클러스터 관리
쿠버네티스 클러스터 생성 또는 관리에 관련된 로우-레벨(lower-level)의 세부 정보를 설명한다.
클러스터 관리 개요는 쿠버네티스 클러스터를 생성하거나 관리하는 모든 사람들을 위한 것이다.
핵심 쿠버네티스 개념에 어느 정도 익숙하다고 가정한다.
클러스터 계획
쿠버네티스 클러스터를 계획, 설정 및 구성하는 방법에 대한 예는 시작하기에 있는 가이드를 참고한다.
이 문서에 나열된 솔루션을 배포판 이라고 한다.
참고:
모든 배포판이 활발하게 유지되는 것은 아니다. 최신 버전의 쿠버네티스에서 테스트된
배포판을 선택한다.가이드를 선택하기 전에 고려해야 할 사항은 다음과 같다.
- 컴퓨터에서 쿠버네티스를 한번 사용해보고 싶은가? 아니면, 고가용 멀티 노드 클러스터를 만들고 싶은가?
사용자의 필요에 따라 가장 적합한 배포판을 선택한다.
- 구글 쿠버네티스 엔진(Google Kubernetes Engine)과 같은 클라우드 제공자의 쿠버네티스 클러스터 호스팅 을 사용할 것인가?
아니면, 자체 클러스터를 호스팅 할 것인가?
- 클러스터가 온-프레미스 환경 에 있나? 아니면, 클라우드(IaaS) 에 있나?
쿠버네티스는 하이브리드 클러스터를 직접 지원하지는 않는다. 대신 여러 클러스터를 설정할 수 있다.
- 온-프레미스 환경에 쿠버네티스 를 구성하는 경우,
어떤 네트워킹 모델이 가장 적합한 지 고려한다.
- 쿠버네티스를 "베어 메탈" 하드웨어 에서 실행할 것인가? 아니면, 가상 머신(VM) 에서 실행할 것인가?
- 클러스터만 실행할 것인가? 아니면, 쿠버네티스 프로젝트 코드를 적극적으로 개발 하는 것을 기대하는가?
만약 후자라면, 활발하게 개발이 진행되고 있는 배포판을 선택한다. 일부 배포판은 바이너리 릴리스만 사용하지만,
더 다양한 선택을 제공한다.
- 클러스터를 실행하는 데 필요한 컴포넌트에 익숙해지자.
클러스터 관리
클러스터 보안
kubelet 보안
선택적 클러스터 서비스
1 - 인증서
클러스터를 위한 인증서를 생성하기 위해서는, 인증서를 참고한다.
2 - 리소스 관리
애플리케이션을 배포하고 서비스를 통해 노출했다. 이제 무엇을 해야 할까? 쿠버네티스는 확장과 업데이트를 포함하여, 애플리케이션 배포를 관리하는 데 도움이 되는 여러 도구를 제공한다. 더 자세히 설명할 기능 중에는 구성 파일과 레이블이 있다.
리소스 구성 구성하기
많은 애플리케이션들은 디플로이먼트 및 서비스와 같은 여러 리소스를 필요로 한다. 여러 리소스의 관리는 동일한 파일에 그룹화하여 단순화할 수 있다(YAML에서 --- 로 구분). 예를 들면 다음과 같다.
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
단일 리소스와 동일한 방식으로 여러 리소스를 생성할 수 있다.
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
리소스는 파일에 표시된 순서대로 생성된다. 따라서, 스케줄러가 디플로이먼트와 같은 컨트롤러에서 생성한 서비스와 관련된 파드를 분산시킬 수 있으므로, 서비스를 먼저 지정하는 것이 가장 좋다.
kubectl apply 는 여러 개의 -f 인수도 허용한다.
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
그리고 개별 파일 대신 또는 추가로 디렉터리를 지정할 수 있다.
kubectl apply -f https://k8s.io/examples/application/nginx/
kubectl 은 접미사가 .yaml, .yml 또는 .json 인 파일을 읽는다.
동일한 마이크로서비스 또는 애플리케이션 티어(tier)와 관련된 리소스를 동일한 파일에 배치하고, 애플리케이션과 연관된 모든 파일을 동일한 디렉터리에 그룹화하는 것이 좋다. 애플리케이션의 티어가 DNS를 사용하여 서로 바인딩되면, 스택의 모든 컴포넌트를 함께 배포할 수 있다.
URL을 구성 소스로 지정할 수도 있다. 이는 GitHub에 체크인된 구성 파일에서 직접 배포하는 데 편리하다.
kubectl apply -f https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
kubectl에서의 대량 작업
kubectl 이 대량으로 수행할 수 있는 작업은 리소스 생성만이 아니다. 또한 다른 작업을 수행하기 위해, 특히 작성한 동일한 리소스를 삭제하기 위해 구성 파일에서 리소스 이름을 추출할 수도 있다.
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
두 개의 리소스가 있는 경우, 리소스/이름 구문을 사용하여 커맨드 라인에서 둘다 모두 지정할 수도 있다.
kubectl delete deployments/my-nginx services/my-nginx-svc
리소스가 많을 경우, -l 또는 --selector 를 사용하여 지정된 셀렉터(레이블 쿼리)를 지정하여 레이블별로 리소스를 필터링하는 것이 더 쉽다.
kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
kubectl 은 입력을 받아들이는 것과 동일한 구문으로 리소스 이름을 출력하므로, $() 또는 xargs 를 사용하여 작업을 연결할 수 있다.
kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service | xargs -i kubectl get {}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
위의 명령을 사용하여, 먼저 examples/application/nginx/ 에 리소스를 생성하고 -o name 출력 형식으로 생성한 리소스를 출력한다(각 리소스를 resource/name으로 출력).
그런 다음 "service"만 grep 한 다음 kubectl get 으로 출력한다.
특정 디렉터리 내의 여러 서브 디렉터리에서 리소스를 구성하는 경우, --filename,-f 플래그와 함께 --recursive 또는 -R 을 지정하여, 서브 디렉터리에 대한 작업을 재귀적으로 수행할 수도 있다.
예를 들어, 리소스 유형별로 구성된 개발 환경에 필요한 모든 매니페스트를 보유하는 project/k8s/development 디렉터리가 있다고 가정하자.
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
기본적으로, project/k8s/development 에서 대량 작업을 수행하면, 서브 디렉터리를 처리하지 않고, 디렉터리의 첫 번째 레벨에서 중지된다. 다음 명령을 사용하여 이 디렉터리에 리소스를 생성하려고 하면, 오류가 발생할 것이다.
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
대신, 다음과 같이 --filename,-f 플래그와 함께 --recursive 또는 -R 플래그를 지정한다.
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
--recursive 플래그는 kubectl {create,get,delete,describe,rollout} 등과 같이 --filename,-f 플래그를 허용하는 모든 작업에서 작동한다.
--recursive 플래그는 여러 개의 -f 인수가 제공될 때도 작동한다.
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
kubectl 에 대해 더 자세히 알고 싶다면, 명령줄 도구 (kubectl)를 참조한다.
효과적인 레이블 사용
지금까지 사용한 예는 모든 리소스에 최대 한 개의 레이블만 적용하는 것이었다. 세트를 서로 구별하기 위해 여러 레이블을 사용해야 하는 많은 시나리오가 있다.
예를 들어, 애플리케이션마다 app 레이블에 다른 값을 사용하지만, 방명록 예제와 같은 멀티-티어 애플리케이션은 각 티어를 추가로 구별해야 한다. 프론트엔드는 다음의 레이블을 가질 수 있다.
labels:
app: guestbook
tier: frontend
Redis 마스터와 슬레이브는 프론트엔드와 다른 tier 레이블을 가지지만, 아마도 추가로 role 레이블을 가질 것이다.
labels:
app: guestbook
tier: backend
role: master
그리고
labels:
app: guestbook
tier: backend
role: slave
레이블은 레이블로 지정된 차원에 따라 리소스를 분할하고 사용할 수 있게 한다.
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-slave-2q2yf 1/1 Running 0 1m guestbook backend slave
guestbook-redis-slave-qgazl 1/1 Running 0 1m guestbook backend slave
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp=guestbook,role=slave
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
카나리(canary) 디플로이먼트
여러 레이블이 필요한 또 다른 시나리오는 동일한 컴포넌트의 다른 릴리스 또는 구성의 디플로이먼트를 구별하는 것이다. 새 릴리스가 완전히 롤아웃되기 전에 실제 운영 트래픽을 수신할 수 있도록 새로운 애플리케이션 릴리스(파드 템플리트의 이미지 태그를 통해 지정됨)의 카나리 를 이전 릴리스와 나란히 배포하는 것이 일반적이다.
예를 들어, track 레이블을 사용하여 다른 릴리스를 구별할 수 있다.
기본(primary), 안정(stable) 릴리스에는 값이 stable 인 track 레이블이 있다.
