终端或后台为不同的节点并行地运行多个 kubectl drain 命令。
同时运行的多个 drain 命令仍然遵循你指定的 PodDisruptionBudget 。
例如,如果你有一个三副本的 StatefulSet,
并设置了一个 PodDisruptionBudget,指定 minAvailable: 2。
如果所有的三个 Pod 均就绪,并且你并行地发出多个 drain 命令,
那么 kubectl drain 只会从 StatefulSet 中逐出一个 Pod,
因为 Kubernetes 会遵守 PodDisruptionBudget 并确保在任何时候只有一个 Pod 不可用
(最多不可用 Pod 个数的计算方法:replicas - minAvailable)。
任何会导致就绪副本数量低于指定预算的清空操作都将被阻止。
驱逐 API
如果你不喜欢使用 kubectl drain (比如避免调用外部命令,或者更细化地控制 pod 驱逐过程), 你也可以用驱逐 API 通过编程的方式达到驱逐的效果。
首先应该熟悉使用 Kubernetes 语言客户端。
Pod 的 Eviction 子资源可以看作是一种策略控制的 DELETE 操作,作用于 Pod 本身。 要尝试驱逐(更准确地说,尝试 创建 一个 Eviction),需要用 POST 发出所尝试的操作。这里有一个例子:
policy/v1 驱逐在 v1.22+ 中可用。在之前版本中请使用 policy/v1beta1 。
{
"apiVersion": "policy/v1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
policy/v1 取代
{
"apiVersion": "policy/v1beta1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
你可以使用 curl 尝试驱逐:
curl -v -H 'Content-type: application/json' http://127.0.0.1:8080/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
API 可以通过以下三种方式之一进行响应:
- 如果驱逐被授权,那么 Pod 将被删掉,并且你会收到
200 OK, 就像你向 Pod 的 URL 发送了DELETE请求一样。 - 如果按照预算中规定,目前的情况不允许的驱逐,你会收到
429 Too Many Requests。 这通常用于对 一些 请求进行通用速率限制, 但这里我们的意思是:此请求 现在 不允许,但以后可能会允许。 目前,调用者不会得到任何Retry-After的提示,但在将来的版本中可能会得到。 - 如果有一些错误的配置,比如多个预算指向同一个 Pod,你将得到
500 Internal Server Error。
对于一个给定的驱逐请求,有两种情况:
- 没有匹配这个 Pod 的预算。这种情况,服务器总是返回
200 OK。 - 至少匹配一个预算。在这种情况下,上述三种回答中的任何一种都可能适用。
驱逐阻塞
在某些情况下,应用程序可能会到达一个中断状态,除了 429 或 500 之外,它将永远不会返回任何内容。 例如 ReplicaSet 创建的替换 Pod 没有变成就绪状态,或者被驱逐的最后一个 Pod 有很长的终止宽限期,就会发生这种情况。
在这种情况下,有两种可能的解决方案:
- 中止或暂停自动操作。调查应用程序卡住的原因,并重新启动自动化。
- 经过适当的长时间等待后,从集群中删除 Pod 而不是使用驱逐 API。
Kubernetes 并没有具体说明在这种情况下应该采取什么行为, 这应该由应用程序所有者和集群所有者紧密沟通,并达成对行动一致意见。
接下来
- 执行配置 PDB中的各个步骤, 保护你的应用
26 - 将重复的控制平面迁至云控制器管理器
Kubernetes v1.22 [beta]
云管理控制器是 云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件。 云控制器管理器使得你可以将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
通过分离 Kubernetes 和底层云基础设置之间的互操作性逻辑, 云控制器管理器组件使云提供商能够以不同于 Kubernetes 主项目的 步调发布新特征。
背景
作为云驱动提取工作
的一部分,所有特定于云的控制器都必须移出 kube-controller-manager。
所有在 kube-controller-manager 中运行云控制器的现有集群必须迁移到云驱动特定的 cloud-controller-manager 中运行控制器。
领导者迁移提供了一种机制,使得 HA 集群可以通过两个组件之间的共享资源锁定,
安全地将“特定于云”的控制器从 kube-controller-manager 和迁移到cloud-controller-manager,
同时升级复制的控制平面。
对于单节点控制平面,或者在升级过程中可以容忍控制器管理器不可用的情况,则不需要领导者迁移,并且可以忽略本指南。
领导者迁移可以通过在 kube-controller-manager 或 cloud-controller-manager 上设置 --enable-leader-migration 来启用。
领导者迁移仅在升级期间适用,并且可以安全地禁用,也可以在升级完成后保持启用状态。
本指南将引导你手动将控制平面从内置的云驱动的 kube-controller-manager 升级为
同时运行 kube-controller-manager 和 cloud-controller-manager。
如果使用工具来管理群集,请参阅对应工具和云驱动的文档以获取更多详细信息。
准备开始
假定控制平面正在运行 Kubernetes N 版本,并且要升级到 N+1 版本。
尽管可以在同一版本中进行迁移,但理想情况下,迁移应作为升级的一部分执行,以便可以更改配置与每个发布版本保持一致。
N 和 N+1的确切版本取决于各个云驱动。例如,如果云驱动构建了一个可与 Kubernetes 1.22 配合使用的 cloud-controller-manager,
则 N 可以为 1.21,N+1 可以为 1.22。
控制平面节点应运行 kube-controller-manager,并通过 --leader-elect=true 启用领导者选举。
从版本 N 开始,树内云驱动必须设置 --cloud-provider 标志,而且 cloud-controller-manager 尚未部署。
树外云驱动必须已经构建了一个实现领导者迁移的 cloud-controller-manager。
如果云驱动导入了 v0.21.0 或更高版本的 k8s.io/cloud-provider 和 k8s.io/controller-manager,
则可以进行领导者迁移。
但是,对 v0.22.0 以下的版本,领导者迁移是一项 Alpha 阶段功能,它需要启用特性门控 ControllerManagerLeaderMigration。
本指南假定每个控制平面节点的 kubelet 以静态 pod 的形式启动 kube-controller-manager
和 cloud-controller-manager,静态 pod 的定义在清单文件中。
如果组件以其他设置运行,请相应地调整步骤。
为了获得授权,本指南假定集群使用 RBAC。
如果其他授权模式授予 kube-controller-manager 和 cloud-controller-manager 组件权限,
请以与该模式匹配的方式授予所需的访问权限。
授予访问迁移 Lease 的权限
控制器管理器的默认权限仅允许访问其主 Lease 对象。为了使迁移正常进行,需要访问其他 Lease 对象。
你可以通过修改 system::leader-locking-kube-controller-manager 角色来授予
kube-controller-manager 对 Lease API 的完全访问权限。
本任务指南假定迁移 Lease 的名称为 cloud-provider-extraction-migration。
kubectl patch -n kube-system role 'system::leader-locking-kube-controller-manager' -p '{"rules": [ {"apiGroups":[ "coordination.k8s.io"], "resources": ["leases"], "resourceNames": ["cloud-provider-extraction-migration"], "verbs": ["create", "list", "get", "update"] } ]}' --type=merge
对 system::leader-locking-cloud-controller-manager 角色执行相同的操作。
kubectl patch -n kube-system role 'system::leader-locking-cloud-controller-manager' -p '{"rules": [ {"apiGroups":[ "coordination.k8s.io"], "resources": ["leases"], "resourceNames": ["cloud-provider-extraction-migration"], "verbs": ["create", "list", "get", "update"] } ]}' --type=merge
初始领导者迁移配置
领导者迁移可以选择使用一个表示控制器到管理器分配状态的配置文件。
目前,对于树内云驱动,kube-controller-manager 运行 route、service 和 cloud-node-lifecycle。
以下示例配置显示了分配。
领导者迁移可以不指定配置来启用。请参阅 默认配置 以获取更多详细信息。
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1beta1
leaderName: cloud-provider-extraction-migration
resourceLock: leases
controllerLeaders:
- name: route
component: kube-controller-manager
- name: service
component: kube-controller-manager
- name: cloud-node-lifecycle
component: kube-controller-manager
在每个控制平面节点上,将内容保存到 /etc/leadermigration.conf 中,
并更新 kube-controller-manager 清单,以便将文件安装在容器内的同一位置。
另外,更新相同的清单,添加以下参数:
--enable-leader-migration在控制器管理器上启用领导者迁移--leader-migration-config=/etc/leadermigration.conf设置配置文件
在每个节点上重新启动 kube-controller-manager。这时,kube-controller-manager
已启用领导者迁移,并准备进行迁移。
部署云控制器管理器
在 N+1 版本中,控制器到管理器分配的期望状态可以由新的配置文件表示,如下所示。
请注意,每个 controllerLeaders 的 component 字段从 kube-controller-manager 更改为 cloud-controller-manager。
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1beta1
leaderName: cloud-provider-extraction-migration
resourceLock: leases
controllerLeaders:
- name: route
component: cloud-controller-manager
- name: service
component: cloud-controller-manager
- name: cloud-node-lifecycle
component: cloud-controller-manager
当创建 N+1 版本的控制平面节点时,应将内容部署到 /etc/leadermigration.conf。
应该更新 cloud-controller-manager 清单,以与 N 版本的 kube-controller-manager 相同的方式挂载配置文件。
类似地,添加 --feature-gates=ControllerManagerLeaderMigration=true、--enable-leader-migration
和 --leader-migration-config=/etc/leadermigration.conf 到 cloud-controller-manager 的参数中。
使用已更新的 cloud-controller-manager 清单创建一个新的 N+1 版本的控制平面节点。
并且没有设置 kube-controller-manager 的 --cloud-provider 标志。
N+1 版本的 kube-controller-manager 不能启用领导者迁移,
因为在使用外部云驱动的情况下,它不再运行已迁移的控制器,因此不参与迁移。
请参阅云控制器管理器管理
了解有关如何部署 cloud-controller-manager 的更多细节。
升级控制平面
现在,控制平面包含 N 和 N+1 版本的节点。
N 版本的节点仅运行 kube-controller-manager,而 N+1 版本的节点同时运行
kube-controller-manager 和 cloud-controller-manager。
根据配置所指定,已迁移的控制器在 N 版本的 kube-controller-manager 或 N+1 版本的
cloud-controller-manager 下运行,
具体取决于哪个控制器管理器拥有迁移 Lease 对象。任何时候都不存在一个控制器在两个控制器管理器下运行。
以滚动的方式创建一个新的版本为 N+1 的控制平面节点,并将 N+1 版本中的一个关闭,
直到控制平面仅包含版本为 N+1 的节点。
如果需要从 N+1 版本回滚到 N 版本,则将启用了领导者迁移的 kube-controller-manager
且版本为 N 的节点添加回控制平面,每次替换 N+1 版本的一个,直到只有 N 版本的节点为止。
(可选)禁用领导者迁移
现在,控制平面已经升级,可以同时运行 N+1 版本的 kube-controller-manager 和 cloud-controller-manager 了。
领导者迁移已经完成工作,可以安全地禁用以节省一个 Lease 资源。
在将来可以安全地重新启用领导者迁移以完成回滚。
在滚动管理器中,更新 cloud-controller-manager 的清单以同时取消设置 --enable-leader-migration
和 --leader-migration-config= 标志,并删除 /etc/leadermigration.conf 的挂载。
最后删除 /etc/leadermigration.conf。
要重新启用领导者迁移,请重新创建配置文件,并将其挂载和启用领导者迁移的标志添加回到 cloud-controller-manager。
默认配置
从 Kubernetes 1.22 开始,领导者迁移提供了一个默认配置,它适用于默认的控制器到管理器分配。
可以通过设置 --enable-leader-migration,但不设置 --leader-migration-config= 来启用默认配置。
对于 kube-controller-manager 和 cloud-controller-manager,如果没有用参数来启用树内云驱动或者改变控制器属主,
则可以使用默认配置来避免手动创建配置文件。
接下来
- 阅读领导者迁移控制器管理器改进建议
27 - 开发云控制器管理器
Kubernetes v1.11 [beta]
组件 cloud-controller-manager 是 云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件。 云控制器管理器使得你可以将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
通过分离 Kubernetes 和底层云基础设置之间的互操作性逻辑, 云控制器管理器组件使云提供商能够以不同于 Kubernetes 主项目的 步调发布新特征。
背景
由于云驱动的开发和发布与 Kubernetes 项目本身步调不同,将特定于云环境
的代码抽象到 cloud-controller-manager 二进制组件有助于云厂商独立于
Kubernetes 核心代码推进其驱动开发。
Kubernetes 项目提供 cloud-controller-manager 的框架代码,其中包含 Go
语言的接口,便于你(或者你的云驱动提供者)接驳你自己的实现。
这意味着每个云驱动可以通过从 Kubernetes 核心代码导入软件包来实现一个
cloud-controller-manager;每个云驱动会通过调用
cloudprovider.RegisterCloudProvider 接口来注册其自身实现代码,从而更新
记录可用云驱动的全局变量。
开发
Out of Tree
要为你的云环境构建一个 out-of-tree 云控制器管理器:
- 使用满足 cloudprovider.Interface 的实现创建一个 Go 语言包。
- 使用来自 Kubernetes 核心代码库的 cloud-controller-manager 中的 main.go 作为 main.go 的模板。如上所述,唯一的区别应该是将导入的云包。
- 在
main.go中导入你的云包,确保你的包有一个init块来运行 cloudprovider.RegisterCloudProvider。
很多云驱动都将其控制器管理器代码以开源代码的形式公开。 如果你在开发一个新的 cloud-controller-manager,你可以选择某个 out-of-tree 云控制器管理器作为出发点。
In Tree
对于 in-tree 驱动,你可以将 in-tree 云控制器管理器作为群集中的 Daemonset 来运行。 有关详细信息,请参阅云控制器管理器管理。
28 - 开启服务拓扑
Kubernetes v1.21 [deprecated]
这项功能,特别是 Alpha 状态的 topologyKeys 字段,在 kubernetes v1.21 中已经弃用。
在 kubernetes v1.21 加入的拓扑感知提示
提供了类似的功能。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
您的 Kubernetes 服务器版本必须不低于版本 1.17. 要获知版本信息,请输入kubectl version.
