This is the multi-page printable view of this section. Click here to print.
Overview
1 - Cos'è Kubernetes?
Questa pagina è una panoramica generale su Kubernetes.
Kubernetes è una piattaforma portatile, estensibile e open-source per la gestione di carichi di lavoro e servizi containerizzati, in grado di facilitare sia la configurazione dichiarativa che l'automazione. La piattaforma vanta un grande ecosistema in rapida crescita. Servizi, supporto e strumenti sono ampiamente disponibili nel mondo Kubernetes .
Il nome Kubernetes deriva dal greco, significa timoniere o pilota. Google ha reso open-source il progetto Kubernetes nel 2014. Kubernetes unisce oltre quindici anni di esperienza di Google nella gestione di carichi di lavoro di produzione su scala mondiale con le migliori idee e pratiche della comunità.
Facciamo un piccolo salto indietro
Diamo un'occhiata alla ragione per cui Kubernetes è così utile facendo un piccolo salto indietro nel tempo.

L'era del deployment tradizionale: All'inizio, le organizzazioni eseguivano applicazioni su server fisici. Non c'era modo di definire i limiti delle risorse per le applicazioni in un server fisico e questo ha causato non pochi problemi di allocazione delle risorse. Ad esempio, se più applicazioni vengono eseguite sullo stesso server fisico, si possono verificare casi in cui un'applicazione assorbe la maggior parte delle risorse e, di conseguenza, le altre applicazioni non hanno le prestazioni attese. Una soluzione per questo sarebbe di eseguire ogni applicazione su un server fisico diverso. Ma questa non è una soluzione ideale, dal momento che le risorse vengono sottoutilizzate, inoltre, questa pratica risulta essere costosa per le organizzazioni, le quali devono mantenere numerosi server fisici.
L'era del deployment virtualizzato: Come soluzione venne introdotta la virtualizzazione. Essa consente di eseguire più macchine virtuali (VM) su una singola CPU fisica. La virtualizzazione consente di isolare le applicazioni in più macchine virtuali e fornisce un livello di sicurezza superiore, dal momento che le informazioni di un'applicazione non sono liberamente accessibili da un'altra applicazione.
La virtualizzazione consente un migliore utilizzo delle risorse riducendo i costi per l'hardware, permette una migliore scalabilità, dato che un'applicazione può essere aggiunta o aggiornata facilmente, e ha molti altri vantaggi.
Ogni VM è una macchina completa che esegue tutti i componenti, compreso il proprio sistema operativo, sopra all'hardware virtualizzato.
L'era del deployment in container: I container sono simili alle macchine virtuali, ma presentano un modello di isolamento più leggero, condividendo il sistema operativo (OS) tra le applicazioni. Pertanto, i container sono considerati più leggeri. Analogamente a una macchina virtuale, un container dispone di una segregazione di filesystem, CPU, memoria, PID e altro ancora. Poiché sono disaccoppiati dall'infrastruttura sottostante, risultano portabili tra differenti cloud e diverse distribuzioni.
I container sono diventati popolari dal momento che offrono molteplici vantaggi, ad esempio:
- Creazione e distribuzione di applicazioni in modalità Agile: maggiore facilità ed efficienza nella creazione di immagini container rispetto all'uso di immagini VM.
- Adozione di pratiche per lo sviluppo/test/rilascio continuativo: consente la frequente creazione e la distribuzione di container image affidabili, dando la possibilità di fare rollback rapidi e semplici (grazie all'immutabilità dell'immagine stessa).
- Separazione delle fasi di Dev e Ops: le container image vengono prodotte al momento della compilazione dell'applicativo piuttosto che nel momento del rilascio, permettendo così di disaccoppiare le applicazioni dall'infrastruttura sottostante.
- L'osservabilità non riguarda solo le informazioni e le metriche del sistema operativo, ma anche lo stato di salute e altri segnali dalle applicazioni.
- Coerenza di ambiente tra sviluppo, test e produzione: i container funzionano allo stesso modo su un computer portatile come nel cloud.
- Portabilità tra cloud e sistemi operativi differenti: lo stesso container funziona su Ubuntu, RHEL, CoreOS, on-premise, nei più grandi cloud pubblici e da qualsiasi altra parte.
- Gestione incentrata sulle applicazioni: Aumenta il livello di astrazione dall'esecuzione di un sistema operativo su hardware virtualizzato all'esecuzione di un'applicazione su un sistema operativo utilizzando risorse logiche.