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
그런 다음 서로 다른 값(예: canary)으로 track 레이블을 전달하는 방명록 프론트엔드의 새 릴리스를 생성하여, 두 세트의 파드가 겹치지 않도록 할 수 있다.
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
프론트엔드 서비스는 레이블의 공통 서브셋을 선택하여(즉, track 레이블 생략) 두 레플리카 세트에 걸쳐 있으므로, 트래픽이 두 애플리케이션으로 리디렉션된다.
selector:
app: guestbook
tier: frontend
안정 및 카나리 릴리스의 레플리카 수를 조정하여 실제 운영 트래픽을 수신할 각 릴리스의 비율을 결정한다(이 경우, 3:1).
확신이 들면, 안정 릴리스의 track을 새로운 애플리케이션 릴리스로 업데이트하고 카나리를 제거할 수 있다.
보다 구체적인 예시는, Ghost 배포에 대한 튜토리얼을 확인한다.
레이블 업데이트
새로운 리소스를 만들기 전에 기존 파드 및 기타 리소스의 레이블을 다시 지정해야 하는 경우가 있다. 이것은 kubectl label 로 수행할 수 있다.
예를 들어, 모든 nginx 파드에 프론트엔드 티어로 레이블을 지정하려면, 다음과 같이 실행한다.
kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
먼저 "app=nginx" 레이블이 있는 모든 파드를 필터링한 다음, "tier=fe" 레이블을 지정한다.
레이블을 지정한 파드를 보려면, 다음을 실행한다.
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
그러면 파드 티어의 추가 레이블 열(-L 또는 --label-columns 로 지정)과 함께, 모든 "app=nginx" 파드가 출력된다.
더 자세한 내용은, 레이블 및 kubectl label을 참고하길 바란다.
어노테이션 업데이트
때로는 어노테이션을 리소스에 첨부하려고 할 수도 있다. 어노테이션은 도구, 라이브러리 등과 같은 API 클라이언트가 검색할 수 있는 임의의 비-식별 메타데이터이다. 이는 kubectl annotate 으로 수행할 수 있다. 예를 들면 다음과 같다.
kubectl annotate pods my-nginx-v4-9gw19 description='my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
더 자세한 내용은, 어노테이션 및 kubectl annotate 문서를 참고하길 바란다.
애플리케이션 스케일링
애플리케이션의 로드가 증가하거나 축소되면, kubectl 을 사용하여 애플리케이션을 스케일링한다. 예를 들어, nginx 레플리카 수를 3에서 1로 줄이려면, 다음을 수행한다.
kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
이제 디플로이먼트가 관리하는 파드가 하나만 있다.
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
시스템이 필요에 따라 1에서 3까지의 범위에서 nginx 레플리카 수를 자동으로 선택하게 하려면, 다음을 수행한다.
kubectl autoscale deployment/my-nginx --min=1 --max=3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
이제 nginx 레플리카가 필요에 따라 자동으로 확장되거나 축소된다.
더 자세한 내용은, kubectl scale, kubectl autoscale 및 horizontal pod autoscaler 문서를 참고하길 바란다.
리소스 인플레이스(in-place) 업데이트
때로는 자신이 만든 리소스를 필요한 부분만, 중단없이 업데이트해야 할 때가 있다.
kubectl apply
구성 파일 셋을 소스 제어에서 유지하는 것이 좋으며
(코드로서의 구성 참조),
그렇게 하면 구성하는 리소스에 대한 코드와 함께 버전을 지정하고 유지할 수 있다.
그런 다음, kubectl apply를 사용하여 구성 변경 사항을 클러스터로 푸시할 수 있다.
이 명령은 푸시하려는 구성의 버전을 이전 버전과 비교하고 지정하지 않은 속성에 대한 자동 변경 사항을 덮어쓰지 않은 채 수정한 변경 사항을 적용한다.
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
참고로 kubectl apply 는 이전의 호출 이후 구성의 변경 사항을 판별하기 위해 리소스에 어노테이션을 첨부한다. 호출되면, kubectl apply 는 리소스를 수정하는 방법을 결정하기 위해, 이전 구성과 제공된 입력 및 리소스의 현재 구성 간에 3-way diff를 수행한다.
현재, 이 어노테이션 없이 리소스가 생성되므로, kubectl apply 의 첫 번째 호출은 제공된 입력과 리소스의 현재 구성 사이의 2-way diff로 대체된다. 이 첫 번째 호출 중에는, 리소스를 생성할 때 설정된 특성의 삭제를 감지할 수 없다. 이러한 이유로, 그 특성들을 삭제하지 않는다.
kubectl apply 에 대한 모든 후속 호출, 그리고 kubectl replace 및 kubectl edit 와 같이 구성을 수정하는 다른 명령은, 어노테이션을 업데이트하여, kubectl apply 에 대한 후속 호출이 3-way diff를 사용하여 삭제를 감지하고 수행할 수 있도록 한다.
kubectl edit
또는, kubectl edit로 리소스를 업데이트할 수도 있다.
kubectl edit deployment/my-nginx
이것은 먼저 리소스를 get 하여, 텍스트 편집기에서 편집한 다음, 업데이트된 버전으로 리소스를 apply 하는 것과 같다.
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# 편집한 다음, 파일을 저장한다.
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
이를 통해 보다 중요한 변경을 더 쉽게 수행할 수 있다. 참고로 EDITOR 또는 KUBE_EDITOR 환경 변수를 사용하여 편집기를 지정할 수 있다.
더 자세한 내용은, kubectl edit 문서를 참고하길 바란다.
kubectl patch
kubectl patch 를 사용하여 API 오브젝트를 인플레이스 업데이트할 수 있다. 이 명령은 JSON 패치,
JSON 병합 패치 그리고 전략적 병합 패치를 지원한다.
kubectl patch를 사용한 인플레이스 API 오브젝트 업데이트와
kubectl patch를
참조한다.
파괴적(disruptive) 업데이트
경우에 따라, 한 번 초기화하면 업데이트할 수 없는 리소스 필드를 업데이트해야 하거나, 디플로이먼트에서 생성된 손상된 파드를 고치는 등의 재귀적 변경을 즉시 원할 수도 있다. 이러한 필드를 변경하려면, replace --force 를 사용하여 리소스를 삭제하고 다시 만든다. 이 경우, 원래 구성 파일을 수정할 수 있다.
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
서비스 중단없이 애플리케이션 업데이트
언젠가는, 위의 카나리 디플로이먼트 시나리오에서와 같이, 일반적으로 새 이미지 또는 이미지 태그를 지정하여, 배포된 애플리케이션을 업데이트해야 한다. kubectl 은 여러 가지 업데이트 작업을 지원하며, 각 업데이트 작업은 서로 다른 시나리오에 적용할 수 있다.
디플로이먼트를 사용하여 애플리케이션을 생성하고 업데이트하는 방법을 안내한다.
nginx 1.14.2 버전을 실행한다고 가정해 보겠다.
kubectl create deployment my-nginx --image=nginx:1.14.2
deployment.apps/my-nginx created
3개의 레플리카를 포함한다(이전과 새 개정판이 공존할 수 있음).
kubectl scale deployment my-nginx --current-replicas=1 --replicas=3
deployment.apps/my-nginx scaled
1.16.1 버전으로 업데이트하려면, 위에서 배운 kubectl 명령을 사용하여 .spec.template.spec.containers[0].image 를 nginx:1.14.2 에서 nginx:1.16.1 로 변경한다.
kubectl edit deployment/my-nginx
이것으로 끝이다! 디플로이먼트는 배포된 nginx 애플리케이션을 배후에서 점차적으로 업데이트한다. 업데이트되는 동안 특정 수의 이전 레플리카만 중단될 수 있으며, 원하는 수의 파드 위에 특정 수의 새 레플리카만 생성될 수 있다. 이에 대한 더 자세한 내용을 보려면, 디플로이먼트 페이지를 방문한다.
다음 내용
3 - 클러스터 네트워킹
네트워킹은 쿠버네티스의 중심적인 부분이지만, 어떻게 작동하는지 정확하게
이해하기가 어려울 수 있다. 쿠버네티스에는 4가지 대응해야 할 네트워킹
문제가 있다.
- 고도로 결합된 컨테이너 간의 통신: 이 문제는
파드와
localhost 통신으로 해결된다. - 파드 간 통신: 이 문제가 이 문서의 주요 초점이다.
- 파드와 서비스 간 통신: 이 문제는 서비스에서 다룬다.
- 외부와 서비스 간 통신: 이 문제도 서비스에서 다룬다.
쿠버네티스는 애플리케이션 간에 머신을 공유하는 것이다. 일반적으로,
머신을 공유하려면 두 애플리케이션이 동일한 포트를 사용하지 않도록
해야 한다. 여러 개발자 간에 포트를 조정하는 것은 대규모로 실시하기가 매우 어렵고,
사용자가 통제할 수 없는 클러스터 수준의 문제에 노출된다.