服务拓扑(Service Topology) 使 服务 能够根据集群中的 Node 拓扑来路由流量。 比如,服务可以指定将流量优先路由到与客户端位于同一节点或者同一可用区域的端点上。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
您的 Kubernetes 服务器版本必须不低于版本 1.17. 要获知版本信息,请输入kubectl version.
需要下面列的先决条件,才能启用拓扑感知的服务路由:
- Kubernetes 1.17 或更新版本
- 配置 kube-proxy 以 iptables 或者 IPVS 模式运行
启用服务拓扑
Kubernetes v1.21 [deprecated]
要启用服务拓扑功能,需要为所有 Kubernetes 组件启用 ServiceTopology
特性门控:
--feature-gates="ServiceTopology=true`
接下来
29 - 控制节点上的 CPU 管理策略
Kubernetes v1.12 [beta]
按照设计,Kubernetes 对 pod 执行相关的很多方面进行了抽象,使得用户不必关心。 然而,为了正常运行,有些工作负载要求在延迟和/或性能方面有更强的保证。 为此,kubelet 提供方法来实现更复杂的负载放置策略,同时保持抽象,避免显式的放置指令。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
CPU 管理策略
默认情况下,kubelet 使用 CFS 配额 来执行 Pod 的 CPU 约束。 当节点上运行了很多 CPU 密集的 Pod 时,工作负载可能会迁移到不同的 CPU 核, 这取决于调度时 Pod 是否被扼制,以及哪些 CPU 核是可用的。 许多工作负载对这种迁移不敏感,因此无需任何干预即可正常工作。
然而,有些工作负载的性能明显地受到 CPU 缓存亲和性以及调度延迟的影响。 对此,kubelet 提供了可选的 CPU 管理策略,来确定节点上的一些分配偏好。
配置
CPU 管理策略通过 kubelet 参数 --cpu-manager-policy 来指定。支持两种策略:
none: 默认策略,表示现有的调度行为。static: 允许为节点上具有某些资源特征的 pod 赋予增强的 CPU 亲和性和独占性。
CPU 管理器定期通过 CRI 写入资源更新,以保证内存中 CPU 分配与 cgroupfs 一致。
同步频率通过新增的 Kubelet 配置参数 --cpu-manager-reconcile-period 来设置。
如果不指定,默认与 --node-status-update-frequency 的周期相同。
Static 策略的行为可以使用 --cpu-manager-policy-options 参数来微调。
该参数采用一个逗号分隔的 key=value 策略选项列表。
none 策略
none 策略显式地启用现有的默认 CPU 亲和方案,不提供操作系统调度器默认行为之外的亲和性策略。
通过 CFS 配额来实现 Guaranteed pods
和 Burstable pods
的 CPU 使用限制。
static 策略
static 策略针对具有整数型 CPU requests 的 Guaranteed Pod ,它允许该类 Pod
中的容器访问节点上的独占 CPU 资源。这种独占性是使用
cpuset cgroup 控制器 来实现的。
cpu_manager_state
来手动重置 CPU 管理器。
该策略管理一个共享 CPU 资源池,最初,该资源池包含节点上所有的 CPU 资源。可用
的独占性 CPU 资源数量等于节点的 CPU 总量减去通过 --kube-reserved 或 --system-reserved 参数保留的 CPU 。从1.17版本开始,CPU保留列表可以通过 kublet 的 '--reserved-cpus' 参数显式地设置。
通过 '--reserved-cpus' 指定的显式CPU列表优先于使用 '--kube-reserved' 和 '--system-reserved' 参数指定的保留CPU。 通过这些参数预留的 CPU 是以整数方式,按物理内
核 ID 升序从初始共享池获取的。 共享池是 BestEffort 和 Burstable pod 运行
的 CPU 集合。Guaranteed pod 中的容器,如果声明了非整数值的 CPU requests ,也将运行在共享池的 CPU 上。只有 Guaranteed pod 中,指定了整数型 CPU requests 的容器,才会被分配独占 CPU 资源。
--kube-reserved 和/或 --system-reserved 或
--reserved-cpus 来保证预留的 CPU 值大于零。
这是因为零预留 CPU 值可能使得共享池变空。
当 Guaranteed Pod 调度到节点上时,如果其容器符合静态分配要求,
相应的 CPU 会被从共享池中移除,并放置到容器的 cpuset 中。
因为这些容器所使用的 CPU 受到调度域本身的限制,所以不需要使用 CFS 配额来进行 CPU 的绑定。
换言之,容器 cpuset 中的 CPU 数量与 Pod 规约中指定的整数型 CPU limit 相等。
这种静态分配增强了 CPU 亲和性,减少了 CPU 密集的工作负载在节流时引起的上下文切换。
考虑以下 Pod 规格的容器:
spec:
containers:
- name: nginx
image: nginx
该 Pod 属于 BestEffort QoS 类型,因为其未指定 requests 或 limits 值。
所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
该 Pod 属于 Burstable QoS 类型,因为其资源 requests 不等于 limits,且未指定 cpu 数量。
所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "100Mi"
cpu: "1"
该 pod 属于 Burstable QoS 类型,因为其资源 requests 不等于 limits。
所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "200Mi"
cpu: "2"
该 Pod 属于 Guaranteed QoS 类型,因为其 requests 值与 limits相等。
同时,容器对 CPU 资源的限制值是一个大于或等于 1 的整数值。
所以,该 nginx 容器被赋予 2 个独占 CPU。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "1.5"
requests:
memory: "200Mi"
cpu: "1.5"
该 Pod 属于 Guaranteed QoS 类型,因为其 requests 值与 limits相等。
但是容器对 CPU 资源的限制值是一个小数。所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
该 Pod 属于 Guaranteed QoS 类型,因其指定了 limits 值,同时当未显式指定时,
requests 值被设置为与 limits 值相等。
同时,容器对 CPU 资源的限制值是一个大于或等于 1 的整数值。
所以,该 nginx 容器被赋予 2 个独占 CPU。
Static 策略选项
如果使用 full-pcpus-only 策略选项,static 策略总是会分配完整的物理核心。
你可以通过在 CPUManager 策略选项里加上 full-pcups-only=true 来启用该选项。
默认情况下,如果不使用该选项,static 策略会使用拓扑感知最适合的分配方法来分配 CPU。 在启用了 SMT 的系统上,此策略所分配是与硬件线程对应的、独立的虚拟核。 这会导致不同的容器共享相同的物理核心,该行为进而会导致 吵闹的邻居问题。
启用该选项之后,只有当一个 Pod 里所有容器的 CPU 请求都能够分配到完整的物理核心时,kubelet 才会接受该 Pod。
如果 Pod 没有被准入,它会被置于 Failed 状态,错误消息是 SMTAlignmentError。
30 - 控制节点上的拓扑管理策略
Kubernetes v1.18 [beta]
越来越多的系统利用 CPU 和硬件加速器的组合来支持对延迟要求较高的任务和高吞吐量的并行计算。 这类负载包括电信、科学计算、机器学习、金融服务和数据分析等。 此类混合系统即用于构造这些高性能环境。
为了获得最佳性能,需要进行与 CPU 隔离、内存和设备局部性有关的优化。 但是,在 Kubernetes 中,这些优化由各自独立的组件集合来处理。
拓扑管理器(Topology Manager) 是一个 kubelet 的一部分,旨在协调负责这些优化的一组组件。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
您的 Kubernetes 服务器版本必须不低于版本 v1.18. 要获知版本信息,请输入kubectl version.
拓扑管理器如何工作
在引入拓扑管理器之前, Kubernetes 中的 CPU 和设备管理器相互独立地做出资源分配决策。 这可能会导致在多处理系统上出现并非期望的资源分配;由于这些与期望相左的分配,对性能或延迟敏感的应用将受到影响。 这里的不符合期望意指,例如, CPU 和设备是从不同的 NUMA 节点分配的,因此会导致额外的延迟。
拓扑管理器是一个 Kubelet 组件,扮演信息源的角色,以便其他 Kubelet 组件可以做出与拓扑结构相对应的资源分配决定。
拓扑管理器为组件提供了一个称为 建议供应者(Hint Providers) 的接口,以发送和接收拓扑信息。 拓扑管理器具有一组节点级策略,具体说明如下。
拓扑管理器从 建议提供者 接收拓扑信息,作为表示可用的 NUMA 节点和首选分配指示的位掩码。 拓扑管理器策略对所提供的建议执行一组操作,并根据策略对提示进行约减以得到最优解;如果存储了与预期不符的建议,则该建议的优选字段将被设置为 false。 在当前策略中,首选的是最窄的优选掩码。 所选建议将被存储为拓扑管理器的一部分。 取决于所配置的策略,所选建议可用来决定节点接受或拒绝 Pod 。 之后,建议会被存储在拓扑管理器中,供 建议提供者 进行资源分配决策时使用。
启用拓扑管理器功能特性
对拓扑管理器的支持要求启用 TopologyManager
特性门控。
从 Kubernetes 1.18 版本开始,这一特性默认是启用的。
拓扑管理器作用域和策略
拓扑管理器目前:
- 对所有 QoS 类的 Pod 执行对齐操作
- 针对建议提供者所提供的拓扑建议,对请求的资源进行对齐
如果满足这些条件,则拓扑管理器将对齐请求的资源。
为了定制如何进行对齐,拓扑管理器提供了两种不同的方式:scope 和 policy。
scope 定义了资源对齐时你所希望使用的粒度(例如,是在 pod 还是 container 级别)。
policy 定义了对齐时实际使用的策略(例如,best-effort、restricted、single-numa-node 等等)。
可以在下文找到现今可用的各种 scopes 和 policies 的具体信息。
拓扑管理器作用域
拓扑管理器可以在以下不同的作用域内进行资源对齐:
container(默认)pod
在 kubelet 启动时,可以使用 --topology-manager-scope 标志来选择其中任一选项。
容器作用域
默认使用的是 container 作用域。
在该作用域内,拓扑管理器依次进行一系列的资源对齐, 也就是,对每一个容器(包含在一个 Pod 里)计算单独的对齐。 换句话说,在该特定的作用域内,没有根据特定的 NUMA 节点集来把容器分组的概念。 实际上,拓扑管理器会把单个容器任意地对齐到 NUMA 节点上。
容器分组的概念是在以下的作用域内特别实现的,也就是 pod 作用域。
Pod 作用域
使用命令行选项 --topology-manager-scope=pod 来启动 kubelet,就可以选择 pod 作用域。
该作用域允许把一个 Pod 里的所有容器作为一个分组,分配到一个共同的 NUMA 节点集。 也就是,拓扑管理器会把一个 Pod 当成一个整体, 并且试图把整个 Pod(所有容器)分配到一个单个的 NUMA 节点或者一个共同的 NUMA 节点集。 以下的例子说明了拓扑管理器在不同的场景下使用的对齐方式:
- 所有容器可以被分配到一个单一的 NUMA 节点;
- 所有容器可以被分配到一个共享的 NUMA 节点集。
整个 Pod 所请求的某种资源总量是根据 有效 request/limit 公式来计算的, 因此,对某一种资源而言,该总量等于以下数值中的最大值:
- 所有应用容器请求之和;
- 初始容器请求的最大值。
pod 作用域与 single-numa-node 拓扑管理器策略一起使用,
对于延时敏感的工作负载,或者对于进行 IPC 的高吞吐量应用程序,都是特别有价值的。
把这两个选项组合起来,你可以把一个 Pod 里的所有容器都放到一个单个的 NUMA 节点,
使得该 Pod 消除了 NUMA 之间的通信开销。
在 single-numa-node 策略下,只有当可能的分配方案中存在合适的 NUMA 节点集时,Pod 才会被接受。
重新考虑上述的例子:
- 节点集只包含单个 NUMA 节点时,Pod 就会被接受,
- 然而,节点集包含多个 NUMA 节点时,Pod 就会被拒绝 (因为满足该分配方案需要两个或以上的 NUMA 节点,而不是单个 NUMA 节点)。
简要地说,拓扑管理器首先计算出 NUMA 节点集,然后使用拓扑管理器策略来测试该集合, 从而决定拒绝或者接受 Pod。
拓扑管理器策略
拓扑管理器支持四种分配策略。