- Microservizi liberamente combinabili, distribuiti, ad alta scalabilità: le applicazioni sono suddivise in pezzi più piccoli e indipendenti che possono essere distribuite e gestite dinamicamente - niente stack monolitici che girano su una singola grande macchina.
- Isolamento delle risorse: le prestazioni delle applicazioni sono prevedibili.
- Utilizzo delle risorse: alta efficienza e densità.
Perché necessito di Kubernetes e cosa posso farci
I container sono un buon modo per distribuire ed eseguire le tue applicazioni. In un ambiente di produzione, è necessario gestire i container che eseguono le applicazioni e garantire che non si verifichino interruzioni dei servizi. Per esempio, se un container si interrompe, è necessario avviare un nuovo container. Non sarebbe più facile se questo comportamento fosse gestito direttamente da un sistema?
È proprio qui che Kubernetes viene in soccorso! Kubernetes ti fornisce un framework per far funzionare i sistemi distribuiti in modo resiliente. Kubernetes si occupa della scalabilità, failover, distribuzione delle tue applicazioni. Per esempio, Kubernetes può facilmente gestire i rilasci con modalità Canary deployment.
Kubernetes ti fornisce:
- Scoperta dei servizi e bilanciamento del carico Kubernetes può esporre un container usando un nome DNS o il suo indirizzo IP. Se il traffico verso un container è alto, Kubernetes è in grado di distribuire il traffico su più container in modo che il servizio rimanga stabile.
- Orchestrazione dello storage Kubernetes ti permette di montare automaticamente un sistema di archiviazione di vostra scelta, come per esempio storage locale, dischi forniti da cloud pubblici, e altro ancora.
- Rollout e rollback automatizzati Puoi utilizzare Kubernetes per descrivere lo stato desiderato per i propri container, e Kubernetes si occuperà di cambiare lo stato attuale per raggiungere quello desiderato ad una velocità controllata. Per esempio, puoi automatizzare Kubernetes per creare nuovi container per il tuo servizio, rimuovere i container esistenti e adattare le loro risorse a quelle richieste dal nuovo container.
- Ottimizzazione dei carichi Fornisci a Kubernetes un cluster di nodi per eseguire i container. Puoi istruire Kubernetes su quanta CPU e memoria (RAM) ha bisogno ogni singolo container. Kubernetes allocherà i container sui nodi per massimizzare l'uso delle risorse a disposizione.
- Self-healing Kubernetes riavvia i container che si bloccano, sostituisce container, termina i container che non rispondono agli health checks, e evita di far arrivare traffico ai container che non sono ancora pronti per rispondere correttamente.
- Gestione di informazioni sensibili e della configurazione Kubernetes consente di memorizzare e gestire informazioni sensibili, come le password, i token OAuth e le chiavi SSH. Puoi distribuire e aggiornare le informazioni sensibili e la configurazione dell'applicazione senza dover ricostruire le immagini dei container e senza svelare le informazioni sensibili nella configurazione del tuo sistema.
Cosa non è Kubernetes
Kubernetes non è un sistema PaaS (Platform as a Service) tradizionale e completo. Dal momento che Kubernetes opera a livello di container piuttosto che che a livello hardware, esso fornisce alcune caratteristiche generalmente disponibili nelle offerte PaaS, come la distribuzione, il ridimensionamento, il bilanciamento del carico, la registrazione e il monitoraggio. Tuttavia, Kubernetes non è monolitico, e queste soluzioni predefinite sono opzionali ed estensibili. Kubernetes fornisce gli elementi base per la costruzione di piattaforme di sviluppo, ma conserva le scelte dell'utente e la flessibilità dove è importante.
Kubernetes:
- Non limita i tipi di applicazioni supportate. Kubernetes mira a supportare una grande varietà di carichi di lavoro, compresi i carichi di lavoro stateless, stateful e elaborazione di dati. Se un'applicazione può essere eseguita in un container, dovrebbe funzionare alla grande anche su Kubernetes.
- Non compila il codice sorgente e non crea i container. I flussi di Continuous Integration, Delivery, and Deployment (CI/CD) sono determinati dalla cultura e dalle preferenze dell'organizzazione e dai requisiti tecnici.