동적 포트 할당은 시스템에 많은 복잡성을 야기한다. 모든
애플리케이션은 포트를 플래그로 가져와야 하며, API 서버는 동적 포트 번호를
구성 블록에 삽입하는 방법을 알아야 하고, 서비스는 서로를
찾는 방법 등을 알아야 한다. 쿠버네티스는 이런 것들을 다루는 대신
다른 접근법을 취한다.
쿠버네티스 네트워킹 모델에 대한 상세 정보는 여기를 참고한다.
쿠버네티스 네트워크 모델의 구현 방법
네트워크 모델은 각 노드의 컨테이너 런타임에 의해 구현된다. 가장 일반적인 컨테이너 런타임은 컨테이너 네트워크 인터페이스(CNI) 플러그인을 사용하여 네트워크 및 보안 기능을 관리한다. 여러 공급 업체의 다양한 CNI 플러그인이 존재하며, 이들 중 일부는 네트워크 인터페이스를 추가 및 제거하는 기본 기능만 제공하는 반면, 다른 일부는 다른 컨테이너 오케스트레이션 시스템과의 통합, 여러 CNI 플러그인 실행, 고급 IPAM 기능 등과 같은 보다 정교한 솔루션을 제공한다.
쿠버네티스에서 지원하는 네트워킹 애드온의 일부 목록은 이 페이지를 참조한다.
다음 내용
네트워크 모델의 초기 설계와 그 근거 및 미래의 계획은
네트워킹 디자인 문서에
자세히 설명되어 있다.
4 - 로깅 아키텍처
애플리케이션 로그는 애플리케이션 내부에서 발생하는 상황을 이해하는 데 도움이 된다.
로그는 문제를 디버깅하고 클러스터 활동을 모니터링하는 데 특히 유용하다.
대부분의 최신 애플리케이션에는 일종의 로깅 메커니즘이 있다.
마찬가지로, 컨테이너 엔진들도 로깅을 지원하도록 설계되었다.
컨테이너화된 애플리케이션에 가장 쉽고 가장 널리 사용되는 로깅 방법은 표준 출력과 표준 에러 스트림에 작성하는 것이다.
그러나, 일반적으로 컨테이너 엔진이나 런타임에서 제공하는 기본 기능은
완전한 로깅 솔루션으로 충분하지 않다.
예를 들어, 컨테이너가 크래시되거나, 파드가 축출되거나, 노드가 종료된 경우에
애플리케이션의 로그에 접근하고 싶을 것이다.
클러스터에서 로그는 노드, 파드 또는 컨테이너와는 독립적으로
별도의 스토리지와 라이프사이클을 가져야 한다.
이 개념을 클러스터-레벨 로깅이라고 한다.
클러스터-레벨 로깅은 로그를 저장, 분석, 쿼리하기 위해서는 별도의 백엔드가 필요하다.
쿠버네티스가 로그 데이터를 위한 네이티브 스토리지 솔루션을 제공하지는 않지만,
쿠버네티스에 통합될 수 있는 기존의 로깅 솔루션이 많이 있다.
아래 내용은 로그를 어떻게 처리하고 관리하는지 설명한다.
파드와 컨테이너 로그
쿠버네티스는 실행중인 파드의 컨테이너에서 출력하는 로그를 감시한다.
아래 예시는, 초당 한 번씩 표준 출력에 텍스트를 기록하는
컨테이너를 포함하는 파드 매니페스트를 사용한다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
이 파드를 실행하려면, 다음의 명령을 사용한다.
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
출력은 다음과 같다.
로그를 가져오려면, 다음과 같이 kubectl logs 명령을 사용한다.
출력은 다음과 같다.
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
kubectl logs --previous 를 사용해서 컨테이너의 이전 인스턴스에 대한 로그를 검색할 수 있다.
파드에 여러 컨테이너가 있는 경우,
다음과 같이 명령에 -c 플래그와 컨테이너 이름을 추가하여 접근하려는 컨테이너 로그를 지정해야 한다.
kubectl logs counter -c count
자세한 내용은 kubectl logs 문서를 참조한다.
노드가 컨테이너 로그를 처리하는 방법
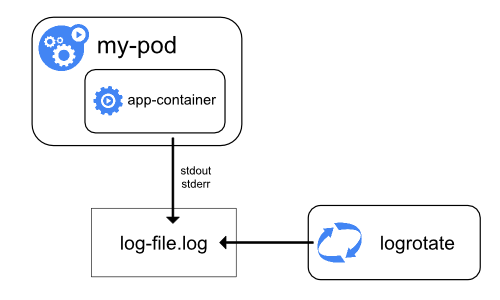
컨테이너화된 애플리케이션의 stdout(표준 출력) 및 stderr(표준 에러) 스트림에 의해 생성된 모든 출력은 컨테이너 런타임이 처리하고 리디렉션 시킨다.
다양한 컨테이너 런타임들은 이를 각자 다른 방법으로 구현하였지만,
kubelet과의 호환성은 CRI 로깅 포맷 으로 표준화되어 있다.
기본적으로 컨테이너가 재시작하는 경우, kubelet은 종료된 컨테이너 하나를 로그와 함께 유지한다.
파드가 노드에서 축출되면, 해당하는 모든 컨테이너와 로그가 함께 축출된다.
kubelet은 쿠버네티스의 특정 API를 통해 사용자들에게 로그를 공개하며,
일반적으로 kubectl logs를 통해 접근할 수 있다.
로그 로테이션
기능 상태:
Kubernetes v1.21 [stable]
kubelet이 로그를 자동으로 로테이트하도록 설정할 수 있다.
로테이션을 구성해놓으면, kubelet은 컨테이너 로그를 로테이트하고 로깅 경로 구조를 관리한다.
kubelet은 이 정보를 컨테이너 런타임에 전송하고(CRI를 사용),
런타임은 지정된 위치에 컨테이너 로그를 기록한다.
kubelet 설정 파일을 사용하여
두 개의 kubelet 파라미터
containerLogMaxSize 및 containerLogMaxFiles를 설정 가능하다.
이러한 설정을 통해 각 로그 파일의 최대 크기와 각 컨테이너에 허용되는 최대 파일 수를 각각 구성할 수 있다.
기본 로깅 예제에서와 같이 kubectl logs를
실행하면, 노드의 kubelet이 요청을 처리하고 로그 파일에서 직접 읽는다.
kubelet은 로그 파일의 내용을 반환한다.
참고:
kubectl logs를 통해서는
최신 로그만 확인할 수 있다.
예를 들어, 파드가 40MiB 크기의 로그를 기록했고 kubelet이 10MiB 마다 로그를 로테이트하는 경우
kubectl logs는 최근의 10MiB 데이터만 반환한다.
시스템 컴포넌트 로그
시스템 컴포넌트에는 두 가지 유형이 있는데, 컨테이너에서 실행되는 것과 실행 중인 컨테이너와 관련된 것이다.
예를 들면 다음과 같다.
- kubelet과 컨테이너 런타임은 컨테이너에서 실행되지 않는다.
kubelet이 컨테이너(파드와 그룹화된)를 실행시킨다.
- 쿠버네티스의 스케줄러, 컨트롤러 매니저, API 서버는
파드(일반적으로 스태틱 파드)로 실행된다.
etcd는 컨트롤 플레인에서 실행되며, 대부분의 경우 역시 스태틱 파드로써 실행된다.
클러스터가 kube-proxy를 사용하는 경우는
데몬셋(DaemonSet)으로써 실행된다.
로그의 위치
kubelet과 컨테이너 런타임이 로그를 기록하는 방법은,
노드의 운영체제에 따라 다르다.
systemd를 사용하는 시스템에서는 kubelet과 컨테이너 런타임은 기본적으로 로그를 journald에 작성한다.
journalctl을 사용하여 이를 확인할 수 있다.
예를 들어 journalctl -u kubelet.
systemd를 사용하지 않는 시스템에서, kubelet과 컨테이너 런타임은 로그를 /var/log 디렉터리의 .log 파일에 작성한다.
다른 경로에 로그를 기록하고 싶은 경우에는, kube-log-runner를 통해
간접적으로 kubelet을 실행하여
kubelet의 로그를 지정한 디렉토리로 리디렉션할 수 있다.
kubelet을 실행할 때 --log-dir 인자를 통해 로그가 저장될 디렉토리를 지정할 수 있다.
그러나 해당 인자는 더 이상 지원되지 않으며(deprecated), kubelet은 항상 컨테이너 런타임으로 하여금
/var/log/pods 아래에 로그를 기록하도록 지시한다.
kube-log-runner에 대한 자세한 정보는 시스템 로그를 확인한다.
kubelet은 기본적으로 C:\var\logs 아래에 로그를 기록한다
(C:\var\log가 아님에 주의한다).
C:\var\log 경로가 쿠버네티스에 설정된 기본값이지만,
몇몇 클러스터 배포 도구들은 윈도우 노드의 로그 경로로 C:\var\log\kubelet를 사용하기도 한다.