你可以通过 Kubelet 标志 --topology-manager-policy 设置策略。
所支持的策略有四种:
none(默认)best-effortrestrictedsingle-numa-node
none 策略
这是默认策略,不执行任何拓扑对齐。
best-effort 策略
对于 Guaranteed 类的 Pod 中的每个容器,具有 best-effort 拓扑管理策略的
kubelet 将调用每个建议提供者以确定资源可用性。
使用此信息,拓扑管理器存储该容器的首选 NUMA 节点亲和性。
如果亲和性不是首选,则拓扑管理器将存储该亲和性,并且无论如何都将 pod 接纳到该节点。
之后 建议提供者 可以在进行资源分配决策时使用这个信息。
restricted 策略
对于 Guaranteed 类 Pod 中的每个容器, 配置了 restricted 拓扑管理策略的 kubelet
调用每个建议提供者以确定其资源可用性。。
使用此信息,拓扑管理器存储该容器的首选 NUMA 节点亲和性。
如果亲和性不是首选,则拓扑管理器将从节点中拒绝此 Pod 。
这将导致 Pod 处于 Terminated 状态,且 Pod 无法被节点接纳。
一旦 Pod 处于 Terminated 状态,Kubernetes 调度器将不会尝试重新调度该 Pod。
建议使用 ReplicaSet 或者 Deployment 来重新部署 Pod。
还可以通过实现外部控制环,以启动对具有 Topology Affinity 错误的 Pod 的重新部署。
如果 Pod 被允许运行在某节点,则 建议提供者 可以在做出资源分配决定时使用此信息。
single-numa-node 策略
对于 Guaranteed 类 Pod 中的每个容器, 配置了 single-numa-nodde 拓扑管理策略的
kubelet 调用每个建议提供者以确定其资源可用性。
使用此信息,拓扑管理器确定单 NUMA 节点亲和性是否可能。
如果是这样,则拓扑管理器将存储此信息,然后 建议提供者 可以在做出资源分配决定时使用此信息。
如果不可能,则拓扑管理器将拒绝 Pod 运行于该节点。
这将导致 Pod 处于 Terminated 状态,且 Pod 无法被节点接受。
一旦 Pod 处于 Terminated 状态,Kubernetes 调度器将不会尝试重新调度该 Pod。
建议使用 ReplicaSet 或者 Deployment 来重新部署 Pod。
还可以通过实现外部控制环,以触发具有 Topology Affinity 错误的 Pod 的重新部署。
Pod 与拓扑管理器策略的交互
考虑以下 pod 规范中的容器:
spec:
containers:
- name: nginx
image: nginx
该 Pod 以 BestEffort QoS 类运行,因为没有指定资源 requests 或 limits。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
由于 requests 数少于 limits,因此该 Pod 以 Burstable QoS 类运行。
如果选择的策略是 none 以外的任何其他策略,拓扑管理器都会评估这些 Pod 的规范。
拓扑管理器会咨询建议提供者,获得拓扑建议。
若策略为 static,则 CPU 管理器策略会返回默认的拓扑建议,因为这些 Pod
并没有显式地请求 CPU 资源。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
此 Pod 以 Guaranteed QoS 类运行,因为其 requests 值等于 limits 值。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
example.com/deviceA: "1"
example.com/deviceB: "1"
requests:
example.com/deviceA: "1"
example.com/deviceB: "1"
因为未指定 CPU 和内存请求,所以 Pod 以 BestEffort QoS 类运行。
拓扑管理器将考虑以上两个 Pod。拓扑管理器将咨询建议提供者即 CPU 和设备管理器,以获取 Pod 的拓扑提示。
对于 Guaranteed 类的 CPU 请求数为整数的 Pod,static CPU 管理器策略将返回与 CPU 请求有关的提示,
而设备管理器将返回有关所请求设备的提示。
对于 Guaranteed 类的 CPU 请求可共享的 Pod,static CPU
管理器策略将返回默认的拓扑提示,因为没有排他性的 CPU 请求;而设备管理器
则针对所请求的设备返回有关提示。
在上述两种 Guaranteed Pod 的情况中,none CPU 管理器策略会返回默认的拓扑提示。
对于 BestEffort Pod,由于没有 CPU 请求,static CPU 管理器策略将发送默认提示,
而设备管理器将为每个请求的设备发送提示。
基于此信息,拓扑管理器将为 Pod 计算最佳提示并存储该信息,并且供 提示提供程序在进行资源分配时使用。
已知的局限性
- 拓扑管理器所能处理的最大 NUMA 节点个数是 8。若 NUMA 节点数超过 8, 枚举可能的 NUMA 亲和性并为之生成提示时会发生状态爆炸。
- 调度器不是拓扑感知的,所以有可能一个 Pod 被调度到一个节点之后,会因为拓扑管理器的缘故在该节点上启动失败。
31 - 搭建高可用的 Kubernetes Masters
Kubernetes 1.5 [alpha]
你可以在谷歌计算引擎(GCE)的 kubeup 或 kube-down 脚本中复制 Kubernetes Master。
本文描述了如何使用 kube-up/down 脚本来管理高可用(HA)的 Master,
以及如何使用 GCE 实现高可用控制节点。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
启动一个兼容高可用的集群
要创建一个新的兼容高可用的集群,你必须在 kubeup 脚本中设置以下标志:
-
MULTIZONE=true- 为了防止从不同于服务器的默认区域的区域中删除 kubelets 副本。 如果你希望在不同的区域运行副本,那么这一项是必需并且推荐的。 -
ENABLE_ETCD_QUORUM_READ=true- 确保从所有 API 服务器读取数据时将返回最新的数据。 如果为 true,读操作将被定向到主 etcd 副本。可以选择将这个值设置为 true, 那么读取将更可靠,但也会更慢。
你还可以指定一个 GCE 区域,在这里创建第一个主节点副本。设置以下标志:
KUBE_GCE_ZONE=zone- 将运行第一个主节点副本的区域。
下面的命令演示在 GCE europe-west1-b 区域中设置一个兼容高可用的集群:
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.sh
注意,上面的命令创建一个只有单一主节点的集群; 但是,你可以使用后续命令将新的主节点副本添加到集群中。
增加一个新的主节点副本
在创建了兼容高可用的集群之后,可以向其中添加主节点副本。
你可以使用带有如下标记的 kubeup 脚本添加主节点副本:
-
KUBE_REPLICATE_EXISTING_MASTER=true- 创建一个已经存在的主节点的副本。 -
KUBE_GCE_ZONE=zone-主节点副本将运行的区域。必须与其他副本位于同一区域。
你无需设置 MULTIZONE 或 ENABLE_ETCD_QUORUM_READS 标志,因为他们可以从兼容高可用的集群中继承。
使用下面的命令可以复制现有兼容高可用的集群上的 Master:
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
删除主节点副本
你可以使用一个 kube-down 脚本从高可用集群中删除一个主节点副本,并可以使用以下标记:
-
KUBE_DELETE_NODES=false- 限制删除 kubelets。 -
KUBE_GCE_ZONE=zone- 将移除主节点副本的区域。 -
KUBE_REPLICA_NAME=replica_name- (可选)要删除的主节点副本的名称。 如果为空:将删除给定区域中的所有副本。
使用下面的命令可以从一个现有的高可用集群中删除一个 Master副本:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.sh
处理主节点副本失败
如果高可用集群中的一个主节点副本失败,最佳实践是从集群中删除副本, 并在相同的区域中添加一个新副本。 下面的命令演示了这个过程:
- 删除失败的副本:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
- 在原有位置增加一个新副本:
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
高可用集群复制主节点的最佳实践
-
尝试将主节点副本放置在不同的区域。在某区域故障时,放置在该区域内的所有主机都将失败。 为了在区域故障中幸免,请同样将工作节点放置在多区域中 (详情请见多区域)。
-
不要使用具有两个主节点副本的集群。在双副本集群上达成一致需要在更改持久状态时 两个副本都处于运行状态。 因此,两个副本都是需要的,任一副本的失败都会将集群带入多数失败状态。 因此,就高可用而言,双副本集群不如单个副本集群。
-
添加主节点副本时,集群状态(etcd)会被复制到一个新实例。如果集群很大, 可能需要很长时间才能复制它的状态。 这个操作可以通过迁移 etcd 数据存储来加速, 详情参见 这里 (我们正在考虑在未来添加对迁移 etcd 数据存储的支持)。
实现说明

概述
每个主节点副本将以以下模式运行以下组件:
-
etcd 实例: 所有实例将会以共识方式组建集群;
-
API 服务器: 每个服务器将与本地 etcd 通信——集群中的所有 API 服务器都可用;
-
控制器、调度器和集群自动扩缩器:将使用租约机制 —— 每个集群中只有一个实例是可用的;
-
插件管理器:每个管理器将独立工作,试图保持插件同步。
此外,在 API 服务器前面将有一个负载均衡器,用于将外部和内部通信路由到他们。
负载均衡
启动第二个主节点副本时,将创建一个包含两个副本的负载均衡器, 并将第一个副本的 IP 地址提升为负载均衡器的 IP 地址。 类似地,在删除倒数第二个主节点副本之后,将删除负载均衡器, 并将其 IP 地址分配给最后一个剩余的副本。 请注意,创建和删除负载均衡器是复杂的操作,可能需要一些时间(约20分钟)来同步。
主节点服务 & kubelets
Kubernetes 并不试图在其服务中保持 apiserver 的列表为最新, 相反,它将将所有访问请求指向外部 IP:
- 在拥有一个主节点的集群中,IP 指向单一的主节点,
- 在拥有多个主节点的集群中,IP 指向主节点前面的负载均衡器。
类似地,kubelets 将使用外部 IP 与主节点通信。
主节点证书
Kubernetes 为每个副本的外部公共 IP 和本地 IP 生成主节点 TLS 证书。 副本的临时公共 IP 没有证书; 要通过其临时公共 IP 访问副本,必须跳过 TLS 检查。
etcd 集群
为了允许 etcd 组建集群,需开放 etcd 实例之间通信所需的端口(用于集群内部通信)。 为了使这种部署安全,etcd 实例之间的通信使用 SSL 进行鉴权。
API 服务器标识
Kubernetes v1.20 [alpha]
使用 API 服务器标识功能需要启用特性门控,
该功能默认不启用。
你可以在启动 API 服务器 的时候启用特性门控 APIServerIdentity 来激活 API 服务器标识:
kube-apiserver \
--feature-gates=APIServerIdentity=true \
# …其他标记照常
在启动引导过程中,每个 kube-apiserver 会给自己分配一个唯一 ID。
该 ID 的格式是 kube-apiserver-{UUID}。
每个 kube-apiserver 会在 kube-system 名字空间 里创建一个 Lease 对象。
Lease 对象的名字是 kube-apiserver 的唯一 ID。
Lease 对象包含一个标签 k8s.io/component=kube-apiserver。
每个 kube-apiserver 每过 IdentityLeaseRenewIntervalSeconds(默认是 10 秒)就会刷新它的 Lease 对象。
每个 kube-apiserver 每过 IdentityLeaseDurationSeconds(默认是 3600 秒)也会检查所有 kube-apiserver 的标识 Lease 对象,
并且会删除超过 IdentityLeaseDurationSeconds 时间还没被刷新的 Lease 对象。
可以在 kube-apiserver 的 identity-lease-renew-interval-seconds
和 identity-lease-duration-seconds 标记里配置 IdentityLeaseRenewIntervalSeconds 和 IdentityLeaseDurationSeconds。
启用该功能是使用 HA API 服务器协调相关功能(例如,StorageVersionAPI 特性门控)的前提条件。
拓展阅读
32 - 改变默认 StorageClass
本文展示了如何改变默认的 Storage Class,它用于为没有特殊需求的 PersistentVolumeClaims 配置 volumes。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
为什么要改变默认存储类?