- Non fornisce servizi a livello applicativo, come middleware (per esempio, bus di messaggi), framework di elaborazione dati (per esempio, Spark), database (per esempio, mysql), cache, né sistemi di storage distribuito (per esempio, Ceph) come servizi integrati. Tali componenti possono essere eseguiti su Kubernetes, e/o possono essere richiamati da applicazioni che girano su Kubernetes attraverso meccanismi come l'Open Service Broker.
- Non impone soluzioni di logging, monitoraggio o di gestione degli alert. Fornisce alcune integrazioni come dimostrazione, e meccanismi per raccogliere ed esportare le metriche.
- Non fornisce né rende obbligatorio un linguaggio/sistema di configurazione (per esempio, Jsonnet). Fornisce un'API dichiarativa che può essere richiamata da qualsiasi sistema.
- Non fornisce né adotta alcun sistema di gestione completa della macchina, configurazione, manutenzione, gestione o sistemi di self healing.
- Inoltre, Kubernetes non è un semplice sistema di orchestrazione. Infatti, questo sistema elimina la necessità di orchestrazione. La definizione tecnica di orchestrazione è l'esecuzione di un flusso di lavoro definito: prima si fa A, poi B, poi C. Al contrario, Kubernetes è composto da un insieme di processi di controllo indipendenti e componibili che guidano costantemente lo stato attuale verso lo stato desiderato. Non dovrebbe importare come si passa dalla A alla C. Anche il controllo centralizzato non è richiesto. Questo si traduce in un sistema più facile da usare, più potente, robusto, resiliente ed estensibile.
Voci correlate
- Dai un'occhiata alla pagina i componenti di Kubernetes
- Sai già Come Iniziare?
2 - I componenti di Kubernetes
Facendo il deployment di Kubernetes, ottieni un cluster.
Un cluster Kubernetes è un'insieme di macchine, chiamate nodi, che eseguono container gestiti da Kubernetes. Un cluster ha almeno un Worker Node.
Il/I Worker Node ospitano i Pod che eseguono i workload dell'utente. Il/I Control Plane Node gestiscono i Worker Node e tutto quanto accade all'interno del cluster. Per garantire la high-availability e la possibilità di failover del cluster, vengono utilizzati più Control Plane Node.
Questo documento descrive i diversi componenti che sono necessari per avere un cluster Kubernetes completo e funzionante.
Questo è un diagramma di un cluster Kubernetes con tutti i componenti e le loro relazioni.
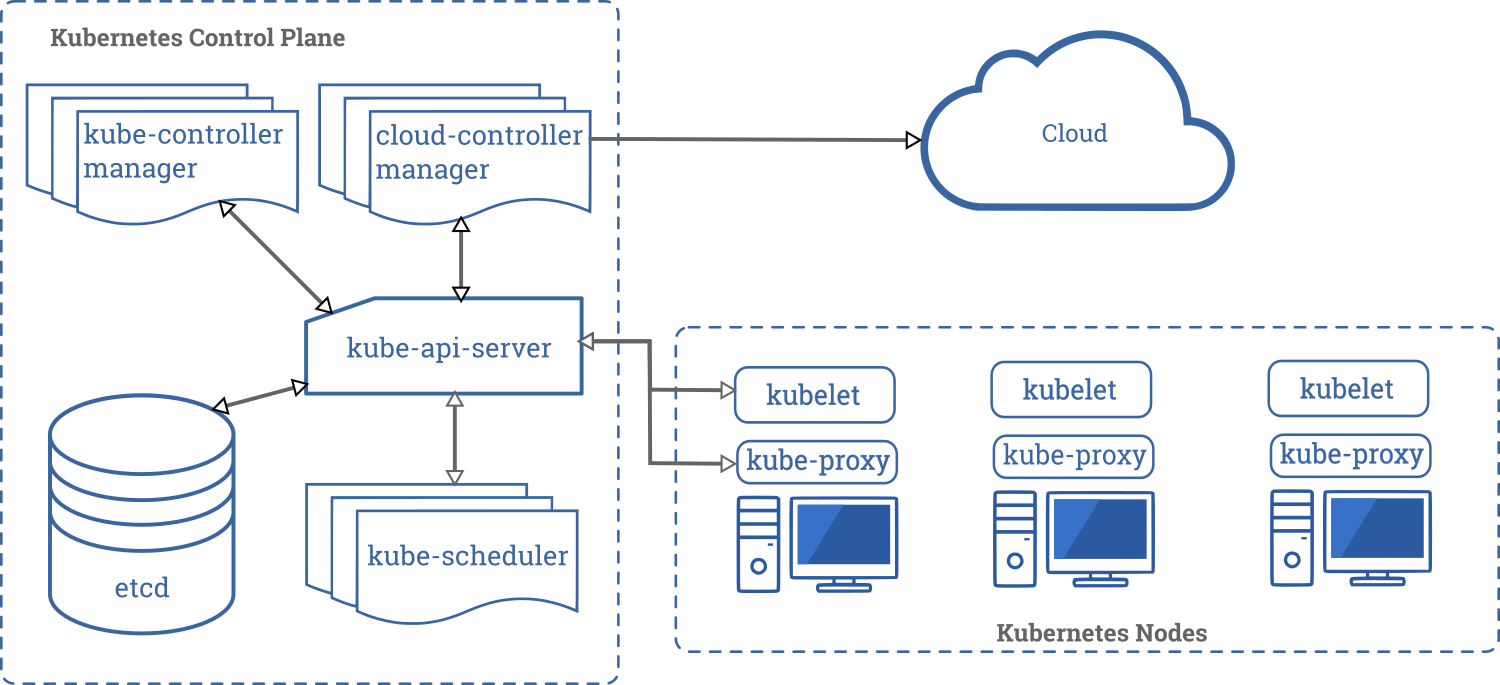
Componenti della Control Plane