다른 경로에 로그를 기록하고 싶은 경우에는, kube-log-runner를 통해
간접적으로 kubelet을 실행하여
kubelet의 로그를 지정한 디렉토리로 리디렉션할 수 있다.
그러나, kubelet은 항상 컨테이너 런타임으로 하여금
C:\var\log\pods 아래에 로그를 기록하도록 지시한다.
kube-log-runner에 대한 자세한 정보는 시스템 로그를 확인한다.
파드로 실행되는 쿠버네티스 컴포넌트의 경우,
기본 로깅 메커니즘을 따르지 않고 /var/log 아래에 로그를 기록한다
(즉, 해당 컴포넌트들은 systemd의 journal에 로그를 기록하지 않는다).
쿠버네티스의 저장 메커니즘을 사용하여, 컴포넌트를 실행하는 컨테이너에 영구적으로 사용 가능한 저장 공간을 연결할 수 있다.
etcd와 etcd의 로그를 기록하는 방식에 대한 자세한 정보는 etcd 공식 문서를 확인한다.
다시 언급하자면, 쿠버네티스의 저장 메커니즘을 사용하여
컴포넌트를 실행하는 컨테이너에 영구적으로 사용 가능한 저장 공간을 연결할 수 있다.
참고:
스케줄러와 같은 쿠버네티스 클러스터의 컴포넌트를 배포하여 상위 노드에서 공유된 볼륨에 로그를 기록하는 경우,
해당 로그들이 로테이트되는지 확인하고 관리해야 한다.
쿠버네티스는 로그 로테이션을 관리하지 않는다.
몇몇 로그 로테이션은 운영체제가 자동적으로 구현할 수도 있다.
예를 들어, 컴포넌트를 실행하는 스태틱 파드에 /var/log 디렉토리를 공유하여 로그를 기록하면,
노드-레벨 로그 로테이션은 해당 경로의 파일을
쿠버네티스 외부의 다른 컴포넌트들이 기록한 파일과 동일하게 취급한다.
몇몇 배포 도구들은 로그 로테이션을 자동화하지만,
나머지 도구들은 이를 사용자의 책임으로 둔다.
클러스터-레벨 로깅 아키텍처
쿠버네티스는 클러스터-레벨 로깅을 위한 네이티브 솔루션을 제공하지 않지만, 고려해야 할 몇 가지 일반적인 접근 방법을 고려할 수 있다. 여기 몇 가지 옵션이 있다.
- 모든 노드에서 실행되는 노드-레벨 로깅 에이전트를 사용한다.
- 애플리케이션 파드에 로깅을 위한 전용 사이드카 컨테이너를 포함한다.
- 애플리케이션 내에서 로그를 백엔드로 직접 푸시한다.
노드 로깅 에이전트 사용
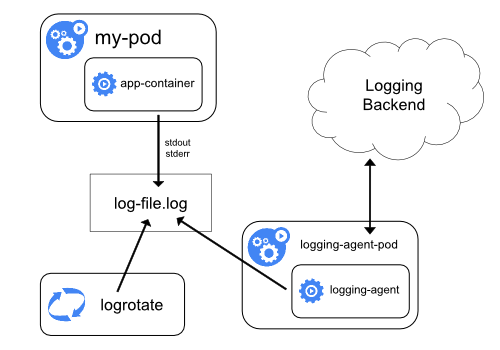
각 노드에 노드-레벨 로깅 에이전트 를 포함시켜 클러스터-레벨 로깅을 구현할 수 있다. 로깅 에이전트는 로그를 노출하거나 로그를 백엔드로 푸시하는 전용 도구이다. 일반적으로, 로깅 에이전트는 해당 노드의 모든 애플리케이션 컨테이너에서 로그 파일이 있는 디렉터리에 접근할 수 있는 컨테이너이다.
로깅 에이전트는 모든 노드에서 실행되어야 하므로, 에이전트를
DaemonSet 으로 동작시키는 것을 추천한다.
노드-레벨 로깅은 노드별 하나의 에이전트만 생성하며, 노드에서 실행되는 애플리케이션에 대한 변경은 필요로 하지 않는다.
컨테이너는 로그를 stdout과 stderr로 출력하며, 합의된 형식은 없다. 노드-레벨 에이전트는 이러한 로그를 수집하고 취합을 위해 전달한다.
로깅 에이전트와 함께 사이드카 컨테이너 사용
다음 중 한 가지 방법으로 사이드카 컨테이너를 사용할 수 있다.
- 사이드카 컨테이너는 애플리케이션 로그를 자체
stdout 으로 스트리밍한다. - 사이드카 컨테이너는 로깅 에이전트를 실행하며, 애플리케이션 컨테이너에서 로그를 가져오도록 구성된다.
사이드카 컨테이너 스트리밍
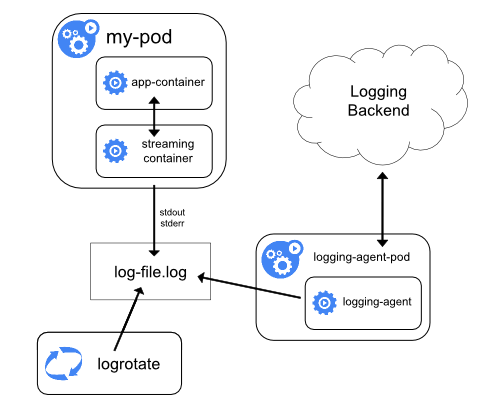
사이드카 컨테이너가 자체 stdout 및 stderr 스트림으로
기록하도록 하면, 각 노드에서 이미 실행 중인 kubelet과 로깅 에이전트를
활용할 수 있다. 사이드카 컨테이너는 파일, 소켓 또는 journald에서 로그를 읽는다.
각 사이드카 컨테이너는 자체 stdout 또는 stderr 스트림에 로그를 출력한다.
이 방법을 사용하면 애플리케이션의 다른 부분에서 여러 로그 스트림을
분리할 수 있고, 이 중 일부는 stdout 또는 stderr 에
작성하기 위한 지원이 부족할 수 있다. 로그를 리디렉션하는 로직은
최소화되어 있기 때문에, 심각한 오버헤드가 아니다. 또한,
stdout 및 stderr 가 kubelet에서 처리되므로, kubectl logs 와 같은
빌트인 도구를 사용할 수 있다.
예를 들어, 파드는 단일 컨테이너를 실행하고, 컨테이너는
서로 다른 두 가지 형식을 사용하여 서로 다른 두 개의 로그 파일에 기록한다.
다음은 파드에 대한 매니페스트이다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
두 컴포넌트를 컨테이너의 stdout 스트림으로 리디렉션한 경우에도, 동일한 로그
스트림에 서로 다른 형식의 로그 항목을 작성하는 것은
추천하지 않는다. 대신, 두 개의 사이드카 컨테이너를 생성할 수 있다. 각 사이드카
컨테이너는 공유 볼륨에서 특정 로그 파일을 테일(tail)한 다음 로그를
자체 stdout 스트림으로 리디렉션할 수 있다.
다음은 사이드카 컨테이너가 두 개인 파드에 대한 매니페스트이다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
이제 이 파드를 실행하면, 다음의 명령을 실행하여 각 로그 스트림에
개별적으로 접근할 수 있다.
kubectl logs counter count-log-1
출력은 다음과 같다.
0: Fri Apr 1 11:42:26 UTC 2022
1: Fri Apr 1 11:42:27 UTC 2022
2: Fri Apr 1 11:42:28 UTC 2022
...
kubectl logs counter count-log-2
출력은 다음과 같다.
Fri Apr 1 11:42:29 UTC 2022 INFO 0
Fri Apr 1 11:42:30 UTC 2022 INFO 0
Fri Apr 1 11:42:31 UTC 2022 INFO 0
...
클러스터에 노드-레벨 에이전트를 설치했다면, 에이전트는 추가적인 설정 없이도
자동으로 해당 로그 스트림을 선택한다. 원한다면, 소스 컨테이너에
따라 로그 라인을 파싱(parse)하도록 에이전트를 구성할 수도 있다.
CPU 및 메모리 사용량이 낮은(몇 밀리코어 수준의 CPU와 몇 메가바이트 수준의 메모리 요청) 파드라고 할지라도,
로그를 파일에 기록한 다음 stdout 으로 스트리밍하는 것은
노드가 필요로 하는 스토리지 양을 두 배로 늘릴 수 있다.
단일 파일에 로그를 기록하는 애플리케이션이 있는 경우,
일반적으로 스트리밍 사이드카 컨테이너 방식을 구현하는 대신
/dev/stdout 을 대상으로 설정하는 것을 추천한다.
사이드카 컨테이너를 사용하여
애플리케이션 자체에서 로테이션할 수 없는 로그 파일을 로테이션할 수도 있다.
이 방법의 예시는 정기적으로 logrotate 를 실행하는 작은 컨테이너를 두는 것이다.
그러나, stdout 및 stderr 을 직접 사용하고 로테이션과
유지 정책을 kubelet에 두는 것이 더욱 직관적이다.