取决于安装模式,你的 Kubernetes 集群可能和一个被标记为默认的已有 StorageClass 一起部署。 这个默认的 StorageClass 以后将被用于动态的为没有特定存储类需求的 PersistentVolumeClaims 配置存储。更多细节请查看 PersistentVolumeClaim 文档。
预先安装的默认 StorageClass 可能不能很好的适应你期望的工作负载;例如,它配置的存储可能太过昂贵。 如果是这样的话,你可以改变默认 StorageClass,或者完全禁用它以防止动态配置存储。
删除默认 StorageClass 可能行不通,因为它可能会被你集群中的扩展管理器自动重建。 请查阅你的安装文档中关于扩展管理器的细节,以及如何禁用单个扩展。
改变默认 StorageClass
-
列出你的集群中的 StorageClasses:
kubectl get storageclass输出类似这样:
NAME PROVISIONER AGE standard (default) kubernetes.io/gce-pd 1d gold kubernetes.io/gce-pd 1d默认 StorageClass 以
(default)标记。
-
标记默认 StorageClass 非默认:
默认 StorageClass 的注解
storageclass.kubernetes.io/is-default-class设置为true。 注解的其它任意值或者缺省值将被解释为false。要标记一个 StorageClass 为非默认的,你需要改变它的值为
false:kubectl patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'这里的
standard是你选择的 StorageClass 的名字。
-
标记一个 StorageClass 为默认的:
和前面的步骤类似,你需要添加/设置注解
storageclass.kubernetes.io/is-default-class=true。kubectl patch storageclass <your-class-name> -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'请注意,最多只能有一个 StorageClass 能够被标记为默认。 如果它们中有两个或多个被标记为默认,Kubernetes 将忽略这个注解, 也就是它将表现为没有默认 StorageClass。
-
验证你选用的 StorageClass 为默认的:
kubectl get storageclass输出类似这样:
NAME PROVISIONER AGE standard kubernetes.io/gce-pd 1d gold (default) kubernetes.io/gce-pd 1d
接下来
- 进一步了解 PersistentVolumes
33 - 更改 PersistentVolume 的回收策略
本文展示了如何更改 Kubernetes PersistentVolume 的回收策略。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
为什么要更改 PersistentVolume 的回收策略
PersistentVolumes 可以有多种回收策略,包括 "Retain"、"Recycle" 和 "Delete"。 对于动态配置的 PersistentVolumes 来说,默认回收策略为 "Delete"。 这表示当用户删除对应的 PersistentVolumeClaim 时,动态配置的 volume 将被自动删除。 如果 volume 包含重要数据时,这种自动行为可能是不合适的。 那种情况下,更适合使用 "Retain" 策略。 使用 "Retain" 时,如果用户删除 PersistentVolumeClaim,对应的 PersistentVolume 不会被删除。 相反,它将变为 Released 状态,表示所有的数据可以被手动恢复。
更改 PersistentVolume 的回收策略
-
列出你集群中的 PersistentVolumes
kubectl get pv输出类似于这样:
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE pvc-b6efd8da-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim1 10s pvc-b95650f8-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim2 6s pvc-bb3ca71d-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim3 3s这个列表同样包含了绑定到每个卷的 claims 名称,以便更容易的识别动态配置的卷。
-
选择你的 PersistentVolumes 中的一个并更改它的回收策略:
kubectl patch pv <your-pv-name> -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'这里的
<your-pv-name>是你选择的 PersistentVolume 的名字。说明:在 Windows 系统上,你必须对包含空格的 JSONPath 模板加双引号(而不是像上面 一样为 Bash 环境使用的单引号)。这也意味着你必须使用单引号或者转义的双引号 来处理模板中的字面值。例如:
kubectl patch pv <your-pv-name> -p "{\"spec\":{\"persistentVolumeReclaimPolicy\":\"Retain\"}}"
-
验证你选择的 PersistentVolume 拥有正确的策略:
kubectl get pv输出类似于这样:
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE pvc-b6efd8da-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim1 40s pvc-b95650f8-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim2 36s pvc-bb3ca71d-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Retain Bound default/claim3 33s在前面的输出中,你可以看到绑定到申领
default/claim3的卷的回收策略为Retain。 当用户删除申领default/claim3时,它不会被自动删除。
接下来
- 进一步了解 PersistentVolumes
- 进一步了解 PersistentVolumeClaims
参考
- PersistentVolume
- PersistentVolumeClaim
- 参阅 PersistentVolumeSpec 的
persistentVolumeReclaimPolicy字段
34 - 自动扩缩集群 DNS 服务
本页展示了如何在集群中启用和配置 DNS 服务的自动扩缩功能。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
-
本指南假设你的节点使用 AMD64 或 Intel 64 CPU 架构
-
确保已启用 DNS 功能本身。
-
建议使用 Kubernetes 1.4.0 或更高版本。
确定是否 DNS 水平 水平自动扩缩特性已经启用
在 kube-system 命名空间中列出集群中的 Deployments :
kubectl get deployment --namespace=kube-system
输出类似如下这样:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
...
dns-autoscaler 1 1 1 1 ...
...
如果在输出中看到 “dns-autoscaler”,说明 DNS 水平自动扩缩已经启用,可以跳到 调优自动扩缩参数。
获取 DNS Deployment 的名称
列出集群内 kube-system 名字空间中的 DNS Deployment:
kubectl get deployment -l k8s-app=kube-dns --namespace=kube-system
输出类似如下这样:
NAME READY UP-TO-DATE AVAILABLE AGE
...
coredns 2/2 2 2 ...
...
如果看不到 DNS 服务的 Deployment,你也可以通过名字来查找:
kubectl get deployment --namespace=kube-system
并在输出中寻找名称为 coredns 或 kube-dns 的 Deployment。
你的扩缩目标为:
Deployment/<your-deployment-name>
其中 <your-deployment-name> 是 DNS Deployment 的名称。
例如,如果你的 DNS Deployment 名称是 coredns,则你的扩展目标是 Deployment/coredns。
k8s-app=kube-dns,
以便能够在原来使用 kube-dns 的集群中工作。
启用 DNS 水平自动扩缩
在本节,我们创建一个 Deployment。Deployment 中的 Pod 运行一个基于
cluster-proportional-autoscaler-amd64 镜像的容器。
创建文件 dns-horizontal-autoscaler.yaml,内容如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: dns-autoscaler
namespace: kube-system
labels:
k8s-app: dns-autoscaler
spec:
selector:
matchLabels:
k8s-app: dns-autoscaler
template:
metadata:
labels:
k8s-app: dns-autoscaler
spec:
containers:
- name: autoscaler
image: k8s.gcr.io/cluster-proportional-autoscaler-amd64:1.6.0
resources:
requests:
cpu: 20m
memory: 10Mi
command:
- /cluster-proportional-autoscaler
- --namespace=kube-system
- --configmap=dns-autoscaler
- --target=<SCALE_TARGET>
# When cluster is using large nodes(with more cores), "coresPerReplica" should dominate.
# If using small nodes, "nodesPerReplica" should dominate.
- --default-params={"linear":{"coresPerReplica":256,"nodesPerReplica":16,"min":1}}
- --logtostderr=true
- --v=2
在文件中,将 <SCALE_TARGET> 替换成扩缩目标。
进入到包含配置文件的目录中,输入如下命令创建 Deployment:
kubectl apply -f dns-horizontal-autoscaler.yaml
一个成功的命令输出是:
deployment.apps/dns-autoscaler created
DNS 水平自动扩缩在已经启用了。
调优自动扩缩参数
验证 dns-autoscaler ConfigMap 是否存在:
kubectl get configmap --namespace=kube-system
输出类似于:
NAME DATA AGE
...
dns-autoscaler 1 ...
...
修改该 ConfigMap 中的数据:
kubectl edit configmap dns-autoscaler --namespace=kube-system
找到如下这行内容:
linear: '{"coresPerReplica":256,"min":1,"nodesPerReplica":16}'
根据需要修改对应的字段。“min” 字段表明 DNS 后端的最小数量。 实际后端的数量通过使用如下公式来计算:
replicas = max( ceil( cores * 1/coresPerReplica ) , ceil( nodes * 1/nodesPerReplica ) )
注意 coresPerReplica 和 nodesPerReplica 的值都是整数。
背后的思想是,当一个集群使用具有很多核心的节点时,由 coresPerReplica 来控制。
当一个集群使用具有较少核心的节点时,由 nodesPerReplica 来控制。
其它的扩缩模式也是支持的,详情查看 cluster-proportional-autoscaler。
禁用 DNS 水平自动扩缩
有几个可供调优的 DNS 水平自动扩缩选项。具体使用哪个选项因环境而异。
选项 1:缩容 dns-autoscaler Deployment 至 0 个副本
该选项适用于所有场景。运行如下命令:
kubectl scale deployment --replicas=0 dns-autoscaler --namespace=kube-system
输出如下所示:
deployment.apps/dns-autoscaler scaled
验证当前副本数为 0:
kubectl get rs --namespace=kube-system
输出内容中,在 DESIRED 和 CURRENT 列显示为 0:
NAME DESIRED CURRENT READY AGE
...
dns-autoscaler-6b59789fc8 0 0 0 ...
...
选项 2:删除 dns-autoscaler Deployment
如果 dns-autoscaler 为你所控制,也就说没有人会去重新创建它,可以选择此选项:
kubectl delete deployment dns-autoscaler --namespace=kube-system
输出内容如下所示:
deployment.apps "dns-autoscaler" deleted
选项 3:从主控节点删除 dns-autoscaler 清单文件
如果 dns-autoscaler 在插件管理器 的控制之下,并且具有操作 master 节点的写权限,可以使用此选项。
登录到主控节点,删除对应的清单文件。 dns-autoscaler 对应的路径一般为:
/etc/kubernetes/addons/dns-horizontal-autoscaler/dns-horizontal-autoscaler.yaml
当清单文件被删除后,插件管理器将删除 dns-autoscaler Deployment。
理解 DNS 水平自动扩缩工作原理
-
cluster-proportional-autoscaler 应用独立于 DNS 服务部署。
-
autoscaler Pod 运行一个客户端,它通过轮询 Kubernetes API 服务器获取集群中节点和核心的数量。
-
系统会基于当前可调度的节点个数、核心数以及所给的扩缩参数,计算期望的副本数并应用到 DNS 后端。
-
扩缩参数和数据点会基于一个 ConfigMap 来提供给 autoscaler,它会在每次轮询时刷新它的参数表, 以与最近期望的扩缩参数保持一致。
-
扩缩参数是可以被修改的,而且不需要重建或重启 autoscaler Pod。
-
autoscaler 提供了一个控制器接口来支持两种控制模式:linear 和 ladder。
接下来
35 - 自定义 DNS 服务
本页说明如何配置 DNS Pod(s),以及定制集群中 DNS 解析过程。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
您的 Kubernetes 服务器版本必须不低于版本 v1.12. 要获知版本信息,请输入kubectl version.
你的集群必须运行 CoreDNS 插件。
文档迁移到 CoreDNS
解释了如何使用 kubeadm 从 kube-dns 迁移到 CoreDNS。
介绍
DNS 是使用集群插件 管理器自动启动的内置的 Kubernetes 服务。
从 Kubernetes v1.12 开始,CoreDNS 是推荐的 DNS 服务器,取代了 kube-dns。 如果
你的集群原来使用 kube-dns,你可能部署的仍然是 kube-dns 而不是 CoreDNS。
metadata.name 字段被命名为 kube-dns。
这是为了能够与依靠传统 kube-dns 服务名称来解析集群内部地址的工作负载具有更好的互操作性。
使用 kube-dns 作为服务名称可以抽离共有名称之后运行的是哪个 DNS 提供程序这一实现细节。
如果你在使用 Deployment 运行 CoreDNS,则该 Deployment 通常会向外暴露为一个具有
静态 IP 地址 Kubernetes 服务。
kubelet 使用 --cluster-dns=<DNS 服务 IP> 标志将 DNS 解析器的信息传递给每个容器。
DNS 名称也需要域名。 你可在 kubelet 中使用 --cluster-domain=<默认本地域名>
标志配置本地域名。
DNS 服务器支持正向查找(A 和 AAAA 记录)、端口发现(SRV 记录)、反向 IP 地址发现(PTR 记录)等。 更多信息,请参见Pod 和 服务的 DNS。
如果 Pod 的 dnsPolicy 设置为 "default",则它将从 Pod 运行所在节点继承名称解析配置。
Pod 的 DNS 解析行为应该与节点相同。
但请参阅已知问题。
如果你不想这样做,或者想要为 Pod 使用其他 DNS 配置,则可以
使用 kubelet 的 --resolv-conf 标志。 将此标志设置为 "" 可以避免 Pod 继承 DNS。
将其设置为有别于 /etc/resolv.conf 的有效文件路径可以设定 DNS 继承不同的配置。
CoreDNS
CoreDNS 是通用的权威 DNS 服务器,可以用作集群 DNS,符合 DNS 规范。
CoreDNS ConfigMap 选项
CoreDNS 是模块化且可插拔的 DNS 服务器,每个插件都为 CoreDNS 添加了新功能。 可以通过维护 Corefile,即 CoreDNS 配置文件, 来定制其行为。 集群管理员可以修改 CoreDNS Corefile 的 ConfigMap,以更改服务发现的工作方式。
在 Kubernetes 中,CoreDNS 安装时使用如下默认 Corefile 配置。
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Corefile 配置包括以下 CoreDNS 插件:
-
errors:错误记录到标准输出。
-
health:在 http://localhost:8080/health 处提供 CoreDNS 的健康报告。
-
ready:在端口 8181 上提供的一个 HTTP 末端,当所有能够 表达自身就绪的插件都已就绪时,在此末端返回 200 OK。
-
kubernetes:CoreDNS 将基于 Kubernetes 的服务和 Pod 的 IP 答复 DNS 查询。你可以在 CoreDNS 网站阅读更多细节。 你可以使用
ttl来定制响应的 TTL。默认值是 5 秒钟。TTL 的最小值可以是 0 秒钟, 最大值为 3600 秒。将 TTL 设置为 0 可以禁止对 DNS 记录进行缓存。pods insecure选项是为了与 kube-dns 向后兼容。你可以使用pods verified选项,该选项使得 仅在相同名称空间中存在具有匹配 IP 的 Pod 时才返回 A 记录。如果你不使用 Pod 记录,则可以使用pods disabled选项。
- prometheus:CoreDNS 的度量指标值以 Prometheus 格式在 http://localhost:9153/metrics 上提供。
- forward: 不在 Kubernetes 集群域内的任何查询都将转发到 预定义的解析器 (/etc/resolv.conf).