I componenti del Control Plane sono responsabili di tutte le decisioni globali sul cluster (ad esempio, lo scheduling) oltre che a rilevare e rispondere agli eventi del cluster (ad esempio, l'avvio di un nuovo pod quando il valore replicas di un deployment non è soddisfatto).
I componenti della Control Plane possono essere eseguiti su qualsiasi nodo del cluster stesso. Solitamente, per semplicità, gli script di installazione tendono a eseguire tutti i componenti della Control Plane sulla stessa macchina, separando la Control Plane dai workload dell'utente. Vedi creare un cluster in High-Availability per un esempio di un'installazione multi-master.
kube-apiserver
L'API server è un componente di Kubernetes control plane che espone le Kubernetes API. L'API server è il front end del control plane di Kubernetes.
La principale implementazione di un server Kubernetes API è kube-apiserver. kube-apiserver è progettato per scalare orizzontalmente, cioè scala aumentando il numero di istanze. Puoi eseguire multiple istanze di kube-apiserver e bilanciare il traffico tra queste istanze.
etcd
È un database key-value ridondato, che è usato da Kubernetes per salvare tutte le informazioni del cluster.
Se il tuo cluster utilizza etcd per salvare le informazioni, assicurati di avere una strategia di backup per questi dati.
Puoi trovare informazioni dettagliate su etcd sulla documentazione ufficiale.
kube-scheduler
Componente della Control Plane che controlla i pod appena creati che non hanno un nodo assegnato, e dopo averlo identificato glielo assegna.
I fattori presi in considerazioni nell'individuare un nodo a cui assegnare l'esecuzione di un Pod includono la richiesta di risorse del Pod stesso e degli altri workload presenti nel sistema, i vincoli delle hardware/software/policy, le indicazioni di affinity e di anti-affinity, requisiti relativi alla disponibilità di dati/Volumes, le interferenze tra diversi workload e le scadenze.
kube-controller-manager
Componente della Control Plane che gestisce controllers.
Da un punto di vista logico, ogni controller è un processo separato, ma per ridurre la complessità, tutti i principali controller di Kubernetes vengono raggruppati in un unico container ed eseguiti in un singolo processo.
Alcuni esempi di controller gestiti dal kube-controller-manager sono:
- Node Controller: Responsabile del monitoraggio dei nodi del cluster, e.g. della gestione delle azioni da eseguire quando un nodo diventa non disponibile.
- Replication Controller: Responsabile per il mantenimento del corretto numero di Pod per ogni ReplicaSet presente nel sistema
- Endpoints Controller: Popola gli oggetti Endpoints (cioè, mette in relazioni i Pods con i Services).