로깅 에이전트가 있는 사이드카 컨테이너
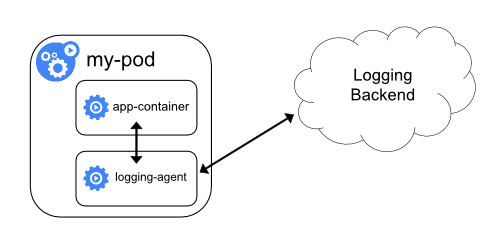
노드-레벨 로깅 에이전트가 상황에 맞게 충분히 유연하지 않은 경우,
애플리케이션과 함께 실행하도록 특별히 구성된 별도의 로깅 에이전트를 사용하여
사이드카 컨테이너를 생성할 수 있다.
참고:
사이드카 컨테이너에서 로깅 에이전트를 사용하면
상당한 리소스 소비로 이어질 수 있다. 게다가, kubelet에 의해
제어되지 않기 때문에, kubectl logs 를 사용하여 해당 로그에
접근할 수 없다.아래는 로깅 에이전트가 포함된 사이드카 컨테이너를 구현하는 데 사용할 수 있는 두 가지 매니페스트이다.
첫 번째 매니페스트는 fluentd를 구성하는
컨피그맵(ConfigMap)이 포함되어 있다.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
참고:
예제 매니페스트에서, 꼭 fluentd가 아니더라도,
애플리케이션 컨테이너 내의 모든 소스에서 로그를 읽어올 수 있는 다른 로깅 에이전트를 사용할 수 있다.두 번째 매니페스트는 fluentd가 실행되는 사이드카 컨테이너가 있는 파드를 설명한다.
파드는 fluentd가 구성 데이터를 가져올 수 있는 볼륨을 마운트한다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
애플리케이션에서 직접 로그 노출
애플리케이션에서 직접 로그를 노출하거나 푸시하는 클러스터-로깅은 쿠버네티스의 범위를 벗어난다.
다음 내용
5 - 쿠버네티스 시스템 컴포넌트에 대한 메트릭
시스템 컴포넌트 메트릭으로 내부에서 발생하는 상황을 더 잘 파악할 수 있다. 메트릭은
대시보드와 경고를 만드는 데 특히 유용하다.
쿠버네티스 컴포넌트의 메트릭은 프로메테우스 형식으로 출력된다.
이 형식은 구조화된 평문으로 디자인되어 있으므로 사람과 기계 모두가 쉽게 읽을 수 있다.
쿠버네티스의 메트릭
대부분의 경우 메트릭은 HTTP 서버의 /metrics 엔드포인트에서 사용할 수 있다.
기본적으로 엔드포인트를 노출하지 않는 컴포넌트의 경우 --bind-address 플래그를 사용하여 활성화할 수 있다.
해당 컴포넌트의 예는 다음과 같다.
프로덕션 환경에서는 이러한 메트릭을 주기적으로 수집하고
시계열 데이터베이스에서 사용할 수 있도록 프로메테우스 서버 또는
다른 메트릭 수집기(scraper)를 구성할 수 있다.
참고로 kubelet도
/metrics/cadvisor, /metrics/resource 그리고 /metrics/probes 엔드포인트에서 메트릭을 노출한다.
이러한 메트릭은 동일한 라이프사이클을 가지지 않는다.
클러스터가 RBAC을 사용하는 경우, 메트릭을 읽으려면
/metrics 에 접근을 허용하는 클러스터롤(ClusterRole)을 가지는 사용자, 그룹 또는 서비스어카운트(ServiceAccount)를 통한 권한이 필요하다.
예를 들면, 다음과 같다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- nonResourceURLs:
- "/metrics"
verbs:
- get
메트릭 라이프사이클
알파(Alpha) 메트릭 → 안정적인(Stable) 메트릭 → 사용 중단된(Deprecated) 메트릭 → 히든(Hidden) 메트릭 → 삭제된(Deleted) 메트릭
알파 메트릭은 안정성을 보장하지 않는다. 따라서 언제든지 수정되거나 삭제될 수 있다.
안정적인 메트릭은 변경되지 않는다는 것을 보장한다. 이것은 다음을 의미한다.
- 사용 중단 표기가 없는 안정적인 메트릭은, 이름이 변경되거나 삭제되지 않는다.
- 안정적인 메트릭의 유형(type)은 수정되지 않는다.
사용 중단된 메트릭은 해당 메트릭이 결국 삭제된다는 것을 나타내지만, 아직은 사용 가능하다는 뜻이다.
이 메트릭은 어느 버전에서부터 사용 중단된 것인지를 표시하는 어노테이션을 포함한다.
예를 들면,
# HELP some_counter this counts things
# TYPE some_counter counter
some_counter 0
# HELP some_counter (Deprecated since 1.15.0) this counts things
# TYPE some_counter counter
some_counter 0
히든 메트릭은 깔끔함(scraping)을 위해 더 이상 게시되지는 않지만, 여전히 사용은 가능하다.
히든 메트릭을 사용하려면, 히든 메트릭 표시 섹션을 참고한다.
삭제된 메트릭은 더 이상 게시되거나 사용할 수 없다.
히든 메트릭 표시
위에서 설명한 것처럼, 관리자는 특정 바이너리의 커맨드 라인 플래그를 통해 히든 메트릭을 활성화할 수 있다.
관리자가 지난 릴리스에서 사용 중단된 메트릭의 마이그레이션을 놓친 경우
관리자를 위한 임시방편으로 사용된다.
show-hidden-metrics-for-version 플래그는 해당 릴리스에서 사용 중단된 메트릭을 보여주려는
버전을 사용한다. 버전은 xy로 표시되며, 여기서 x는 메이저(major) 버전이고,
y는 마이너(minor) 버전이다. 패치 릴리스에서 메트릭이 사용 중단될 수 있지만, 패치 버전은 필요하지 않다.
그 이유는 메트릭 사용 중단 정책이 마이너 릴리스에 대해 실행되기 때문이다.
플래그는 그 값으로 이전의 마이너 버전만 사용할 수 있다. 관리자가 이전 버전을
show-hidden-metrics-for-version 에 설정하면 이전 버전의 모든 히든 메트릭이 생성된다.
사용 중단 메트릭 정책을 위반하기 때문에 너무 오래된 버전은 허용되지 않는다.
1.n 버전에서 사용 중단되었다고 가정한 메트릭 A 를 예로 들어보겠다.
메트릭 사용 중단 정책에 따르면, 다음과 같은 결론에 도달할 수 있다.
1.n 릴리스에서는 메트릭이 사용 중단되었으며, 기본적으로 생성될 수 있다.1.n+1 릴리스에서는 기본적으로 메트릭이 숨겨져 있으며,
show-hidden-metrics-for-version=1.n 커맨드 라인에 의해서 생성될 수 있다.1.n+2 릴리스에서는 코드베이스에서 메트릭이 제거되어야 한다. 더이상 임시방편은 존재하지 않는다.
릴리스 1.12 에서 1.13 으로 업그레이드 중이지만, 1.12 에서 사용 중단된 메트릭 A 를 사용하고 있다면,
커맨드 라인에서 --show-hidden-metrics=1.12 플래그로 히든 메트릭을 설정해야 하고,
1.14 로 업그레이드하기 전에 이 메트릭을 사용하지 않도록 의존성을 제거하는 것을 기억해야 한다.
액셀러레이터 메트릭 비활성화
kubelet은 cAdvisor를 통해 액셀러레이터 메트릭을 수집한다. 이러한 메트릭을 수집하기 위해,
NVIDIA GPU와 같은 액셀러레이터의 경우, kubelet은 드라이버에 열린 핸들을 가진다.
이는 인프라 변경(예: 드라이버 업데이트)을 수행하기 위해,
클러스터 관리자가 kubelet 에이전트를 중지해야 함을 의미한다.
액셀러레이터 메트릭을 수집하는 책임은 이제 kubelet이 아닌 공급 업체에 있다.
공급 업체는 메트릭을 수집하여 메트릭 서비스(예: 프로메테우스)에 노출할
컨테이너를 제공해야 한다.
DisableAcceleratorUsageMetrics 기능 게이트는
이 기능을 기본적으로 사용하도록 설정하는 타임라인를
사용하여 kubelet에서 수집한 메트릭을 비활성화한다.
컴포넌트 메트릭
kube-controller-manager 메트릭
컨트롤러 관리자 메트릭은 컨트롤러 관리자의 성능과 상태에 대한 중요한 인사이트를 제공한다.
이러한 메트릭에는 go_routine 수와 같은 일반적인 Go 언어 런타임 메트릭과
etcd 요청 대기 시간 또는 Cloudprovider(AWS, GCE, OpenStack) API 대기 시간과 같은 컨트롤러 특정 메트릭이 포함되어
클러스터의 상태를 측정하는 데 사용할 수 있다.
쿠버네티스 1.7부터 GCE, AWS, Vsphere 및 OpenStack의 스토리지 운영에 대한
상세한 Cloudprovider 메트릭을 사용할 수 있다.