- cache:启用前端缓存。
- loop:检测到简单的转发环,如果发现死循环,则中止 CoreDNS 进程。
- reload:允许自动重新加载已更改的 Corefile。 编辑 ConfigMap 配置后,请等待两分钟,以使更改生效。
- loadbalance:这是一个轮转式 DNS 负载均衡器, 它在应答中随机分配 A、AAAA 和 MX 记录的顺序。
你可以通过修改 ConfigMap 来更改默认的 CoreDNS 行为。
使用 CoreDNS 配置存根域和上游域名服务器
CoreDNS 能够使用 forward 插件配置存根域和上游域名服务器。
示例
如果集群操作员在 10.150.0.1 处运行了 Consul 域服务器,
且所有 Consul 名称都带有后缀 .consul.local。要在 CoreDNS 中对其进行配置,
集群管理员可以在 CoreDNS 的 ConfigMap 中创建加入以下字段。
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
要显式强制所有非集群 DNS 查找通过特定的域名服务器(位于 172.16.0.1),可将 forward
指向该域名服务器,而不是 /etc/resolv.conf。
forward . 172.16.0.1
最终的包含默认的 Corefile 配置的 ConfigMap 如下所示:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . 172.16.0.1
cache 30
loop
reload
loadbalance
}
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
工具 kubeadm 支持将 kube-dns ConfigMap 自动转换为 CoreDNS ConfigMap。
CoreDNS 配置等同于 kube-dns
CoreDNS 不仅仅提供 kube-dns 的功能。
为 kube-dns 创建的 ConfigMap 支持 StubDomains 和 upstreamNameservers 转换为 CoreDNS 中的 forward 插件。
示例
用于 kubedns 的此示例 ConfigMap 描述了 stubdomains 和 upstreamnameservers:
apiVersion: v1
data:
stubDomains: |
{"abc.com" : ["1.2.3.4"], "my.cluster.local" : ["2.3.4.5"]}
upstreamNameservers: |
["8.8.8.8", "8.8.4.4"]
kind: ConfigMap
CoreDNS 中的等效配置将创建一个 Corefile:
-
针对 stubDomains:
abc.com:53 { errors cache 30 proxy . 1.2.3.4 } my.cluster.local:53 { errors cache 30 proxy . 2.3.4.5 }
带有默认插件的完整 Corefile:
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
federation cluster.local {
foo foo.feddomain.com
}
prometheus :9153
forward . 8.8.8.8 8.8.4.4
cache 30
}
abc.com:53 {
errors
cache 30
forward . 1.2.3.4
}
my.cluster.local:53 {
errors
cache 30
forward . 2.3.4.5
}
迁移到 CoreDNS
要从 kube-dns 迁移到 CoreDNS,此博客 提供了帮助用户将 kube-dns 替换为 CoreDNS。 集群管理员还可以使用部署脚本 进行迁移。
接下来
36 - 访问集群上运行的服务
本文展示了如何连接 Kubernetes 集群上运行的服务。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
访问集群上运行的服务
在 Kubernetes 里,节点、 Pod 和 服务 都有自己的 IP。 许多情况下,集群上的节点 IP、Pod IP 和某些服务 IP 是路由不可达的, 所以不能从集群之外访问它们,例如从你自己的台式机。
连接方式
你有多种可选方式从集群外连接节点、Pod 和服务:
- 通过公网 IP 访问服务
- 使用类型为
NodePort或LoadBalancer的服务,可以从外部访问它们。 请查阅服务 和 kubectl expose 文档。 - 取决于你的集群环境,你可以仅把服务暴露在你的企业网络环境中,也可以将其暴露在 因特网上。需要考虑暴露的服务是否安全,它是否有自己的用户认证?
- 将 Pod 放置于服务背后。如果要访问一个副本集合中特定的 Pod,例如用于调试目的, 请给 Pod 指定一个独特的标签并创建一个新服务选择该标签。
- 大部分情况下,都不需要应用开发者通过节点 IP 直接访问节点。
- 使用类型为
- 通过 Proxy 动词访问服务、节点或者 Pod
- 在访问远程服务之前,利用 API 服务器执行身份认证和鉴权。 如果你的服务不够安全,无法暴露到因特网中,或者需要访问节点 IP 上的端口, 又或者出于调试目的,可使用这种方式。
- 代理可能给某些应用带来麻烦
- 此方式仅适用于 HTTP/HTTPS
- 进一步的描述在这里
- 从集群中的 node 或者 pod 访问。
- 从集群中的一个节点或 Pod 访问
- 运行一个 Pod,然后使用 kubectl exec 连接到它的 Shell。从那个 Shell 连接其他的节点、Pod 和 服务
- 某些集群可能允许你 SSH 到集群中的节点。你可能可以从那儿访问集群服务。 这是一个非标准的方式,可能在一些集群上能工作,但在另一些上却不能。 浏览器和其他工具可能已经安装也可能没有安装。集群 DNS 可能不会正常工作。
发现内置服务
典型情况下,kube-system 名字空间中会启动集群的几个服务。
使用 kubectl cluster-info 命令获取这些服务的列表:
kubectl cluster-info
输出类似于:
Kubernetes master is running at https://104.197.5.247
elasticsearch-logging is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy
kibana-logging is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/kibana-logging/proxy
kube-dns is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/kube-dns/proxy
grafana is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
heapster is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/monitoring-heapster/proxy
这一输出显示了用 proxy 动词访问每个服务时可用的 URL。例如,此集群
(使用 Elasticsearch)启用了集群层面的日志。如果提供合适的凭据,可以通过
https://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/
访问,或通过一个 kubectl proxy 来访问:
http://localhost:8080/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/。
kubectl proxy。
手动构建 API 服务器代理 URLs
如前所述,你可以使用 kubectl cluster-info 命令取得服务的代理 URL。
为了创建包含服务末端、后缀和参数的代理 URLs,你可以在服务的代理 URL 中添加:
http://kubernetes_master_address/api/v1/namespaces/namespace_name/services/service_name[:port_name]/proxy
如果还没有为你的端口指定名称,你可以不用在 URL 中指定 port_name。
示例
-
如要访问 Elasticsearch 服务末端
_search?q=user:kimchy,你可以使用:http://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_search?q=user:kimchy
-
如要访问 Elasticsearch 集群健康信息
_cluster/health?pretty=true,你会使用:https://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_cluster/health?pretty=true`健康信息与下面的例子类似:
{ "cluster_name" : "kubernetes_logging", "status" : "yellow", "timed_out" : false, "number_of_nodes" : 1, "number_of_data_nodes" : 1, "active_primary_shards" : 5, "active_shards" : 5, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 5 }
-
要访问 https Elasticsearch 服务健康信息
_cluster/health?pretty=true,你会使用:https://104.197.5.247/api/v1/namespaces/kube-system/services/https:elasticsearch-logging/proxy/_cluster/health?pretty=true
通过 Web 浏览器访问集群中运行的服务
你或许能够将 API 服务器代理的 URL 放入浏览器的地址栏,然而:
- Web 服务器通常不能传递令牌,所以你可能需要使用基本(密码)认证。 API 服务器可以配置为接受基本认证,但你的集群可能并没有这样配置。
- 某些 Web 应用可能无法工作,特别是那些使用客户端 Javascript 构造 URL 的 应用,所构造的 URL 可能并不支持代理路径前缀。
37 - 调试 DNS 问题
这篇文章提供了一些关于 DNS 问题诊断的方法。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
你的集群必须使用了 CoreDNS 插件
或者其前身,kube-dns。
kubectl version.
创建一个简单的 Pod 作为测试环境
apiVersion: v1
kind: Pod
metadata:
name: dnsutils
namespace: default
spec:
containers:
- name: dnsutils
image: k8s.gcr.io/e2e-test-images/jessie-dnsutils:1.3
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
default 命名空间创建 pod。 服务的 DNS 名字解析取决于 pod 的命名空间。 详细信息请查阅
服务和 Pod 的 DNS。
使用上面的清单来创建一个 Pod:
kubectl apply -f https://k8s.io/examples/admin/dns/dnsutils.yaml
pod/dnsutils created
验证其状态:
kubectl get pods dnsutils
NAME READY STATUS RESTARTS AGE
dnsutils 1/1 Running 0 <some-time>
一旦 Pod 处于运行状态,你就可以在该环境里执行 nslookup。
如果你看到类似下列的内容,则表示 DNS 是正常运行的。
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10
Name: kubernetes.default
Address 1: 10.0.0.1
如果 nslookup 命令执行失败,请检查下列内容:
先检查本地的 DNS 配置
查看 resolv.conf 文件的内容 (阅读定制 DNS 服务 和 后文的已知问题 ,获取更多信息)
kubectl exec -ti dnsutils -- cat /etc/resolv.conf
验证 search 和 nameserver 的配置是否与下面的内容类似 (注意 search 根据不同的云提供商可能会有所不同):
search default.svc.cluster.local svc.cluster.local cluster.local google.internal c.gce_project_id.internal
nameserver 10.0.0.10
options ndots:5
下列错误表示 CoreDNS (或 kube-dns)插件或者相关服务出现了问题:
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
输出为:
Server: 10.0.0.10
Address 1: 10.0.0.10
nslookup: can't resolve 'kubernetes.default'
或者
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
nslookup: can't resolve 'kubernetes.default'
检查 DNS Pod 是否运行
使用 kubectl get pods 命令来验证 DNS Pod 是否运行。
kubectl get pods --namespace=kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
...
coredns-7b96bf9f76-5hsxb 1/1 Running 0 1h
coredns-7b96bf9f76-mvmmt 1/1 Running 0 1h
...
k8s-app 的值都应该是 kube-dns。
如果你发现没有 CoreDNS Pod 在运行,或者该 Pod 的状态是 failed 或者 completed, 那可能这个 DNS 插件在您当前的环境里并没有成功部署,你将需要手动去部署它。
检查 DNS Pod 里的错误
使用 kubectl logs 命令来查看 DNS 容器的日志信息。
kubectl logs --namespace=kube-system -l k8s-app=kube-dns
下列是一个正常运行的 CoreDNS 日志信息:
.:53
2018/08/15 14:37:17 [INFO] CoreDNS-1.2.2
2018/08/15 14:37:17 [INFO] linux/amd64, go1.10.3, 2e322f6
CoreDNS-1.2.2
linux/amd64, go1.10.3, 2e322f6
2018/08/15 14:37:17 [INFO] plugin/reload: Running configuration MD5 = 24e6c59e83ce706f07bcc82c31b1ea1c
查看是否日志中有一些可疑的或者意外的消息。
检查是否启用了 DNS 服务
使用 kubectl get service 命令来检查 DNS 服务是否已经启用。
kubectl get svc --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 1h
...
kube-dns 。
如果你已经创建了 DNS 服务,或者该服务应该是默认自动创建的但是它并没有出现, 请阅读调试服务 来获取更多信息。
DNS 的端点公开了吗?
你可以使用 kubectl get endpoints 命令来验证 DNS 的端点是否公开了。
kubectl get ep kube-dns --namespace=kube-system
NAME ENDPOINTS AGE
kube-dns 10.180.3.17:53,10.180.3.17:53 1h
如果你没看到对应的端点,请阅读 调试服务的端点部分。
若需要了解更多的 Kubernetes DNS 例子,请在 Kubernetes GitHub 仓库里查看 cluster-dns 示例。
DNS 查询有被接收或者执行吗?
你可以通过给 CoreDNS 的配置文件(也叫 Corefile)添加 log 插件来检查查询是否被正确接收。
CoreDNS 的 Corefile 被保存在一个叫 coredns 的 ConfigMap 里,使用下列命令来编辑它:
kubectl -n kube-system edit configmap coredns
然后按下面的例子给 Corefile 添加 log。
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
log
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
保存这些更改后,你可能会需要等待一到两分钟让 Kubernetes 把这些更改应用到 CoreDNS 的 Pod 里。
接下来,发起一些查询并依照前文所述查看日志信息,如果 CoreDNS 的 Pod 接收到这些查询, 你将可以在日志信息里看到它们。
下面是日志信息里的查询例子:
.:53
2018/08/15 14:37:15 [INFO] CoreDNS-1.2.0
2018/08/15 14:37:15 [INFO] linux/amd64, go1.10.3, 2e322f6
CoreDNS-1.2.0
linux/amd64, go1.10.3, 2e322f6
2018/09/07 15:29:04 [INFO] plugin/reload: Running configuration MD5 = 162475cdf272d8aa601e6fe67a6ad42f
2018/09/07 15:29:04 [INFO] Reloading complete
172.17.0.18:41675 - [07/Sep/2018:15:29:11 +0000] 59925 "A IN kubernetes.default.svc.cluster.local. udp 54 false 512" NOERROR qr,aa,rd,ra 106 0.000066649s
你的服务在正确的命名空间中吗?