- Service Account & Token Controllers: Creano gli account di default e i token di accesso alle API per i nuovi namespaces.
cloud-controller-manager
Un componente della control plane di Kubernetes che aggiunge logiche di controllo specifiche per il cloud. Il cloud-controller-manager ti permette di collegare il tuo cluster con le API del cloud provider e separa le componenti che interagiscono con la piattaforma cloud dai componenti che interagiscono solamente col cluster.Il cloud-controller-manager esegue dei controller specifici del tuo cloud provider. Se hai una installazione Kubernetes on premises, o un ambiente di laboratorio nel tuo PC, il cluster non ha un cloud-controller-manager.
Come nel kube-controller-manager, il cloud-controller-manager combina diversi control loop logicamente indipendenti in un singolo binario che puoi eseguire come un singolo processo. Tu puoi scalare orizzontalmente (eseguire più di una copia) per migliorare la responsività o per migliorare la tolleranza ai fallimenti.
I seguenti controller hanno dipendenze verso implementazioni di specifici cloud provider:
- Node Controller: Per controllare se sul cloud provider i nodi che hanno smesso di rispondere sono stati cancellati
- Route Controller: Per configurare le network route nella sottostante infrastruttura cloud
- Service Controller: Per creare, aggiornare ed eliminare i load balancer del cloud provider
Componenti dei Nodi
I componenti del nodo vengono eseguiti su ogni nodo, mantenendo i pod in esecuzione e fornendo l'ambiente di runtime Kubernetes.
kubelet
Un agente che è eseguito su ogni nodo del cluster. Si assicura che i container siano eseguiti in un pod.
La kubelet riceve un set di PodSpecs che vengono forniti attraverso vari meccanismi, e si assicura che i container descritti in questi PodSpecs funzionino correttamente e siano sani. La kubelet non gestisce i container che non sono stati creati da Kubernetes.
kube-proxy
kube-proxy è un proxy eseguito su ogni nodo del cluster, responsabile della gestione dei Kubernetes Service.
I kube-proxy mantengono le regole di networking sui nodi. Queste regole permettono la comunicazione verso gli altri nodi del cluster o l'esterno.
Il kube-proxy usa le librerie del sistema operativo quando possible; in caso contrario il kube-proxy gestisce il traffico direttamente.
Container Runtime
Il container runtime è il software che è responsabile per l'esecuzione dei container.
Kubernetes supporta diversi container runtimes: Docker, containerd, cri-o, rktlet e tutte le implementazioni di Kubernetes CRI (Container Runtime Interface).
Addons
Gli Addons usano le risorse Kubernetes (DaemonSet, Deployment, etc) per implementare funzionalità di cluster.
Dal momento che gli addons forniscono funzionalità a livello di cluster, le risorse che necessitano di un namespace, vengono collocate nel namespace kube-system.
Alcuni addons sono descritti di seguito; mentre per una più estesa lista di addons, per favore vedere Addons.
DNS
Mentre gli altri addons non sono strettamente richiesti, tutti i cluster Kubernetes dovrebbero essere muniti di un DNS del cluster, dal momento che molte applicazioni lo necessitano.
Il DNS del cluster è un server DNS aggiuntivo rispetto ad altri server DNS presenti nella rete, e si occupa specificatamente dei record DNS per i servizi Kubernetes.
I container eseguiti da Kubernetes automaticamente usano questo server per la risoluzione DNS.
Interfaccia web (Dashboard)
La Dashboard è una interfaccia web per i cluster Kubernetes. Permette agli utenti di gestire e fare troubleshooting delle applicazioni che girano nel cluster, e del cluster stesso.
Monitoraggio dei Container
Il Monitoraggio dei Container salva serie temporali di metriche generiche dei container in un database centrale e fornisce una interfaccia in cui navigare i dati stessi.
Log a livello di Cluster
Un log a livello di cluster è responsabile per il salvataggio dei log dei container in un log centralizzato la cui interfaccia permette di cercare e navigare nei log.
Voci correlate
- Scopri i concetti relativi ai Nodi
- Scopri i concetti relativi ai Controller
- Scopri i concetti relativi al kube-scheduler
- Leggi la documentazione ufficiale di etcd
3 - Le API di Kubernetes
Le convenzioni generali seguite dalle API sono descritte in API conventions doc.
Gli endpoints delle API, la lista delle risorse esposte ed i relativi esempi sono descritti in API Reference.
L'accesso alle API da remoto è discusso in Controllare l'accesso alle API.
Le API di Kubernetes servono anche come riferimento per lo schema dichiarativo della configurazione del sistema stesso. Il comando kubectl può essere usato per creare, aggiornare, cancellare ed ottenere le istanze delle risorse esposte attraverso le API.