이 메트릭은 퍼시스턴트 볼륨 동작의 상태를 모니터링하는 데 사용할 수 있다.
예를 들어, GCE의 경우 이러한 메트릭을 다음과 같이 호출한다.
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
kube-scheduler 메트릭
기능 상태:
Kubernetes v1.21 [beta]
스케줄러는 실행 중인 모든 파드의 요청(request)된 리소스와 요구되는 제한(limit)을 보고하는 선택적 메트릭을 노출한다.
이러한 메트릭은 용량 계획(capacity planning) 대시보드를 구축하고,
현재 또는 과거 스케줄링 제한을 평가하고, 리소스 부족으로 스케줄할 수 없는 워크로드를 빠르게 식별하고,
실제 사용량을 파드의 요청과 비교하는 데 사용할 수 있다.
kube-scheduler는 각 파드에 대해 구성된 리소스 요청과 제한을 식별한다.
요청 또는 제한이 0이 아닌 경우 kube-scheduler는 메트릭 시계열을 보고한다.
시계열에는 다음과 같은 레이블이 지정된다.
- 네임스페이스
- 파드 이름
- 파드가 스케줄된 노드 또는 아직 스케줄되지 않은 경우 빈 문자열
- 우선순위
- 해당 파드에 할당된 스케줄러
- 리소스 이름 (예:
cpu) - 알려진 경우 리소스 단위 (예:
cores)
파드가 완료되면 (Never 또는 OnFailure의 restartPolicy가 있고
Succeeded 또는 Failed 파드 단계에 있거나, 삭제되고 모든 컨테이너가 종료된 상태에 있음)
스케줄러가 이제 다른 파드를 실행하도록 스케줄할 수 있으므로 시리즈가 더 이상 보고되지 않는다.
두 메트릭을 kube_pod_resource_request 및 kube_pod_resource_limit 라고 한다.
메트릭은 HTTP 엔드포인트 /metrics/resources에 노출되며
스케줄러의 /metrics 엔드포인트와 동일한 인증이 필요하다.
이러한 알파 수준의 메트릭을 노출시키려면 --show-hidden-metrics-for-version=1.20 플래그를 사용해야 한다.
메트릭 비활성화
커맨드 라인 플래그 --disabled-metrics 를 통해 메트릭을 명시적으로 끌 수 있다.
이 방법이 필요한 이유는 메트릭이 성능 문제를 일으키는 경우을 예로 들 수 있다.
입력값은 비활성화되는 메트릭 목록이다(예: --disabled-metrics=metric1,metric2).
메트릭 카디널리티(cardinality) 적용
제한되지 않은 차원의 메트릭은 계측하는 컴포넌트에서 메모리 문제를 일으킬 수 있다.
리소스 사용을 제한하려면, --allow-label-value 커맨드 라인 옵션을 사용하여
메트릭 항목에 대한 레이블 값의 허용 목록(allow-list)을 동적으로 구성한다.
알파 단계에서, 플래그는 메트릭 레이블 허용 목록으로 일련의 매핑만 가져올 수 있다.
각 매핑은 <metric_name>,<label_name>=<allowed_labels> 형식이다. 여기서
<allowed_labels> 는 허용되는 레이블 이름의 쉼표로 구분된 목록이다.
전체 형식은 다음과 같다.
--allow-label-value <metric_name>,<label_name>='<allow_value1>, <allow_value2>...', <metric_name2>,<label_name>='<allow_value1>, <allow_value2>...', ...
예시는 다음과 같다.
--allow-label-value number_count_metric,odd_number='1,3,5', number_count_metric,even_number='2,4,6', date_gauge_metric,weekend='Saturday,Sunday'
다음 내용
6 - 시스템 로그
시스템 컴포넌트 로그는 클러스터에서 발생하는 이벤트를 기록하며, 이는 디버깅에 아주 유용하다.
더 많거나 적은 세부 정보를 표시하도록 다양하게 로그를 설정할 수 있다.
로그는 컴포넌트 내에서 오류를 표시하는 것 처럼 간단하거나,
이벤트의 단계적 추적(예: HTTP 엑세스 로그, 파드의 상태 변경, 컨트롤러 작업 또는 스케줄러의 결정)을
표시하는 것처럼 세밀할 수 있다.
Klog
klog는 쿠버네티스의 로깅 라이브러리다. klog는
쿠버네티스 시스템 컴포넌트의 로그 메시지를 생성한다.
klog 설정에 대한 더 많은 정보는, 커맨드라인 툴을 참고한다.
쿠버네티스는 각 컴포넌트의 로깅을 간소화하는 중에 있다.
다음 klog 명령줄 플래그는 쿠버네티스 1.23에서
사용 중단되었으며
이후 릴리스에서 제거될 것이다.
--add-dir-header--alsologtostderr--log-backtrace-at--log-dir--log-file--log-file-max-size--logtostderr--one-output--skip-headers--skip-log-headers--stderrthreshold
출력은 출력 형식에 관계없이 항상 표준 에러(stderr)에 기록될 것이다. 출력 리다이렉션은
쿠버네티스 컴포넌트를 호출하는 컴포넌트가 담당할 것으로 기대된다. 이는 POSIX
셸 또는 systemd와 같은 도구일 수 있다.
배포판과 무관한(distroless) 컨테이너 또는 윈도우 시스템 서비스와 같은 몇몇 경우에서, 위의 옵션은
사용할 수 없다. 그런 경우
출력을 리다이렉트하기 위해
kube-log-runner
바이너리를 쿠버네티스 컴포넌트의 래퍼(wrapper)로 사용할 수 있다.
미리 빌드된 바이너리가 몇몇 쿠버네티스 베이스 이미지에 기본 이름 /go-runner 와
서버 및 노드 릴리스 아카이브에는 kube-log-runner라는 이름으로 포함되어 있다.
다음 표는 각 kube-log-runner 실행법이 어떤 셸 리다이렉션에 해당되는지 보여준다.
| 사용법 | POSIX 셸 (예:) bash) | kube-log-runner <options> <cmd> |
|---|
| stderr와 stdout을 합치고, stdout으로 출력 | 2>&1 | kube-log-runner (기본 동작)) |
| stderr와 stdout을 로그 파일에 기록 | 1>>/tmp/log 2>&1 | kube-log-runner -log-file=/tmp/log |
| 로그 파일에 기록하면서 stdout으로 출력 | 2>&1 | tee -a /tmp/log | kube-log-runner -log-file=/tmp/log -also-stdout |
| stdout만 로그 파일에 기록 | >/tmp/log | kube-log-runner -log-file=/tmp/log -redirect-stderr=false |
Klog 출력
klog 네이티브 형식 예 :
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
메시지 문자열은 줄바꿈을 포함하고 있을 수도 있다.
I1025 00:15:15.525108 1 example.go:79] This is a message
which has a line break.
구조화된 로깅
기능 상태:
Kubernetes v1.23 [beta]
경고:
구조화된 로그메시지로 마이그레이션은 진행중인 작업이다. 이 버전에서는 모든 로그 메시지가 구조화되지 않는다.
로그 파일을 파싱할 때, 구조화되지 않은 로그 메시지도 처리해야 한다.
로그 형식 및 값 직렬화는 변경될 수 있다.
구조화된 로깅은 로그 메시지에 유니폼 구조를 적용하여
정보를 쉽게 추출하고, 로그를 보다 쉽고 저렴하게 저장하고 처리하는 작업이다.
로그 메세지를 생성하는 코드는 기존의 구조화되지 않은 klog 출력을 사용 또는
구조화된 로깅을 사용할지 여부를 결정합니다.
구조화된 로그 메시지의 기본 형식은 텍스트이며,
기존 klog와 하위 호환되는 형식이다.
<klog header> "<message>" <key1>="<value1>" <key2>="<value2>" ...
예시:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
문자열은 따옴표로 감싸진다. 다른 값들은
%+v로 포맷팅되며, 이로 인해
데이터에 따라 로그 메시지가 다음 줄로 이어질 수 있다.
I1025 00:15:15.525108 1 example.go:116] "Example" data="This is text with a line break\nand \"quotation marks\"." someInt=1 someFloat=0.1 someStruct={StringField: First line,
second line.}
컨텍스츄얼 로깅(Contextual Logging)
기능 상태:
Kubernetes v1.24 [alpha]
컨텍스츄얼 로깅은 구조화된 로깅을 기반으로 한다.
컨텍스츄얼 로깅은 주로 개발자가 로깅 호출을 사용하는 방법에 관한 것이다.
해당 개념을 기반으로 하는 코드는 좀 더 유연하며,
컨텍스츄얼 로깅 KEP에 기술된 추가적인 사용 사례를 지원한다.
개발자가 자신의 구성 요소에서
WithValues 또는 WithName과 같은 추가 기능을 사용하는 경우,
로그 항목에는 호출자가 함수로 전달하는 추가 정보가 포함된다.