未指定命名空间的 DNS 查询仅作用于 pod 所在的命名空间。
如果 pod 和服务的命名空间不相同,则 DNS 查询必须指定服务所在的命名空间。
该查询仅限于 pod 所在的名称空间:
kubectl exec -i -t dnsutils -- nslookup <service-name>
指定命名空间的查询:
kubectl exec -i -t dnsutils -- nslookup <service-name>.<namespace>
要进一步了解名字解析,请查看 服务和 Pod 的 DNS。
已知问题
有些 Linux 发行版本(比如 Ubuntu)默认使用一个本地的 DNS 解析器(systemd-resolved)。
systemd-resolved 会用一个存根文件(Stub File)来覆盖 /etc/resolv.conf 内容,
从而可能在上游服务器中解析域名产生转发环(forwarding loop)。 这个问题可以通过手动指定
kubelet 的 --resolv-conf 标志为正确的 resolv.conf(如果是 systemd-resolved,
则这个文件路径为 /run/systemd/resolve/resolv.conf)来解决。
kubeadm 会自动检测 systemd-resolved 并对应的更改 kubelet 的命令行标志。
Kubernetes 的安装并不会默认配置节点的 resolv.conf 文件来使用集群的 DNS 服务,因为这个配置对于不同的发行版本是不一样的。这个问题应该迟早会被解决的。
Linux 的 libc 限制 nameserver 只能有三个记录。不仅如此,对于 glibc-2.17-222
之前的版本(参见此 Issue 了解新版本的更新),search 的记录不能超过 6 个
( 详情请查阅这个 2005 年的 bug)。
Kubernetes 需要占用一个 nameserver 记录和三个search记录。
这意味着如果一个本地的安装已经使用了三个 nameserver 或者使用了超过三个
search 记录,而你的 glibc 版本也在有问题的版本列表中,那么有些配置很可能会丢失。
为了绕过 DNS nameserver 个数限制,节点可以运行 dnsmasq,以提供更多的
nameserver 记录。你也可以使用kubelet 的 --resolv-conf 标志来解决这个问题。
要想修复 DNS search 记录个数限制问题,可以考虑升级你的 Linux 发行版本,或者
升级 glibc 到一个不再受此困扰的版本。
使用扩展 DNS 设置,
Kubernetes 允许更多的 search 记录。
如果你使用 Alpine 3.3 或更早版本作为你的基础镜像,DNS 可能会由于 Alpine 中 一个已知的问题导致无法正常工作。 请查看这里获取更多信息。
接下来
38 - 通过名字空间共享集群
本页展示如何查看、使用和删除名字空间。 本页同时展示如何使用 Kubernetes 名字空间来划分集群。
准备开始
- 你已拥有一个配置好的 Kubernetes 集群。
- 你已对 Kubernetes 的 Pods , Services , 和 Deployments 有基本理解。
查看名字空间
- 列出集群中现有的名字空间:
kubectl get namespaces
NAME STATUS AGE
default Active 11d
kube-system Active 11d
kube-public Active 11d
初始状态下,Kubernetes 具有三个名字空间:
default无名字空间对象的默认名字空间kube-system由 Kubernetes 系统创建的对象的名字空间kube-public自动创建且被所有用户可读的名字空间(包括未经身份认证的)。此名字空间通常在某些资源在整个集群中可见且可公开读取时被集群使用。此名字空间的公共方面只是一个约定,而不是一个必要条件。
你还可以通过下列命令获取特定名字空间的摘要:
kubectl get namespaces <name>
或用下面的命令获取详细信息:
kubectl describe namespaces <name>
Name: default
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
Resource Limits
Type Resource Min Max Default
---- -------- --- --- ---
Container cpu - - 100m
请注意,这些详情同时显示了资源配额(如果存在)以及资源限制区间。
资源配额跟踪并聚合 Namespace 中资源的使用情况,并允许集群运营者定义 Namespace 可能消耗的 Hard 资源使用限制。
限制区间定义了单个实体在一个 Namespace 中可使用的最小/最大资源量约束。
参阅 准入控制: 限制区间
名字空间可以处于下列两个阶段中的一个:
Active名字空间正在被使用中Terminating名字空间正在被删除,且不能被用于新对象。
更多细节,参阅 API 参考中的命名空间。
创建名字空间
kube- 创建名字空间,因为它是为 Kubernetes 系统名字空间保留的。
-
新建一个名为
my-namespace.yaml的 YAML 文件,并写入下列内容:apiVersion: v1 kind: Namespace metadata: name: <insert-namespace-name-here>然后运行:
kubectl create -f ./my-namespace.yaml
-
或者,你可以使用下面的命令创建名字空间:
kubectl create namespace <insert-namespace-name-here>
请注意,名字空间的名称必须是一个合法的 DNS 标签。
可选字段 finalizers 允许观察者们在名字空间被删除时清除资源。记住如果指定了一个不存在的终结器,名字空间仍会被创建,但如果用户试图删除它,它将陷入 Terminating 状态。
更多有关 finalizers 的信息请查阅 设计文档 中名字空间部分。
删除名字空间
删除名字空间使用命令:
kubectl delete namespaces <insert-some-namespace-name>
删除是异步的,所以有一段时间你会看到名字空间处于 Terminating 状态。
使用 Kubernetes 名字空间细分你的集群
-
理解 default 名字空间
默认情况下,Kubernetes 集群会在配置集群时实例化一个 default 名字空间,用以存放集群所使用的默认 Pods、Services 和 Deployments 集合。
假设你有一个新的集群,你可以通过执行以下操作来内省可用的名字空间
kubectl get namespacesNAME STATUS AGE default Active 13m
-
创建新的名字空间
在本练习中,我们将创建两个额外的 Kubernetes 名字空间来保存我们的内容。
在某组织使用共享的 Kubernetes 集群进行开发和生产的场景中:
开发团队希望在集群中维护一个空间,以便他们可以查看用于构建和运行其应用程序的 Pods、Services 和 Deployments 列表。在这个空间里,Kubernetes 资源被自由地加入或移除, 对谁能够或不能修改资源的限制被放宽,以实现敏捷开发。
运维团队希望在集群中维护一个空间,以便他们可以强制实施一些严格的规程, 对谁可以或不可以操作运行生产站点的 Pods、Services 和 Deployments 集合进行控制。
该组织可以遵循的一种模式是将 Kubernetes 集群划分为两个名字空间:development 和 production。
让我们创建两个新的名字空间来保存我们的工作。
使用 kubectl 创建
development名字空间。kubectl create -f https://k8s.io/examples/admin/namespace-dev.json让我们使用 kubectl 创建
production名字空间。kubectl create -f https://k8s.io/examples/admin/namespace-prod.json为了确保一切正常,列出集群中的所有名字空间。
kubectl get namespaces --show-labelsNAME STATUS AGE LABELS default Active 32m <none> development Active 29s name=development production Active 23s name=production
-
在每个名字空间中创建 pod
Kubernetes 名字空间为集群中的 Pods、Services 和 Deployments 提供了作用域。
与一个名字空间交互的用户不会看到另一个名字空间中的内容。
为了演示这一点,让我们在
development名字空间中启动一个简单的 Deployment 和 Pod。kubectl create deployment snowflake --image=k8s.gcr.io/serve_hostname -n=development kubectl scale deployment snowflake --replicas=2 -n=development我们创建了一个副本个数为 2 的 Deployment,运行名为
snowflake的 Pod,其中包含一个负责提供主机名的基本容器。kubectl get deployment -n=developmentNAME READY UP-TO-DATE AVAILABLE AGE snowflake 2/2 2 2 2mkubectl get pods -l app=snowflake -n=developmentNAME READY STATUS RESTARTS AGE snowflake-3968820950-9dgr8 1/1 Running 0 2m snowflake-3968820950-vgc4n 1/1 Running 0 2m看起来还不错,开发人员能够做他们想做的事,而且他们不必担心会影响到
production名字空间下面的内容。让我们切换到
production名字空间,展示一下一个名字空间中的资源是如何对 另一个名字空间隐藏的。名字空间
production应该是空的,下面的命令应该不会返回任何东西。kubectl get deployment -n=production kubectl get pods -n=production生产环境下一般以养牛的方式运行负载,所以让我们创建一些 Cattle(牛)Pod。
kubectl create deployment cattle --image=k8s.gcr.io/serve_hostname -n=production kubectl scale deployment cattle --replicas=5 -n=production kubectl get deployment -n=productionNAME READY UP-TO-DATE AVAILABLE AGE cattle 5/5 5 5 10skubectl get pods -l app=cattle -n=productionNAME READY STATUS RESTARTS AGE cattle-2263376956-41xy6 1/1 Running 0 34s cattle-2263376956-kw466 1/1 Running 0 34s cattle-2263376956-n4v97 1/1 Running 0 34s cattle-2263376956-p5p3i 1/1 Running 0 34s cattle-2263376956-sxpth 1/1 Running 0 34s
此时,应该很清楚的展示了用户在一个名字空间中创建的资源对另一个名字空间是隐藏的。
随着 Kubernetes 中的策略支持的发展,我们将扩展此场景,以展示如何为每个名字空间提供不同的授权规则。
理解使用名字空间的动机
单个集群应该能满足多个用户及用户组的需求(以下称为 “用户社区”)。
Kubernetes 名字空间 帮助不同的项目、团队或客户去共享 Kubernetes 集群。
名字空间通过以下方式实现这点:
- 为名字设置作用域.
- 为集群中的部分资源关联鉴权和策略的机制。
使用多个名字空间是可选的。
每个用户社区都希望能够与其他社区隔离开展工作。
每个用户社区都有自己的:
- 资源(pods、服务、 副本控制器等等)
- 策略(谁能或不能在他们的社区里执行操作)
- 约束(该社区允许多少配额,等等)
集群运营者可以为每个唯一用户社区创建名字空间。
名字空间为下列内容提供唯一的作用域:
- 命名资源(避免基本的命名冲突)
- 将管理权限委派给可信用户
- 限制社区资源消耗的能力
用例包括:
- 作为集群运营者, 我希望能在单个集群上支持多个用户社区。
- 作为集群运营者,我希望将集群分区的权限委派给这些社区中的受信任用户。
- 作为集群运营者,我希望能限定每个用户社区可使用的资源量,以限制对使用同一集群的其他用户社区的影响。
- 作为群集用户,我希望与我的用户社区相关的资源进行交互,而与其他用户社区在该集群上执行的操作无关。
理解名字空间和 DNS
当你创建服务时,Kubernetes
会创建相应的 DNS 条目。
此条目的格式为 <服务名称>.<名字空间名称>.svc.cluster.local。
这意味着如果容器使用 <服务名称>,它将解析为名字空间本地的服务。
这对于在多个名字空间(如开发、暂存和生产)中使用相同的配置非常有用。
如果要跨名字空间访问,则需要使用完全限定的域名(FQDN)。
接下来
39 - 通过配置文件设置 Kubelet 参数
通过保存在硬盘的配置文件设置 kubelet 的部分配置参数,这可以作为命令行参数的替代。
建议通过配置文件的方式提供参数,因为这样可以简化节点部署和配置管理。
创建配置文件
KubeletConfiguration 结构体定义了可以通过文件配置的 Kubelet 配置子集,
配置文件必须是这个结构体中参数的 JSON 或 YAML 表现形式。 确保 kubelet 可以读取该文件。
下面是一个 Kubelet 配置文件示例:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
address: "192.168.0.8",
port: 20250,
serializeImagePulls: false,
evictionHard:
memory.available: "200Mi"
在这个示例中, Kubelet 被设置为在地址 192.168.0.8 端口 20250 上提供服务,以并行方式拖拽镜像, 当可用内存低于 200Mi 时, kubelet 将会开始驱逐 Pods。 没有声明的其余配置项都将使用默认值,除非使用命令行参数来重载。 命令行中的参数将会覆盖配置文件中的对应值。
启动通过配置文件配置的 Kubelet 进程
kubeadmin init 创建你的集群的时候请使用 kubelet-config。
更多细节请阅读使用 kubeadm 配置 kubelet
启动 Kubelet 需要将 --config 参数设置为 Kubelet 配置文件的路径。Kubelet 将从此文件加载其配置。
请注意,命令行参数与配置文件有相同的值时,就会覆盖配置文件中的该值。 这有助于确保命令行 API 的向后兼容性。
请注意,kubelet 配置文件中的相对文件路径是相对于 kubelet 配置文件的位置解析的, 而命令行参数中的相对路径是相对于 kubelet 的当前工作目录解析的。
请注意,命令行参数和 Kubelet 配置文件的某些默认值不同。
如果设置了 --config,并且没有通过命令行指定值,则 KubeletConfiguration
版本的默认值生效。在上面的例子中,version 是 kubelet.config.k8s.io/v1beta1。
接下来
- 参阅
KubeletConfiguration进一步学习 kubelet 的配置。
40 - 配置 API 对象配额
本文讨论如何为 API 对象配置配额,包括 PersistentVolumeClaim 和 Service。 配额限制了可以在命名空间中创建的特定类型对象的数量。 你可以在 ResourceQuota 对象中指定配额。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
创建命名空间
创建一个命名空间以便本例中创建的资源和集群中的其余部分相隔离。
kubectl create namespace quota-object-example
创建 ResourceQuota
下面是一个 ResourceQuota 对象的配置文件:
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-quota-demo
spec:
hard:
persistentvolumeclaims: "1"
services.loadbalancers: "2"
services.nodeports: "0"
创建 ResourceQuota:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-objects.yaml --namespace=quota-object-example
查看 ResourceQuota 的详细信息:
kubectl get resourcequota object-quota-demo --namespace=quota-object-example --output=yaml
输出结果表明在 quota-object-example 命名空间中,至多只能有一个 PersistentVolumeClaim, 最多两个 LoadBalancer 类型的服务,不能有 NodePort 类型的服务。
status:
hard:
persistentvolumeclaims: "1"
services.loadbalancers: "2"
services.nodeports: "0"
used:
persistentvolumeclaims: "0"
services.loadbalancers: "0"
services.nodeports: "0"
创建 PersistentVolumeClaim
下面是一个 PersistentVolumeClaim 对象的配置文件:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-quota-demo
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
创建 PersistentVolumeClaim:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-objects-pvc.yaml --namespace=quota-object-example
确认已创建完 PersistentVolumeClaim:
kubectl get persistentvolumeclaims --namespace=quota-object-example
输出信息表明 PersistentVolumeClaim 存在并且处于 Pending 状态:
NAME STATUS
pvc-quota-demo Pending
尝试创建第二个 PersistentVolumeClaim
下面是第二个 PersistentVolumeClaim 的配置文件:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-quota-demo-2
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi
尝试创建第二个 PersistentVolumeClaim:
kubectl create -f https://k8s.io/examples/admin/resource/quota-objects-pvc-2.yaml --namespace=quota-object-example
输出信息表明第二个 PersistentVolumeClaim 没有创建成功,因为这会超出命名空间的配额。
persistentvolumeclaims "pvc-quota-demo-2" is forbidden:
exceeded quota: object-quota-demo, requested: persistentvolumeclaims=1,
used: persistentvolumeclaims=1, limited: persistentvolumeclaims=1
说明
下面这些字符串可被用来标识那些能被配额限制的 API 资源:
| String | API Object |
|---|---|
| "pods" | Pod |
| "services" | Service |
| "replicationcontrollers" | ReplicationController |
| "resourcequotas" | ResourceQuota |
| "secrets" | Secret |
| "configmaps" | ConfigMap |
| "persistentvolumeclaims" | PersistentVolumeClaim |
| "services.nodeports" | Service of type NodePort |
| "services.loadbalancers" | Service of type LoadBalancer |
清理
删除你的命名空间:
kubectl delete namespace quota-object-example
接下来
集群管理员参考
- 为命名空间配置默认的内存请求和限制
- 为命名空间配置默认的 CPU 请求和限制
- 为命名空间配置内存的最小和最大限制
- 为命名空间配置 CPU 的最小和最大限制
- 为命名空间配置 CPU 和内存配额
- 为命名空间配置 Pod 配额
应用开发者参考
41 - 配置资源不足时的处理方式
本页介绍如何使用 kubelet 配置资源不足时的处理方式。
当可用计算资源较少时,kubelet需要保证节点稳定性。
这在处理如内存和硬盘之类的不可压缩资源时尤为重要。
如果任意一种资源耗尽,节点将会变得不稳定。
驱逐信号
kubelet 支持按照以下表格中描述的信号触发驱逐决定。
每个信号的值在 description 列描述,基于 kubelet 摘要 API。
| 驱逐信号 | 描述 |
|---|---|
memory.available |
memory.available := node.status.capacity[memory] - node.stats.memory.workingSet |
nodefs.available |
nodefs.available := node.stats.fs.available |
nodefs.inodesFree |
nodefs.inodesFree := node.stats.fs.inodesFree |
imagefs.available |
imagefs.available := node.stats.runtime.imagefs.available |
imagefs.inodesFree |
imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree |
pid.available |
pid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc |
上面的每个信号都支持字面值或百分比的值。基于百分比的值的计算与每个信号对应的总容量相关。
memory.available 的值从 cgroupfs 获取,而不是通过类似 free -m 的工具。
这很重要,因为 free -m 不能在容器中工作,并且如果用户使用了
节点可分配资源
特性,资源不足的判定将同时在本地 cgroup 层次结构的终端用户 Pod 部分和根节点做出。
这个脚本
复现了与 kubelet 计算 memory.available 相同的步骤。
kubelet 将 inactive_file(意即活动 LRU 列表上基于文件后端的内存字节数)从计算中排除,
因为它假设内存在出现压力时将被回收。
kubelet 只支持两种文件系统分区。
nodefs文件系统,kubelet 将其用于卷和守护程序日志等。imagefs文件系统,容器运行时用于保存镜像和容器可写层。
imagefs 可选。kubelet 使用 cAdvisor 自动发现这些文件系统。
kubelet 不关心其它文件系统。当前不支持配置任何其它类型。
例如,在专用 filesytem 中存储卷和日志是 不可以 的。
在将来的发布中,kubelet将废除当前存在的
垃圾回收
机制,这种机制目前支持将驱逐操作作为对磁盘压力的响应。
驱逐阈值
kubelet支持指定驱逐阈值,用于触发 kubelet 回收资源。
每个阈值形式如下:
[eviction-signal][operator][quantity]
- 合法的
eviction-signal标志如上所示。 operator是所需的关系运算符,例如<。quantity是驱逐阈值值标志,例如1Gi。合法的标志必须匹配 Kubernetes 使用的数量表示。 驱逐阈值也可以使用%标记表示百分比。
举例说明,如果一个节点有 10Gi 内存,希望在可用内存下降到 1Gi 以下时引起驱逐操作,
则驱逐阈值可以使用下面任意一种方式指定(但不是两者同时)。
memory.available<10%memory.available<1Gi
软驱逐阈值
软驱逐阈值使用一对由驱逐阈值和管理员必须指定的宽限期组成的配置对。在超过宽限期前,kubelet不会采取任何动作回收和驱逐信号关联的资源。如果没有提供宽限期,kubelet启动时将报错。
此外,如果达到了软驱逐阈值,操作员可以指定从节点驱逐 pod 时,在宽限期内允许结束的 pod 的最大数量。
如果指定了 pod.Spec.TerminationGracePeriodSeconds 值,
kubelet 将使用它和宽限期二者中较小的一个。
如果没有指定,kubelet将立即终止 pod,而不会优雅结束它们。
软驱逐阈值的配置支持下列标记:
eviction-soft描述了驱逐阈值的集合(例如memory.available<1.5Gi),如果在宽限期之外满足条件将触发 pod 驱逐。eviction-soft-grace-period描述了驱逐宽限期的集合(例如memory.available=1m30s),对应于在驱逐 pod 前软驱逐阈值应该被控制的时长。eviction-max-pod-grace-period描述了当满足软驱逐阈值并终止 pod 时允许的最大宽限期值(秒数)。
硬驱逐阈值
硬驱逐阈值没有宽限期,一旦察觉,kubelet 将立即采取行动回收关联的短缺资源。
如果满足硬驱逐阈值,kubelet 将立即结束 Pod 而不是体面地终止它们。
硬驱逐阈值的配置支持下列标记:
eviction-hard描述了驱逐阈值的集合(例如memory.available<1Gi),如果满足条件将触发 Pod 驱逐。
kubelet 有如下所示的默认硬驱逐阈值:
memory.available<100Minodefs.available<10%imagefs.available<15%
在Linux节点上,默认值还包括 nodefs.inodesFree<5%。
驱逐监控时间间隔
kubelet 根据其配置的整理时间间隔计算驱逐阈值。
housekeeping-interval是容器管理时间间隔。
节点状态
kubelet 会将一个或多个驱逐信号映射到对应的节点状态。
如果满足硬驱逐阈值,或者满足独立于其关联宽限期的软驱逐阈值时,kubelet将报告节点处于压力下的状态。
下列节点状态根据相应的驱逐信号定义。
| 节点状态 | 驱逐信号 | 描述 |
|---|---|---|
MemoryPressure |
memory.available |
节点上可用内存量达到逐出阈值 |
DiskPressure |
nodefs.available, nodefs.inodesFree, imagefs.available, 或 imagefs.inodesFree |
节点或者节点的根文件系统或镜像文件系统上可用磁盘空间和 i 节点个数达到逐出阈值 |
PIDPressure |
pid.available |
在(Linux)节点上的可用进程标识符已降至驱逐阈值以下 |
kubelet 将以 --node-status-update-frequency 指定的频率连续报告节点状态更新,其默认值为 10s。
节点状态振荡
如果节点在软驱逐阈值的上下振荡,但没有超过关联的宽限期时,将引起对应节点的状态持续在 true 和 false 间跳变,并导致不好的调度结果。
为了防止这种振荡,可以定义下面的标志,用于控制 kubelet 从压力状态中退出之前必须等待的时间。
eviction-pressure-transition-period是kubelet从压力状态中退出之前必须等待的时长。
kubelet 将确保在设定的时间段内没有发现和指定压力条件相对应的驱逐阈值被满足时,才会将状态变回 false。
回收节点层级资源
如果满足驱逐阈值并超过了宽限期,kubelet将启动回收压力资源的过程,直到它发现低于设定阈值的信号为止。
kubelet 将尝试在驱逐终端用户 pod 前回收节点层级资源。
发现磁盘压力时,如果节点针对容器运行时配置有独占的 imagefs,kubelet回收节点层级资源的方式将会不同。
使用 imagefs
如果 nodefs 文件系统满足驱逐阈值,kubelet通过驱逐 pod 及其容器来释放磁盘空间。
如果 imagefs 文件系统满足驱逐阈值,kubelet通过删除所有未使用的镜像来释放磁盘空间。
未使用 imagefs
如果 nodefs 满足驱逐阈值,kubelet将以下面的顺序释放磁盘空间:
- 删除停止运行的 pod/container
- 删除全部没有使用的镜像
驱逐最终用户的 pod
如果 kubelet 在节点上无法回收足够的资源,kubelet将开始驱逐 pod。
kubelet 首先根据他们对短缺资源的使用是否超过请求来排除 pod 的驱逐行为,
然后通过优先级,
然后通过相对于 pod 的调度请求消耗急需的计算资源。
kubelet 按以下顺序对要驱逐的 pod 排名:
BestEffort或Burstable,其对短缺资源的使用超过了其请求,此类 pod 按优先级排序,然后使用高于请求。Guaranteedpod 和Burstablepod,其使用率低于请求,最后被驱逐。GuaranteedPod 只有为所有的容器指定了要求和限制并且它们相等时才能得到保证。 由于另一个 Pod 的资源消耗,这些 Pod 保证永远不会被驱逐。 如果系统守护进程(例如kubelet、docker、和journald)消耗的资源多于通过system-reserved或kube-reserved分配保留的资源,并且该节点只有Guaranteed或BurstablePod 使用少于剩余的请求,然后节点必须选择驱逐这样的 Pod 以保持节点的稳定性并限制意外消耗对其他 pod 的影响。 在这种情况下,它将首先驱逐优先级最低的 pod。
必要时,kubelet会在遇到 DiskPressure 时逐个驱逐 Pod 来回收磁盘空间。
如果 kubelet 响应 inode 短缺,它会首先驱逐服务质量最低的 Pod 来回收 inodes。
如果 kubelet 响应缺少可用磁盘,它会将 Pod 排在服务质量范围内,该服务会消耗大量的磁盘并首先结束这些磁盘。
使用 imagefs
如果是 nodefs 触发驱逐,kubelet将按 nodefs 用量 - 本地卷 + pod 的所有容器日志的总和对其排序。
如果是 imagefs 触发驱逐,kubelet将按 pod 所有可写层的用量对其进行排序。
未使用 imagefs
如果是 nodefs 触发驱逐,kubelet会根据磁盘的总使用情况对 pod 进行排序 - 本地卷 + 所有容器的日志及其可写层。
最小驱逐回收
在某些场景,驱逐 pod 会导致回收少量资源。这将导致 kubelet 反复碰到驱逐阈值。除此之外,对如 disk 这类资源的驱逐时比较耗时的。
为了减少这类问题,kubelet可以为每个资源配置一个 minimum-reclaim。
当 kubelet 发现资源压力时,kubelet将尝试至少回收驱逐阈值之下 minimum-reclaim 数量的资源。
例如使用下面的配置:
--eviction-hard=memory.available<500Mi,nodefs.available<1Gi,imagefs.available<100Gi
--eviction-minimum-reclaim="memory.available=0Mi,nodefs.available=500Mi,imagefs.available=2Gi"`
如果 memory.available 驱逐阈值被触发,kubelet 将保证 memory.available 至少为 500Mi。
对于 nodefs.available,kubelet 将保证 nodefs.available 至少为 1.5Gi。
对于 imagefs.available,kubelet 将保证 imagefs.available 至少为 102Gi,
直到不再有相关资源报告压力为止。