Kubernetes assicura la persistenza del suo stato (al momento in etcd) usando la rappresentazione delle risorse implementata dalle API.
Kubernetes stesso è diviso in differenti componenti, i quali interagiscono tra loro attraverso le stesse API.
Evoluzione delle API
In base alla nostra esperienza, ogni sistema di successo ha bisogno di evolvere ovvero deve estendersi aggiungendo funzionalità o modificare le esistenti per adattarle a nuovi casi d'uso. Le API di Kubernetes sono quindi destinate a cambiare e ad estendersi. In generale, ci si deve aspettare che nuove risorse vengano aggiunte di frequente cosi come nuovi campi possano altresì essere aggiunti a risorse esistenti. L'eliminazione di risorse o di campi devono seguire la politica di deprecazione delle API.
In cosa consiste una modifica compatibile e come modificare le API è descritto dal API change document.
Definizioni OpenAPI e Swagger
La documentazione completa e dettagliata delle API è fornita attraverso la specifica OpenAPI.
Dalla versione 1.10 di Kubernetes, l'API server di Kubernetes espone le specifiche OpenAPI attraverso il seguente endpoint /openapi/v2. Attraverso i seguenti headers HTTP è possibile richiedere un formato specifico:
| Header | Possibili Valori |
|---|---|
| Accept | application/json, application/[email protected]+protobuf (il content-type di default è application/json per */* ovvero questo header può anche essere omesso) |
| Accept-Encoding | gzip (questo header è facoltativo) |
Prima della versione 1.14, gli endpoints che includono il formato del nome all'interno del segmento (/swagger.json, /swagger-2.0.0.json, /swagger-2.0.0.pb-v1, /swagger-2.0.0.pb-v1.gz)
espongo le specifiche OpenAPI in formati differenti. Questi endpoints sono deprecati, e saranno rimossi dalla versione 1.14 di Kubernetes.
Esempi per ottenere le specifiche OpenAPI:
| Prima della 1.10 | Dalla versione 1.10 di Kubernetes |
|---|---|
| GET /swagger.json | GET /openapi/v2 Accept: application/json |
| GET /swagger-2.0.0.pb-v1 | GET /openapi/v2 Accept: application/[email protected]+protobuf |
| GET /swagger-2.0.0.pb-v1.gz | GET /openapi/v2 Accept: application/[email protected]+protobuf Accept-Encoding: gzip |
Kubernetes implementa per le sue API anche una serializzazione alternativa basata sul formato Protobuf che è stato pensato principalmente per la comunicazione intra-cluster, documentato nella seguente design proposal, e i files IDL per ciascun schema si trovano nei Go packages che definisco i tipi delle API.
Prima della versione 1.14, l'apiserver di Kubernetes espone anche un'endpoint, /swaggerapi, che può essere usato per ottenere
le documentazione per le API di Kubernetes secondo le specifiche Swagger v1.2 .
Questo endpoint è deprecato, ed è stato rimosso nella versione 1.14 di Kubernetes.
Versionamento delle API
Per facilitare l'eliminazione di campi specifici o la modifica della rappresentazione di una data risorsa, Kubernetes supporta molteplici versioni della stessa API disponibili attraverso differenti indirizzi, come ad esempio /api/v1 oppure
/apis/extensions/v1beta1.
Abbiamo deciso di versionare a livello di API piuttosto che a livello di risorsa o di campo per assicurare che una data API rappresenti una chiara, consistente vista delle risorse di sistema e dei sui comportamenti, e per abilitare un controllo degli accessi sia per le API in via di decommissionamento che per quelle sperimentali.
Si noti che il versionamento delle API ed il versionamento del Software sono indirettamente collegati. La API and release versioning proposal descrive la relazione tra le versioni delle API ed le versioni del Software.
Differenti versioni delle API implicano differenti livelli di stabilità e supporto. I criteri per ciascuno livello sono descritti in dettaglio nella API Changes documentation. Queste modifiche sono qui ricapitolate:
- Livello alpha:
- Il nome di versione contiene
alpha(e.g.v1alpha1). - Potrebbe contenere dei bug. Abilitare questa funzionalità potrebbe esporre al rischio di bugs. Disabilitata di default.
- Il supporto di questa funzionalità potrebbe essere rimosso in ogni momento senza previa notifica.