현재 이 기능은 StructuredLogging 기능 게이트 뒤에 있으며
기본적으로 비활성화되어 있다.
이 기능을 위한 인프라는 구성 요소를 수정하지 않고 1.24에 추가되었다.
component-base/logs/example
명령은 새 로깅 호출을 사용하는 방법과
컨텍스츄얼 로깅을 지원하는 구성 요소가 어떻게 작동하는지 보여준다.
$ cd $GOPATH/src/k8s.io/kubernetes/staging/src/k8s.io/component-base/logs/example/cmd/
$ go run . --help
...
--feature-gates mapStringBool A set of key=value pairs that describe feature gates for alpha/experimental features. Options are:
AllAlpha=true|false (ALPHA - default=false)
AllBeta=true|false (BETA - default=false)
ContextualLogging=true|false (ALPHA - default=false)
$ go run . --feature-gates ContextualLogging=true
...
I0404 18:00:02.916429 451895 logger.go:94] "example/myname: runtime" foo="bar" duration="1m0s"
I0404 18:00:02.916447 451895 logger.go:95] "example: another runtime" foo="bar" duration="1m0s"
runtime 메시지 및 duration="1m0s" 값을 로깅하는
기존 로깅 함수를 수정하지 않고도,
이 함수의 호출자에 의해 example 접두사 및 foo="bar" 문자열이 로그에 추가되었다.
컨텍스츄얼 로깅이 비활성화되어 있으면, WithValues 및 WithName 은 아무 효과가 없으며,
로그 호출은 전역 klog 로거를 통과한다.
따라서 이 추가 정보는 더 이상 로그 출력에 포함되지 않는다.
$ go run . --feature-gates ContextualLogging=false
...
I0404 18:03:31.171945 452150 logger.go:94] "runtime" duration="1m0s"
I0404 18:03:31.171962 452150 logger.go:95] "another runtime" duration="1m0s"
JSON 로그 형식
기능 상태:
Kubernetes v1.19 [alpha]
경고:
JSON 출력은 많은 표준 klog 플래그를 지원하지 않는다. 지원하지 않는 klog 플래그 목록은,
커맨드라인 툴을 참고한다.
모든 로그가 JSON 형식으로 작성되는 것은 아니다(예: 프로세스 시작 중).
로그를 파싱하려는 경우 JSON 형식이 아닌 로그 행을 처리할 수 있는지 확인해야 한다.
필드 이름과 JSON 직렬화는 변경될 수 있다.
--logging-format=json 플래그는 로그 형식을 klog 기본 형식에서 JSON 형식으로 변경한다.
JSON 로그 형식 예시(보기좋게 출력된 형태)는 다음과 같다.
{
"ts": 1580306777.04728,
"v": 4,
"msg": "Pod status updated",
"pod":{
"name": "nginx-1",
"namespace": "default"
},
"status": "ready"
}
특별한 의미가 있는 키:
ts - Unix 시간의 타임스탬프 (필수, 부동 소수점)v - 자세한 정도 (필수, 정수, 기본 값 0)err - 오류 문자열 (선택 사항, 문자열)msg - 메시지 (필수, 문자열)
현재 JSON 형식을 지원하는 컴포넌트 목록:
로그 상세 레벨(verbosity)
-v 플래그로 로그 상세 레벨(verbosity)을 제어한다. 값을 늘리면 기록된 이벤트 수가 증가한다.
값을 줄이면 기록된 이벤트 수가 줄어든다. 로그 상세 레벨(verbosity)를 높이면
점점 덜 심각한 이벤트가 기록된다. 로그 상세 레벨(verbosity)을 0으로 설정하면 중요한 이벤트만 기록된다.
로그 위치
시스템 컴포넌트에는 컨테이너에서 실행되는 것과 컨테이너에서 실행되지 않는 두 가지 유형이 있다.
예를 들면 다음과 같다.
- 쿠버네티스 스케줄러와 kube-proxy는 컨테이너에서 실행된다.
- kubelet과 컨테이너 런타임은
컨테이너에서 실행되지 않는다.
systemd를 사용하는 시스템에서는, kubelet과 컨테이너 런타임은 jounald에 기록한다.
그 외 시스템에서는, /var/log 디렉터리의 .log 파일에 기록한다.
컨테이너 내부의 시스템 컴포넌트들은 기본 로깅 메커니즘을 무시하고,
항상 /var/log 디렉터리의 .log 파일에 기록한다.
컨테이너 로그와 마찬가지로, /var/log 디렉터리의 시스템 컴포넌트 로그들은 로테이트해야 한다.
kube-up.sh 스크립트로 생성된 쿠버네티스 클러스터에서는, logrotate 도구로 로그가 로테이트되도록 설정된다.
logrotate 도구는 로그가 매일 또는 크기가 100MB 보다 클 때 로테이트된다.
다음 내용
7 - 쿠버네티스 시스템 컴포넌트에 대한 추적(trace)
기능 상태:
Kubernetes v1.22 [alpha]
시스템 컴포넌트 추적은 클러스터 내에서 수행된 동작들 간의 지연(latency)과 관계(relationship)를 기록한다.
쿠버네티스 컴포넌트들은 OpenTelemetry 프로토콜과
gRPC exporter를 이용하여 추적을 생성하고
OpenTelemetry 수집기를
통해 추적 백엔드(tracing backends)로 라우팅되거나 수집될 수 있다.
추적 수집
추적 수집 및 수집기에 대한 전반적인 가이드는
OpenTelemetry 수집기 시작하기에서 제공한다.
그러나, 쿠버네티스 컴포넌트에 관련된 몇 가지 사항에 대해서는 특별히 살펴볼 필요가 있다.
기본적으로, 쿠버네티스 컴포넌트들은 IANA OpenTelemetry 포트인
4317 포트로 OTLP에 대한 grpc exporter를 이용하여 추적를 내보낸다.
예를 들면, 수집기가 쿠버네티스 컴포넌트에 대해 사이드카(sidecar)로 동작한다면,
다음과 같은 리시버 설정을 통해 스팬(span)을 수집하고 그 로그를 표준 출력(standard output)으로 내보낼 것이다.
receivers:
otlp:
protocols:
grpc:
exporters:
# 이 exporter를 사용자의 백엔드를 위한 exporter로 변경
logging:
logLevel: debug
service:
pipelines:
traces:
receivers: [otlp]
exporters: [logging]
컴포넌트 추적
kube-apiserver 추적
kube-apiserver는 들어오는 HTTP 요청들과
webhook, etcd 로 나가는 요청들, 그리고 재진입 요청들에 대해 span을 생성한다.
kube-apiserver는 자주 퍼블릭 엔드포인트로 이용되기 때문에,
들어오는 요청들에 첨부된 추적 컨택스트를 사용하지 않고,
나가는 요청들을 통해 W3C Trace Context를 전파한다.
kube-apiserver 에서의 추적 활성화
추적을 활성화하기 위해서는, kube-apiserve에서 APIServerTracing
기능 게이트를 활성화한다.
또한, kube-apiserver의 추적 설정 파일에
--tracing-config-file=<path-to-config>을 추가한다.
다음은 10000개 요청 당 1개에 대한 span을 기록하는 설정에 대한 예시이고, 이는 기본 OpenTelemetry 엔드포인트를 이용한다.
apiVersion: apiserver.config.k8s.io/v1alpha1
kind: TracingConfiguration
# 기본값
#endpoint: localhost:4317
samplingRatePerMillion: 100
TracingConfiguration 구조체에 대해 더 많은 정보를 얻고 싶다면
API server config API (v1alpha1)를 참고한다.
kubelet 추적
기능 상태:
Kubernetes v1.25 [alpha]
kubelet CRI 인터페이스와 인증된 http 서버는 추적(trace) 스팬(span)을 생성하도록 설정 할수 있다.
apiserver와 마찬가지로 해당 엔드포인트 및 샘플링률을 구성할 수 있다.
추적 컨텍스트 전파(trace context propagation)도 구성할 수 있다. 상위 스팬(span)의 샘플링 설정이 항상 적용된다.
제공되는 설정의 샘플링률은 상위가 없는 스팬(span)에 기본 적용된다.
엔드포인트를 구성하지 않고 추적을 활성화로 설정하면, 기본 OpenTelemetry Collector receiver 주소는 "localhost:4317"으로 기본 설정된다.
kubelet tracing 활성화
추적을 활성화하려면 kubelet에서 KubeletTracing
기능 게이트(feature gate)을 활성화한다.
또한 kubelet에서
tracing configuration을 제공한다.
tracing 구성을 참조한다.
다음은 10000개 요청 중 1개에 대하여 스팬(span)을 기록하고, 기본 OpenTelemetry 앤드포인트를 사용하도록 한 kubelet 구성 예시이다.
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
KubeletTracing: true
tracing:
# 기본값
#endpoint: localhost:4317
samplingRatePerMillion: 100
안정성
추적의 계측화(tracing instrumentation)는 여전히 활발히 개발되는 중이어서 다양한 형태로 변경될 수 있다.