所有资源的默认 eviction-minimum-reclaim 值为 0。
调度器
当资源处于压力之下时,节点将报告状态。调度器将那种状态视为一种信号,阻止更多 pod 调度到这个节点上。
| 节点状态 | 调度器行为 |
|---|---|
MemoryPressure |
新的 BestEffort Pod 不会被调度到该节点 |
DiskPressure |
没有新的 Pod 会被调度到该节点 |
节点 OOM 行为
如果节点在 kubelet 回收内存之前经历了系统 OOM(内存不足)事件,它将基于
oom-killer 做出响应。
kubelet 基于 pod 的 service 质量为每个容器设置一个 oom_score_adj 值。
| Service 质量 | oom_score_adj |
|---|---|
Guaranteed |
-998 |
BestEffort |
1000 |
Burstable |
min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
如果 kubelet 在节点经历系统 OOM 之前无法回收内存,oom_killer 将基于它在节点上
使用的内存百分比算出一个 oom_score,并加上 oom_score_adj 得到容器的有效
oom_score,然后结束得分最高的容器。
预期的行为应该是拥有最低服务质量并消耗和调度请求相关内存量最多的容器第一个被结束,以回收内存。
和 pod 驱逐不同,如果一个 Pod 的容器是被 OOM 结束的,基于其 RestartPolicy,
它可能会被 kubelet 重新启动。
最佳实践
以下部分描述了资源外处理的最佳实践。
可调度资源和驱逐策略
考虑以下场景:
- 节点内存容量:
10Gi - 操作员希望为系统守护进程保留 10% 内存容量(内核、
kubelet等)。 - 操作员希望在内存用量达到 95% 时驱逐 pod,以减少对系统的冲击并防止系统 OOM 的发生。
为了促成这个场景,kubelet将像下面这样启动:
--eviction-hard=memory.available<500Mi
--system-reserved=memory=1.5Gi
这个配置的暗示是理解系统保留应该包含被驱逐阈值覆盖的内存数量。
要达到这个容量,要么某些 pod 使用了超过它们请求的资源,要么系统使用的内存超过 1.5Gi - 500Mi = 1Gi。
这个配置将保证在 pod 使用量都不超过它们配置的请求值时,如果可能立即引起内存压力并触发驱逐时,调度器不会将 pod 放到这个节点上。
DaemonSet
我们永远都不希望 kubelet 驱逐一个从 DaemonSet 派生的 Pod,因为这个 Pod 将立即被重建并调度回相同的节点。
目前,kubelet没有办法区分一个 Pod 是由 DaemonSet 还是其他对象创建。
如果/当这个信息可用时,kubelet 可能会预先将这些 pod 从提供给驱逐策略的候选集合中过滤掉。
总之,强烈推荐 DaemonSet 不要创建 BestEffort 的 Pod,防止其被识别为驱逐的候选 Pod。
相反,理想情况下 DaemonSet 应该启动 Guaranteed 的 pod。
现有的回收磁盘特性标签已被弃用
kubelet 已经按需求清空了磁盘空间以保证节点稳定性。
当磁盘驱逐成熟时,下面的 kubelet 标志将被标记为废弃的,以简化支持驱逐的配置。
| 现有标签 | 新标签 |
|---|---|
--image-gc-high-threshold |
--eviction-hard or eviction-soft |
--image-gc-low-threshold |
--eviction-minimum-reclaim |
--maximum-dead-containers |
deprecated |
--maximum-dead-containers-per-container |
deprecated |
--minimum-container-ttl-duration |
deprecated |
--low-diskspace-threshold-mb |
--eviction-hard or eviction-soft |
--outofdisk-transition-frequency |
--eviction-pressure-transition-period |
已知问题
以下部分描述了与资源外处理有关的已知问题。
kubelet 可能无法立即发现内存压力
kubelet当前通过以固定的时间间隔轮询 cAdvisor 来收集内存使用数据。如果内存使用在那个时间窗口内迅速增长,kubelet可能不能足够快的发现 MemoryPressure,OOMKiller将不会被调用。我们准备在将来的发行版本中通过集成 memcg 通知 API 来减小这种延迟。当超过阈值时,内核将立即告诉我们。
如果您想处理可察觉的超量使用而不要求极端精准,可以设置驱逐阈值为大约 75% 容量作为这个问题的变通手段。这将增强这个特性的能力,防止系统 OOM,并提升负载卸载能力,以再次平衡集群状态。
kubelet 可能会驱逐超过需求数量的 pod
由于状态采集的时间差,驱逐操作可能驱逐比所需的更多的 pod。将来可通过添加从根容器获取所需状态的能力 https://github.com/google/cadvisor/issues/1247 来减缓这种状况。
42 - 限制存储消耗
此示例演示了如何限制一个名字空间中的存储使用量。
演示中用到了以下资源:ResourceQuota, LimitRange 和 PersistentVolumeClaim。
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
场景:限制存储消耗
集群管理员代表用户群操作集群,管理员希望控制单个名称空间可以消耗多少存储空间以控制成本。
管理员想要限制:
- 名字空间中持久卷申领(persistent volume claims)的数量
- 每个申领(claim)可以请求的存储量
- 名字空间可以具有的累计存储量
使用 LimitRange 限制存储请求
将 LimitRange 添加到名字空间会为存储请求大小强制设置最小值和最大值。
存储是通过 PersistentVolumeClaim 来发起请求的。
执行限制范围控制的准入控制器会拒绝任何高于或低于管理员所设阈值的 PVC。
在此示例中,请求 10Gi 存储的 PVC 将被拒绝,因为它超过了最大 2Gi。
apiVersion: v1
kind: LimitRange
metadata:
name: storagelimits
spec:
limits:
- type: PersistentVolumeClaim
max:
storage: 2Gi
min:
storage: 1Gi
当底层存储提供程序需要某些最小值时,将会用到所设置最小存储请求值。 例如,AWS EBS volumes 的最低要求为 1Gi。
使用 StorageQuota 限制 PVC 数目和累计存储容量
管理员可以限制某个名字空间中的 PVCs 个数以及这些 PVCs 的累计容量。 新 PVCs 请求如果超过任一上限值将被拒绝。
在此示例中,名字空间中的第 6 个 PVC 将被拒绝,因为它超过了最大计数 5。 或者,当与上面的 2Gi 最大容量限制结合在一起时,意味着 5Gi 的最大配额 不能支持 3 个都是 2Gi 的 PVC。 后者实际上是向名字空间请求 6Gi 容量,而该命令空间已经设置上限为 5Gi。
apiVersion: v1
kind: ResourceQuota
metadata:
name: storagequota
spec:
hard:
persistentvolumeclaims: "5"
requests.storage: "5Gi"
小结
限制范围对象可以用来设置可请求的存储量上限,而资源配额对象则可以通过申领计数和 累计存储容量有效地限制名字空间耗用的存储量。 这两种机制使得集群管理员能够规划其集群存储预算而不会发生任一项目超量分配的风险。
43 - 静态加密 Secret 数据
本文展示如何启用和配置静态 Secret 数据的加密
准备开始
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
- 需要 etcd v3 或者更高版本
配置并确定是否已启用静态数据加密
kube-apiserver 的参数 --experimental-encryption-provider-config 控制 API 数据在 etcd 中的加密方式。
下面提供一个配置示例。
理解静态数据加密
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- identity: {}
- aesgcm:
keys:
- name: key1
secret: c2VjcmV0IGlzIHNlY3VyZQ==
- name: key2
secret: dGhpcyBpcyBwYXNzd29yZA==
- aescbc:
keys:
- name: key1
secret: c2VjcmV0IGlzIHNlY3VyZQ==
- name: key2
secret: dGhpcyBpcyBwYXNzd29yZA==
- secretbox:
keys:
- name: key1
secret: YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY=
每个 resources 数组项目是一个单独的完整的配置。
resources.resources 字段是要加密的 Kubernetes 资源名称(resource 或 resource.group)的数组。
providers 数组是可能的加密 provider 的有序列表。
每个条目只能指定一个 provider 类型(可以是 identity 或 aescbc,但不能在同一个项目中同时指定)。
列表中的第一个 provider 用于加密进入存储的资源。 当从存储器读取资源时,与存储的数据匹配的所有 provider 将按顺序尝试解密数据。 如果由于格式或密钥不匹配而导致没有 provider 能够读取存储的数据,则会返回一个错误,以防止客户端访问该资源。
Providers:
| 名称 | 加密类型 | 强度 | 速度 | 密钥长度 | 其它事项 |
|---|---|---|---|---|---|
identity |
无 | N/A | N/A | N/A | 不加密写入的资源。当设置为第一个 provider 时,资源将在新值写入时被解密。 |
aescbc |
填充 PKCS#7 的 AES-CBC | 最强 | 快 | 32字节 | 建议使用的加密项,但可能比 secretbox 稍微慢一些。 |
secretbox |
XSalsa20 和 Poly1305 | 强 | 更快 | 32字节 | 较新的标准,在需要高度评审的环境中可能不被接受。 |
aesgcm |
带有随机数的 AES-GCM | 必须每 200k 写入一次 | 最快 | 16, 24 或者 32字节 | 建议不要使用,除非实施了自动密钥循环方案。 |
kms |
使用信封加密方案:数据使用带有 PKCS#7 填充的 AES-CBC 通过数据加密密钥(DEK)加密,DEK 根据 Key Management Service(KMS)中的配置通过密钥加密密钥(Key Encryption Keys,KEK)加密 | 最强 | 快 | 32字节 | 建议使用第三方工具进行密钥管理。为每个加密生成新的 DEK,并由用户控制 KEK 轮换来简化密钥轮换。配置 KMS 提供程序 |
每个 provider 都支持多个密钥 - 在解密时会按顺序使用密钥,如果是第一个 provider,则第一个密钥用于加密。
在 EncryptionConfig 中保存原始的加密密钥与不加密相比只会略微地提升安全级别。
请使用 kms 驱动以获得更强的安全性。
默认情况下,identity 驱动被用来对 etcd 中的 Secret 提供保护,
而这个驱动不提供加密能力。
EncryptionConfiguration 的引入是为了能够使用本地管理的密钥来在本地加密 Secret 数据。
使用本地管理的密钥来加密 Secret 能够保护数据免受 etcd 破坏的影响,不过无法针对 主机被侵入提供防护。 这是因为加密的密钥保存在主机上的 EncryptionConfig YAML 文件中,有经验的入侵者 仍能访问该文件并从中提取出加密密钥。
封套加密(Envelope Encryption)引入了对独立密钥的依赖,而这个密钥并不保存在 Kubernetes 中。 在这种情况下下,入侵者需要攻破 etcd、kube-apiserver 和第三方的 KMS 驱动才能获得明文数据,因而这种方案提供了比本地保存加密密钥更高的安全级别。
加密你的数据
创建一个新的加密配置文件:
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET>
- identity: {}
遵循如下步骤来创建一个新的 secret:
-
生成一个 32 字节的随机密钥并进行 base64 编码。如果你在 Linux 或 Mac OS X 上,请运行以下命令:
head -c 32 /dev/urandom | base64
- 将这个值放入到 secret 字段中。
- 设置
kube-apiserver的--experimental-encryption-provider-config参数,将其指向 配置文件所在位置。 - 重启你的 API server。
验证数据已被加密
数据在写入 etcd 时会被加密。重新启动你的 kube-apiserver 后,任何新创建或更新的密码在存储时都应该被加密。
如果想要检查,你可以使用 etcdctl 命令行程序来检索你的加密内容。
-
创建一个新的 secret,名称为
secret1,命名空间为default:kubectl create secret generic secret1 -n default --from-literal=mykey=mydata
-
使用 etcdctl 命令行,从 etcd 中读取 secret:
ETCDCTL_API=3 etcdctl get /registry/secrets/default/secret1 [...] | hexdump -C这里的
[...]是用来连接 etcd 服务的额外参数。
-
验证存储的密钥前缀是否为
k8s:enc:aescbc:v1:,这表明aescbcprovider 已加密结果数据。 -
通过 API 检索,验证 secret 是否被正确解密:
kubectl describe secret secret1 -n default其输出应该是
mykey: bXlkYXRh,mydata数据是被加密过的,请参阅 解密 Secret 了解如何完全解码 Secret 内容。
确保所有 Secret 都被加密
由于 Secret 是在写入时被加密,因此对 Secret 执行更新也会加密该内容。
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
上面的命令读取所有 Secret,然后使用服务端加密来更新其内容。
轮换解密密钥
在不发生停机的情况下更改 Secret 需要多步操作,特别是在有多个 kube-apiserver 进程正在运行的
高可用环境中。
- 生成一个新密钥并将其添加为所有服务器上当前提供程序的第二个密钥条目
- 重新启动所有
kube-apiserver进程以确保每台服务器都可以使用新密钥进行解密 - 将新密钥设置为
keys数组中的第一个条目,以便在配置中使用其进行加密 - 重新启动所有
kube-apiserver进程以确保每个服务器现在都使用新密钥进行加密 - 运行
kubectl get secrets --all-namespaces -o json | kubectl replace -f -以用新密钥加密所有现有的秘密 - 在使用新密钥备份 etcd 后,从配置中删除旧的解密密钥并更新所有密钥
如果只有一个 kube-apiserver,第 2 步可能可以忽略。
解密所有数据
要禁用 rest 加密,请将 identity provider 作为配置中的第一个条目:
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- identity: {}
- aescbc:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET>
并重新启动所有 kube-apiserver 进程。然后运行:
kubectl get secrets -all-namespaces -o json | kubectl replace -f -`
以强制解密所有 secret。