- Questa API potrebbe cambiare in modo incompatibile in rilasci futuri del Software e senza previa notifica.
- Se ne raccomandata l'utilizzo solo in clusters di test creati per un breve periodo di vita, a causa di potenziali bugs e delle mancanza di un supporto di lungo periodo.
- Il nome di versione contiene
- Livello beta:
- Il nome di versione contiene
beta(e.g.v2beta3). - Il codice è propriamente testato. Abilitare la funzionalità è considerato sicuro. Abilitata di default.
- Il supporto per la funzionalità nel suo complesso non sarà rimosso, tuttavia potrebbe subire delle modifiche.
- Lo schema e/o la semantica delle risorse potrebbe cambiare in modo incompatibile in successivi rilasci beta o stabili. Nel caso questo dovesse verificarsi, verrano fornite istruzioni per la migrazione alla versione successiva. Questo potrebbe richiedere la cancellazione, modifica, e la ri-creazione degli oggetti supportati da questa API. Questo processo di modifica potrebbe richiedere delle valutazioni. La modifica potrebbe richiedere un periodo di non disponibilità dell'applicazione che utilizza questa funzionalità.
- Raccomandata solo per applicazioni non critiche per la vostra impresa a causa dei potenziali cambiamenti incompatibili in rilasci successivi. Se avete più clusters che possono essere aggiornati separatamente, potreste essere in grado di gestire meglio questa limitazione.
- Per favore utilizzate le nostre versioni beta e forniteci riscontri relativamente ad esse! Una volta promosse a stabili, potrebbe non essere semplice apportare cambiamenti successivi.
- Il nome di versione contiene
- Livello stabile:
- Il nome di versione è
vXdoveXè un intero. - Le funzionalità relative alle versioni stabili continueranno ad essere presenti per parecchie versioni successive.
- Il nome di versione è
API groups
Per facilitare l'estendibilità delle API di Kubernetes, sono stati implementati gli API groups.
L'API group è specificato nel percorso REST ed anche nel campo apiVersion di un oggetto serializzato.
Al momento ci sono diversi API groups in uso:
Il gruppo core, spesso referenziato come il legacy group, è disponibile al percorso REST
/api/v1ed utilizzaapiVersion: v1.I gruppi basati su un nome specifico sono disponibili attraverso il percorso REST
/apis/$GROUP_NAME/$VERSION, ed usanoapiVersion: $GROUP_NAME/$VERSION(e.g.apiVersion: batch/v1). La lista completa degli API groups supportati e' descritta nel documento Kubernetes API reference.
Vi sono due modi per supportati per estendere le API attraverso le custom resources:
- CustomResourceDefinition è pensato per utenti con esigenze CRUD basilari.
- Utenti che necessitano di un nuovo completo set di API che utilizzi appieno la semantica di Kubernetes possono implementare il loro apiserver ed utilizzare l'aggregator per fornire ai propri utilizzatori la stessa esperienza a cui sono abituati con le API incluse nativamente in Kubernetes.
Abilitare o disabilitare gli API groups
Alcune risorse ed API groups sono abilitati di default. Questi posso essere abilitati o disabilitati attraverso il settaggio/flag --runtime-config
applicato sull'apiserver. --runtime-config accetta valori separati da virgola. Per esempio: per disabilitare batch/v1, usa la seguente configurazione --runtime-config=batch/v1=false, per abilitare batch/v2alpha1, utilizzate --runtime-config=batch/v2alpha1.
Il flag accetta set di coppie chiave/valore separati da virgola che descrivono la configurazione a runtime dell'apiserver.
Nota:
Abilitare o disabilitare risorse o gruppi richiede il riavvio dell'apiserver e del controller-manager affinché le modifiche specificate attraverso il flag--runtime-config abbiano effetto.Abilitare specifiche risorse nel gruppo extensions/v1beta1
DaemonSets, Deployments, StatefulSet, NetworkPolicies, PodSecurityPolicies e ReplicaSets presenti nel gruppo di API extensions/v1beta1 sono disabilitate di default.
Per esempio: per abilitare deployments and daemonsets, utilizza la seguente configurazione
--runtime-config=extensions/v1beta1/deployments=true,extensions/v1beta1/daemonsets=true.
Nota:
Abilitare/disabilitare una singola risorsa è supportato solo per il gruppo di APIextensions/v1beta1 per ragioni storiche.