스팬(span)의 이름, 첨부되는 속성, 계측될 엔드포인트(instrumented endpoints)들 등이 그렇다.
이 속성이 안정화(graduates to stable)되기 전까지는
이전 버전과의 호환성은 보장되지 않는다.
다음 내용
8 - 쿠버네티스에서 프락시(Proxy)
이 페이지는 쿠버네티스에서 함께 사용되는 프락시(Proxy)를 설명한다.
프락시
쿠버네티스를 이용할 때에 사용할 수 있는 여러 프락시가 있다.
kubectl proxy:
- 사용자의 데스크탑이나 파드 안에서 실행한다.
- 로컬 호스트 주소에서 쿠버네티스의 API 서버로 프락시한다.
- 클라이언트로 프락시는 HTTP를 사용한다.
- API 서버로 프락시는 HTTPS를 사용한다.
- API 서버를 찾는다.
- 인증 헤더를 추가한다.
apiserver proxy:
- API 서버에 내장된 요새(bastion)이다.
- 클러스터 외부의 사용자가 도달할 수 없는 클러스터 IP 주소로 연결한다.
- API 서버 프로세스에서 실행한다.
- 클라이언트로 프락시는 HTTPS(또는 API서버에서 HTTP로 구성된 경우는 HTTP)를 사용한다.
- 사용 가능한 정보를 이용하여 프락시에 의해 선택한 HTTP나 HTTPS를 사용할 수 있는 대상이다.
- 노드, 파드, 서비스에 도달하는데 사용할 수 있다.
- 서비스에 도달할 때에는 로드 밸런싱을 수행한다.
kube proxy:
- 각 노드에서 실행한다.
- UDP, TCP, SCTP를 이용하여 프락시 한다.
- HTTP는 이해하지 못한다.
- 로드 밸런싱을 제공한다.
- 서비스에 도달하는데만 사용한다.
API 서버 앞단의 프락시/로드밸런서
- 존재 및 구현은 클러스터 마다 다르다. (예: nginx)
- 모든 클라이언트와 하나 이상의 API 서버에 위치한다.
- 여러 API 서버가 있는 경우 로드 밸런서로서 작동한다.
외부 서비스의 클라우드 로드 밸런서
- 일부 클라우드 제공자는 제공한다. (예: AWS ELB, 구글 클라우드 로드 밸런서)
- 쿠버네티스 서비스로
LoadBalancer 유형이 있으면 자동으로 생성된다. - 일반적으로 UDP/TCP만 지원한다.
- SCTP 지원은 클라우드 제공자의 구현에 달려 있다.
- 구현은 클라우드 제공자에 따라 다양하다.
쿠버네티스 사용자는 보통 처음 두 가지 유형 외의 것은 걱정할 필요없다.
클러스터 관리자는 일반적으로 후자의 유형이 올바르게 구성되었는지 확인한다.
요청을 리다이렉트하기
프락시는 리다이렉트 기능을 대체했다. 리다이렉트는 더 이상 사용하지 않는다.
9 - 애드온 설치
참고: 이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는
CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에
콘텐츠 가이드를 읽어본다.
애드온은 쿠버네티스의 기능을 확장한다.
이 페이지는 사용 가능한 일부 애드온과 관련 설치 지침 링크를 나열한다. 이 목차에서 전체를 다루지는 않는다.
네트워킹과 네트워크 폴리시
- ACI는 Cisco ACI로 통합 컨테이너 네트워킹 및 네트워크 보안을 제공한다.
- Antrea는 레이어 3/4에서 작동하여 쿠버네티스를 위한 네트워킹 및 보안 서비스를 제공하며, Open vSwitch를 네트워킹 데이터 플레인으로 활용한다.
- Calico는 네트워킹 및 네트워크 폴리시 제공자이다. Calico는 유연한 네트워킹 옵션을 지원하므로 BGP 유무에 관계없이 비-오버레이 및 오버레이 네트워크를 포함하여 가장 상황에 맞는 옵션을 선택할 수 있다. Calico는 동일한 엔진을 사용하여 서비스 메시 계층(service mesh layer)에서 호스트, 파드 및 (이스티오(istio)와 Envoy를 사용하는 경우) 애플리케이션에 대한 네트워크 폴리시를 적용한다.
- Canal은 Flannel과 Calico를 통합하여 네트워킹 및 네트워크 폴리시를 제공한다.
- Cilium은 네트워킹, 관측 용의성(Observability), 보안 특징을 지닌 eBPF 기반 데이터 플레인을 갖춘 솔루션입니다. Cilium은 기본 라우팅 및 오버레이/캡슐화 모드를 모두 지원하며, 여러 클러스터를 포괄할 수 있는 단순한 플랫(flat) Layer 3 네트워크를 제공합니다. 또한, Cilium은 (네트워크 주소 지정 방식에서 분리된) 신원 기반 보안 모델(identity-based security model)을 사용하여 L3-L7에서 네트워크 정책을 시행할 수 있습니다. Cilium은 kube-proxy를 대체하는 역할을 할 수 있습니다. 또한 부가적으로, 옵트인(opt-in) 형태로 관측 용의성(Observability) 및 보안 기능을 제공합니다.
- CNI-Genie를 사용하면 쿠버네티스는 Calico, Canal, Flannel, Romana 또는 Weave와 같은 CNI 플러그인을 완벽하게 연결할 수 있다.
- Contiv는 다양한 유스케이스와 풍부한 폴리시 프레임워크를 위해 구성 가능한 네트워킹(BGP를 사용하는 네이티브 L3, vxlan을 사용하는 오버레이, 클래식 L2 그리고 Cisco-SDN/ACI)을 제공한다. Contiv 프로젝트는 완전히 오픈소스이다. 인스톨러는 kubeadm을 이용하거나, 그렇지 않은 경우에 대해서도 설치 옵션을 모두 제공한다.
- Contrail은 Tungsten Fabric을 기반으로 하며, 오픈소스이고, 멀티 클라우드 네트워크 가상화 및 폴리시 관리 플랫폼이다. Contrail과 Tungsten Fabric은 쿠버네티스, OpenShift, OpenStack 및 Mesos와 같은 오케스트레이션 시스템과 통합되어 있으며, 가상 머신, 컨테이너/파드 및 베어 메탈 워크로드에 대한 격리 모드를 제공한다.
- Flannel은 쿠버네티스와 함께 사용할 수 있는 오버레이 네트워크 제공자이다.
- Knitter는 쿠버네티스 파드에서 여러 네트워크 인터페이스를 지원하는 플러그인이다.
- Multus는 쿠버네티스의 다중 네트워크 지원을 위한 멀티 플러그인이며, 모든 CNI 플러그인(예: Calico, Cilium, Contiv, Flannel)과 쿠버네티스 상의 SRIOV, DPDK, OVS-DPDK 및 VPP 기반 워크로드를 지원한다.
- OVN-Kubernetes는 Open vSwitch(OVS) 프로젝트에서 나온 가상 네트워킹 구현인 OVN(Open Virtual Network)을 기반으로 하는 쿠버네티스용 네트워킹 제공자이다. OVN-Kubernetes는 OVS 기반 로드 밸런싱과 네트워크 폴리시 구현을 포함하여 쿠버네티스용 오버레이 기반 네트워킹 구현을 제공한다.
- Nodus는 클라우드 네이티브 기반 서비스 기능 체인(SFC)을 제공하는 OVN 기반 CNI 컨트롤러 플러그인이다.
- NSX-T 컨테이너 플러그인(NCP)은 VMware NSX-T와 쿠버네티스와 같은 컨테이너 오케스트레이터 간의 통합은 물론 NSX-T와 PKS(Pivotal 컨테이너 서비스) 및 OpenShift와 같은 컨테이너 기반 CaaS/PaaS 플랫폼 간의 통합을 제공한다.
- Nuage는 가시성과 보안 모니터링 기능을 통해 쿠버네티스 파드와 비-쿠버네티스 환경 간에 폴리시 기반 네트워킹을 제공하는 SDN 플랫폼이다.
- Romana는 네트워크폴리시 API도 지원하는 파드 네트워크용 Layer 3 네트워킹 솔루션이다.
- Weave Net은 네트워킹 및 네트워크 폴리시를 제공하고, 네트워크 파티션의 양면에서 작업을 수행하며, 외부 데이터베이스는 필요하지 않다.
서비스 검색
- CoreDNS는 유연하고 확장 가능한 DNS 서버로, 파드를 위한 클러스터 내 DNS로 설치할 수 있다.
시각화 & 제어
- 대시보드는 쿠버네티스를 위한 대시보드 웹 인터페이스이다.
인프라스트럭처
레거시 애드온
더 이상 사용되지 않는 cluster/addons 디렉터리에 다른 여러 애드온이 문서화되어 있다.
잘 관리된 것들이 여기에 연결되어 있어야 한다. PR을 환영한다!